Performs Latent Class Analysis (LCA) on binary response data using the Expectation-Maximization (EM) algorithm. LCA identifies unobserved (latent) subgroups of examinees with similar response patterns, and estimates both the class characteristics and individual membership probabilities.
Usage
LCA(
U,
ncls = 2,
na = NULL,
Z = NULL,
w = NULL,
maxiter = 100,
verbose = FALSE,
beta1 = 1,
beta2 = 1,
conf = NULL
)Arguments
- U
Either an object of class "exametrika" or raw data. When raw data is given, it is converted to the exametrika class with the
dataFormatfunction.- ncls
Number of latent classes to identify (between 2 and 20). Default is 2.
- na
Values to be treated as missing values.
- Z
Missing indicator matrix of type matrix or data.frame. Values of 1 indicate observed responses, while 0 indicates missing data.
- w
Item weight vector specifying the relative importance of each item.
- maxiter
Maximum number of EM algorithm iterations. Default is 100.
- verbose
Logical; if TRUE, displays progress during estimation. Default is FALSE.
- beta1
Beta distribution parameter 1 for prior density of class reference matrix. Default is 1.
- beta2
Beta distribution parameter 2 for prior density of class reference matrix. Default is 1.
- conf
Confirmatory IRP matrix (items x ncls) for test equating. Same format as the IRP output. Non-NA values are fixed throughout estimation, NA values are freely estimated. Fixed values must be in the open interval (0, 1). When row names are present, items are matched by label; otherwise by position. Default is NULL (fully exploratory).
Value
An object of class "exametrika" and "LCA" containing:
- msg
A character string indicating the model type.
- testlength
Length of the test (number of items).
- nobs
Sample size (number of rows in the dataset).
- Nclass
Number of latent classes specified.
- N_Cycle
Number of EM algorithm iterations performed.
- converge
Logical value indicating whether the algorithm converged within maxiter iterations
- TRP
Test Reference Profile vector showing expected scores for each latent class. Calculated as the column sum of the estimated class reference matrix.
- LCD
Latent Class Distribution vector showing the number of examinees assigned to each latent class.
- CMD
Class Membership Distribution vector showing the sum of membership probabilities for each latent class.
- Students
Class Membership Profile matrix showing the posterior probability of each examinee belonging to each latent class. The last column ("Estimate") indicates the most likely class assignment.
- IRP
Item Reference Profile matrix where each row represents an item and each column represents a latent class. Values indicate the probability of a correct response for members of that class.
- ItemFitIndices
Fit indices for each item. See also
ItemFit.- TestFitIndices
Overall fit indices for the test. See also
TestFit.
Details
Latent Class Analysis is a statistical method for identifying unobserved subgroups within a population based on observed response patterns. It assumes that examinees belong to one of several distinct latent classes, and that the probability of a correct response to each item depends on class membership.
The algorithm proceeds by:
Initializing class reference probabilities
Computing posterior class membership probabilities for each examinee (E-step)
Re-estimating class reference probabilities based on these memberships (M-step)
Iterating until convergence or reaching the maximum number of iterations
Unlike Item Response Theory (IRT), LCA treats latent variables as categorical rather than continuous, identifying distinct profiles rather than positions on a continuum.
References
Goodman, L. A. (1974). Exploratory latent structure analysis using both identifiable and unidentifiable models. Biometrika, 61(2), 215-231.
Lazarsfeld, P. F., & Henry, N. W. (1968). Latent structure analysis. Boston: Houghton Mifflin.
Examples
# \donttest{
# Fit a Latent Class Analysis model with 5 classes to the sample dataset
result.LCA <- LCA(J15S500, ncls = 5)
# Display the first few rows of student class membership probabilities
head(result.LCA$Students)
#> Membership 1 Membership 2 Membership 3 Membership 4 Membership 5
#> Student001 0.7839477684 0.171152798 0.004141844 4.075759e-02 3.744590e-12
#> Student002 0.0347378747 0.051502214 0.836022799 7.773694e-02 1.698776e-07
#> Student003 0.0146307878 0.105488644 0.801853496 3.343026e-02 4.459682e-02
#> Student004 0.0017251650 0.023436459 0.329648386 3.656488e-01 2.795412e-01
#> Student005 0.2133830569 0.784162066 0.001484616 2.492073e-08 9.702355e-04
#> Student006 0.0003846482 0.001141448 0.001288901 8.733869e-01 1.237981e-01
#> Estimate
#> Student001 1
#> Student002 3
#> Student003 3
#> Student004 4
#> Student005 2
#> Student006 4
# Plot Item Response Profiles (IRP) for items 1-6 in a 2x3 grid
# Shows probability of correct response for each item across classes
plot(result.LCA, type = "IRP", items = 1:6, nc = 2, nr = 3)
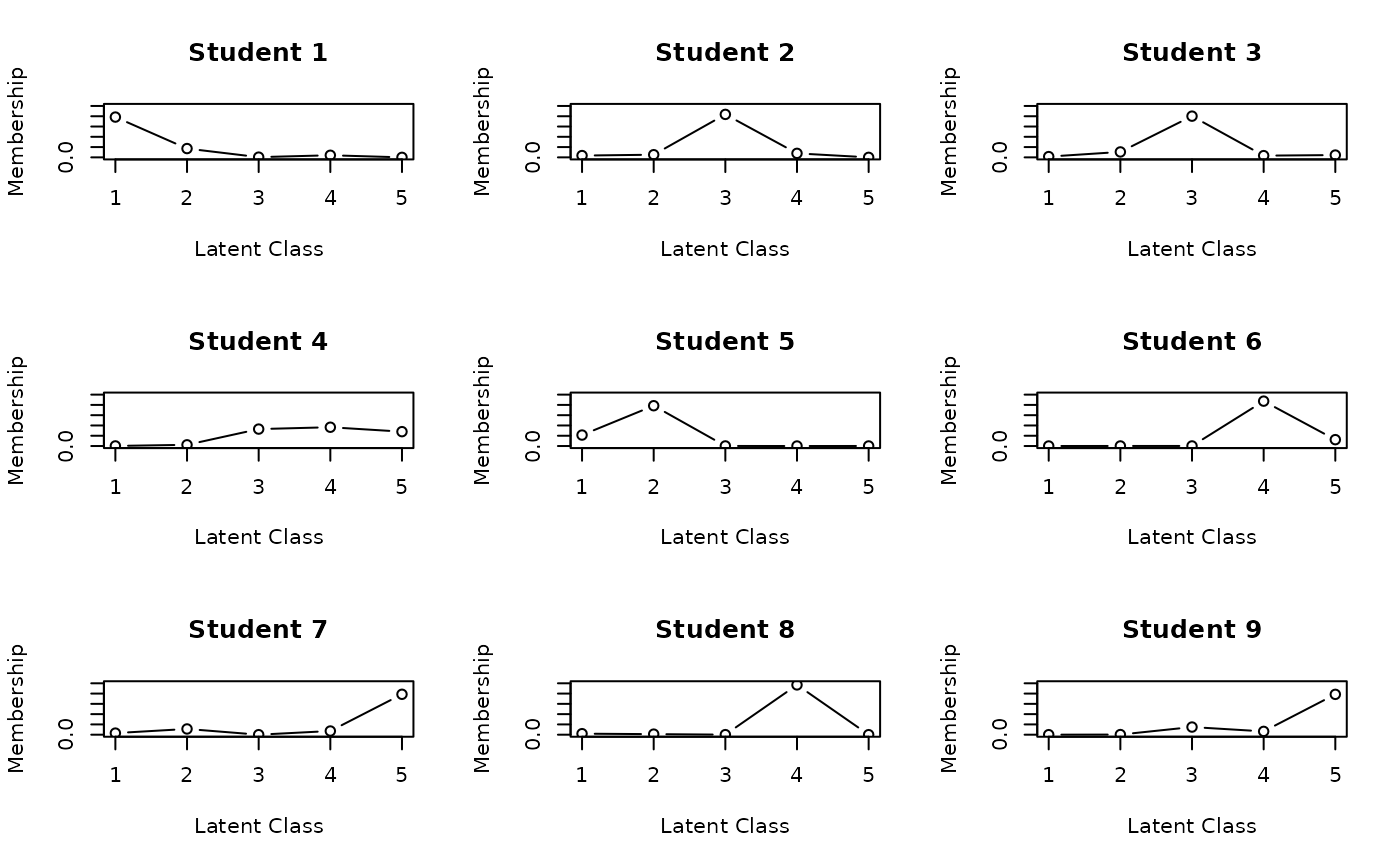
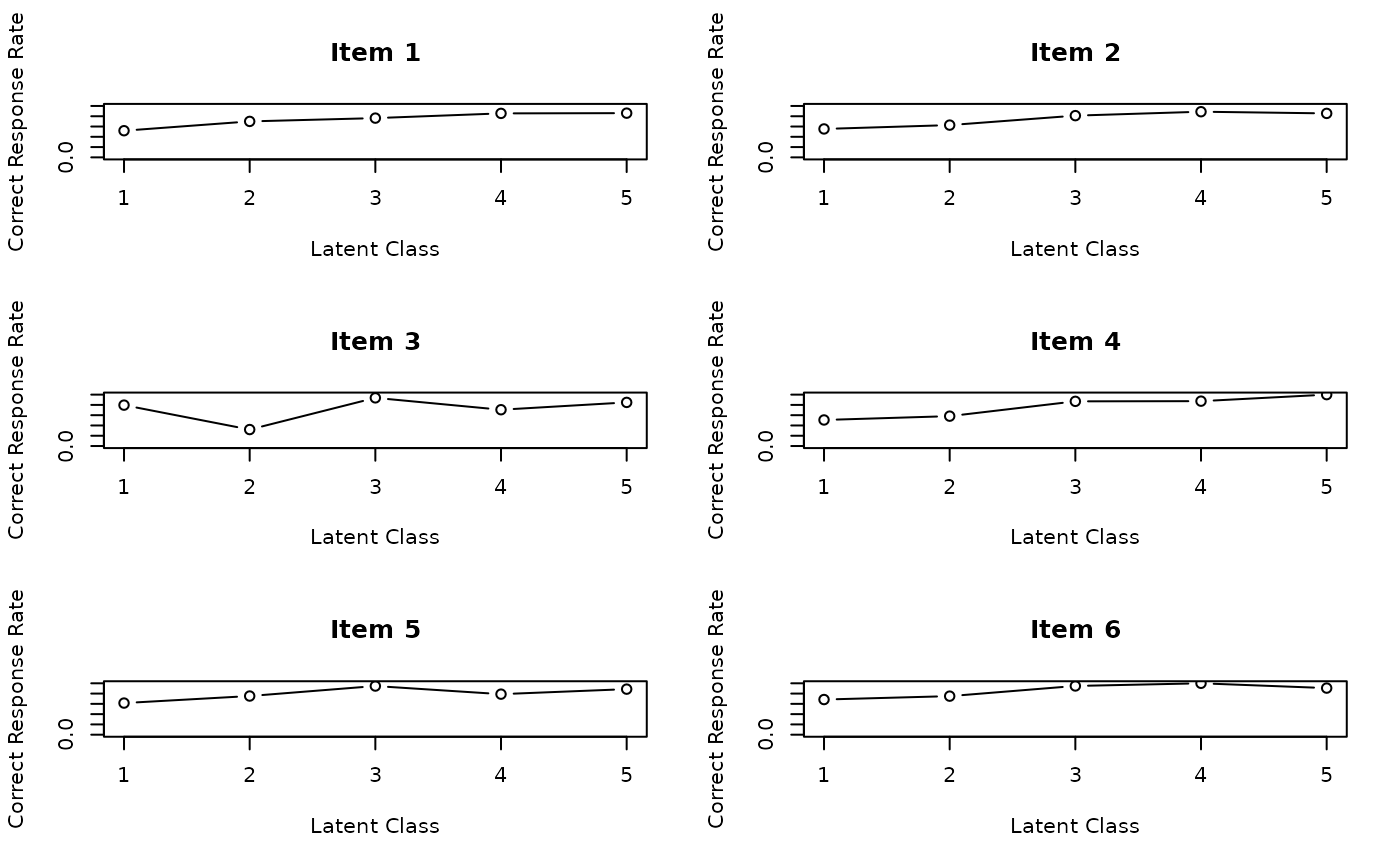 # Plot Class Membership Probabilities (CMP) for students 1-9 in a 3x3 grid
# Shows probability distribution of class membership for each student
plot(result.LCA, type = "CMP", students = 1:9, nc = 3, nr = 3)
# Plot Class Membership Probabilities (CMP) for students 1-9 in a 3x3 grid
# Shows probability distribution of class membership for each student
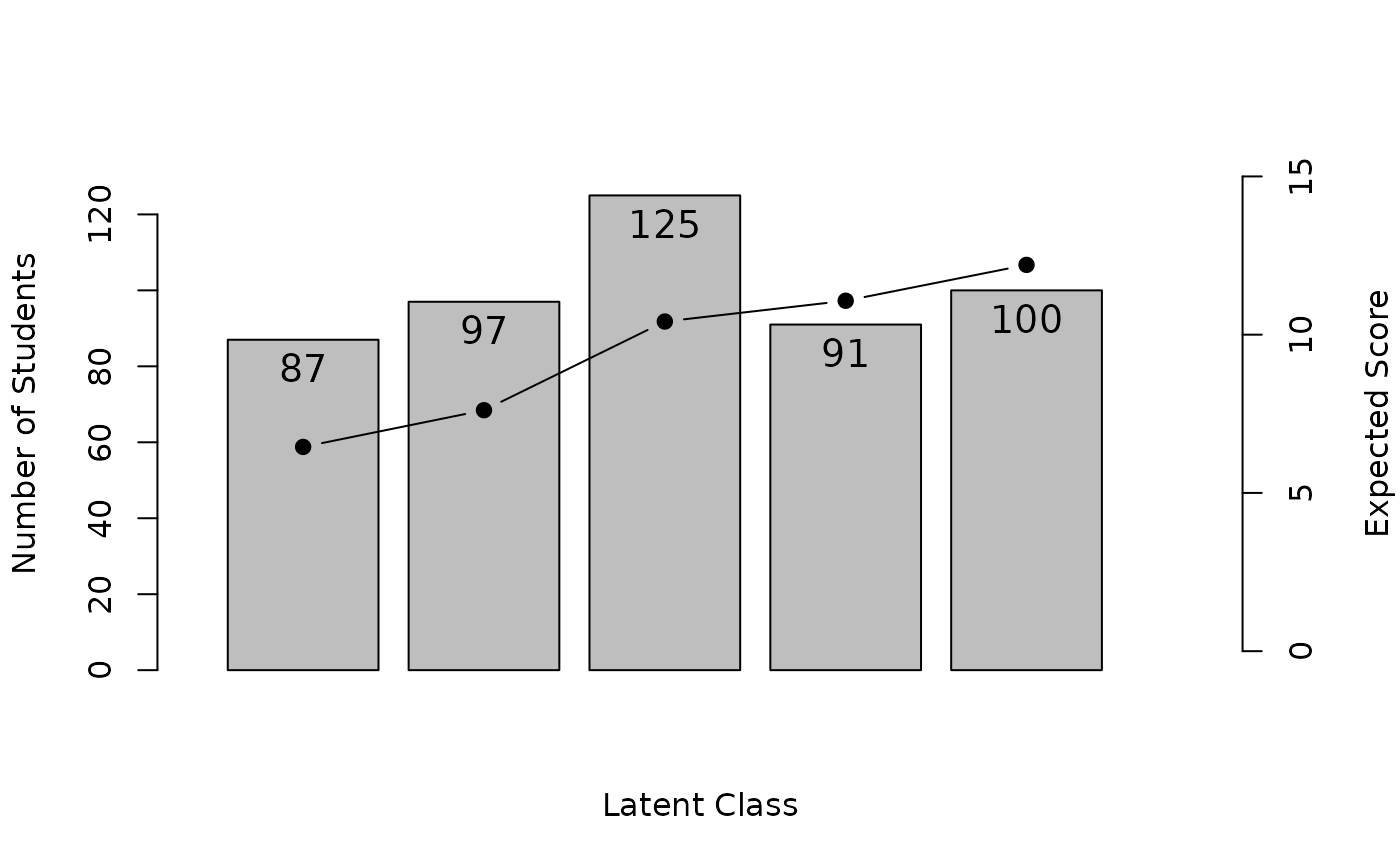
plot(result.LCA, type = "CMP", students = 1:9, nc = 3, nr = 3)
 # Plot Test Response Profile (TRP) showing expected scores for each class
plot(result.LCA, type = "TRP")
# Plot Test Response Profile (TRP) showing expected scores for each class
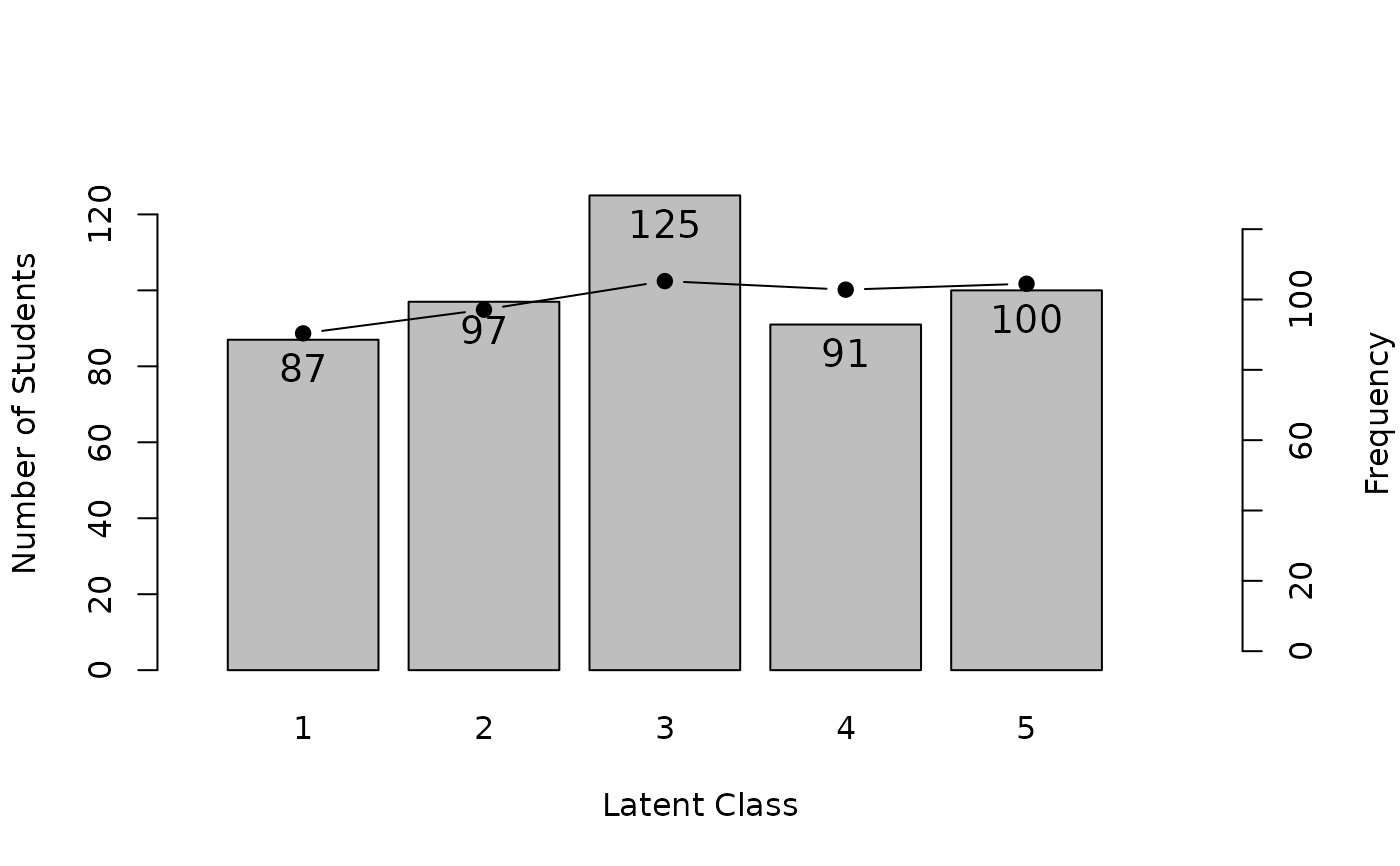
plot(result.LCA, type = "TRP")
 # Plot Latent Class Distribution (LCD) showing class sizes
plot(result.LCA, type = "LCD")
# Plot Latent Class Distribution (LCD) showing class sizes
plot(result.LCA, type = "LCD")
 # Compare models with different numbers of classes
# (In practice, you might try more class counts)
lca2 <- LCA(J15S500, ncls = 2)
lca3 <- LCA(J15S500, ncls = 3)
lca4 <- LCA(J15S500, ncls = 4)
lca5 <- LCA(J15S500, ncls = 5)
# Compare BIC values to select optimal number of classes
# (Lower BIC indicates better fit)
data.frame(
Classes = 2:5,
BIC = c(
lca2$TestFitIndices$BIC,
lca3$TestFitIndices$BIC,
lca4$TestFitIndices$BIC,
lca5$TestFitIndices$BIC
)
)
#> Classes BIC
#> 1 2 -349.9323
#> 2 3 -461.9099
#> 3 4 -557.2459
#> 4 5 -630.9953
# }
# Compare models with different numbers of classes
# (In practice, you might try more class counts)
lca2 <- LCA(J15S500, ncls = 2)
lca3 <- LCA(J15S500, ncls = 3)
lca4 <- LCA(J15S500, ncls = 4)
lca5 <- LCA(J15S500, ncls = 5)
# Compare BIC values to select optimal number of classes
# (Lower BIC indicates better fit)
data.frame(
Classes = 2:5,
BIC = c(
lca2$TestFitIndices$BIC,
lca3$TestFitIndices$BIC,
lca4$TestFitIndices$BIC,
lca5$TestFitIndices$BIC
)
)
#> Classes BIC
#> 1 2 -349.9323
#> 2 3 -461.9099
#> 3 4 -557.2459
#> 4 5 -630.9953
# }