pacman::p_load(tidyverse, psych)
dat <- psych::bfi |> select(-gender, -education, -age)
# parallel analysis
fa.parallel(dat)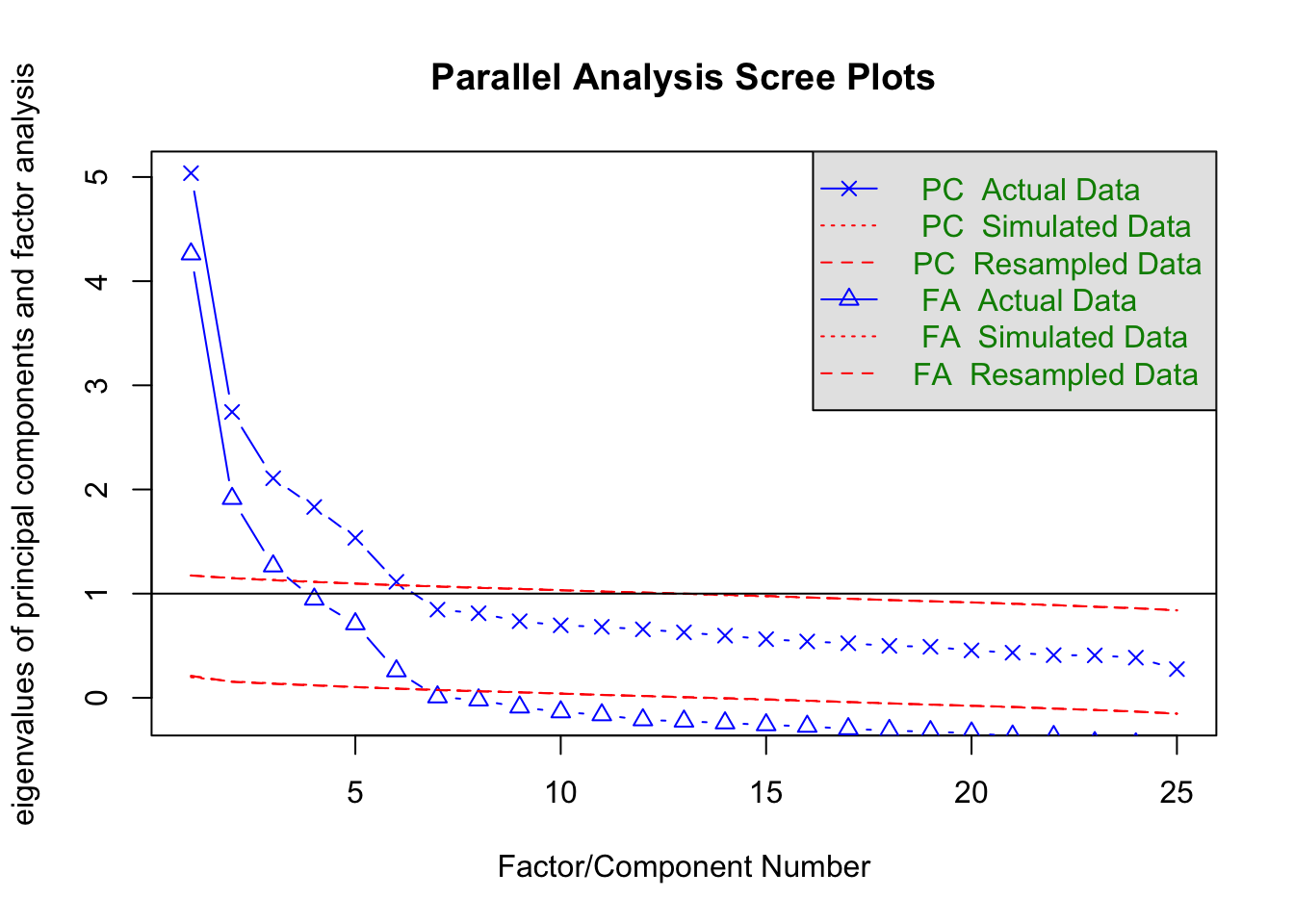
Parallel analysis suggests that the number of factors = 6 and the number of components = 6 In this chapter we survey multivariate analysis with an emphasis on factor analysis — the technique most heavily used in psychological research.
As the name suggests, multivariate analysis concerns datasets with many variables, and its principal aim is information summarization. Interpreting each variable individually when many are present is laborious; a well-chosen summary buys considerable insight at modest cost.
From that aim several substantive interpretations follow. Below we list the main interpretive flavours and the analytic techniques that correspond to them.
The essential common feature is discovering inter-variable relationships from data. The relationships are expressed in different ways, with corresponding differences in technique. Most often we use covariances (correlations) as the measure of relationship; this presupposes data at the interval level or higher. For ordinal data, polychoric or polyserial correlations replace Pearson; for binary data, tetrachoric correlations.
Inter-variable relationships are not limited to correlations. For categorical variables one can use the co-frequency of joint category occurrence as the relational index. Co-frequency techniques include dual scaling (西里 2010) (mathematically equivalent to correspondence analysis and Hayashi’s Quantification Method Type III). Such categorical analyses are applied, for instance, in text mining of free responses after morphological analysis.
Relationships can also be expressed as distances (i.e., similarities) between variables. When the data satisfy the distance axioms, they can be visualized by multidimensional scaling (高根 1980; 岡太 and 今泉 1994) or grouped by cluster analysis (新納 2007; 足立 2006).
Correlation captures the strength of a straight-line relationship between two variables but can also reflect spurious associations driven by a hidden third variable. The partial correlation controls for surrounding variables; this is the foundation of graphical modeling (宮川 1997) and network analysis (アデラ=マリア et al. [2022] 2024).
In any case, given inter-variable relationships, an external criterion (if available) is fitted to estimate unknowns, and without one, the data are structured by model-based assumptions. The underlying goal is information summarization, but some models emphasize visualization, others the estimation of latent scores; each technique has its strengths and theoretical commitments.
Slightly off the main thread: linear algebra — the calculus of vectors and matrices — is the mathematical foundation underlying multivariate analysis. Its strength is to unify computation and visualization under one perspective. Readers who want a deeper grip on multivariate analysis are encouraged to study linear algebra alongside.
R. B. Cattell drew a covariation chart — a data cube — to classify data. Any observation or measurement, he argued, can be specified by three attributes:
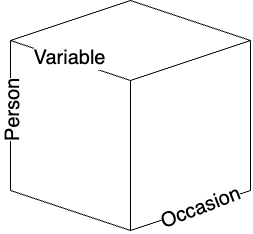
In psychology a “dataset” is typically a two-dimensional matrix of persons × variables (a spreadsheet), but that is a slice through the cube along one time point. Other slices and other reorderings of the axes give six possible covariation cross-sections.
| R | Q | O | P | S | T | |
|---|---|---|---|---|---|---|
| Technique | variable × person | person × person | occasion × occasion | person × occasion | occasion × variable | variable × occasion |
| Design | variable × person | person × occasion | occasion × variable | variable × occasion | person × variable | occasion × person |
| Factor extracted | variable | person | occasion | person | occasion | variable |
Cattell classified the factor analyses on each cross-section as separate techniques. The familiar factor analysis — computing a variable-to-variable correlation matrix from variable × person data and extracting factors among the variables — is R-technique. Computing a person × person correlation matrix and extracting “person factors” is Q-technique. Slicing person × occasion gives O-technique (factors among occasions) and P-technique (factors among persons viewed from the occasion side). S- and T-techniques are analogously defined. S-technique applications are scarce; the others each have a small literature.
Inter-variable relationships can equally well be distance matrices (similarity matrices) or co-frequency relationships. One could classify variables or persons by cluster analysis on a distance matrix. The choice of cross-section and the choice of perspective are both free.
Generalizing the three-dimensional restriction, more recent classifications use the data types present (modes) and the number of indexings (ways). For instance, mutual ratings among members within several groups have two modes (members and groups) with member × member relationships indexed over groups, giving 2-mode 3-way data. Family-systems research handles such data routinely.
Multivariate analysis, then, is a general toolkit asking which combination, which perspective, and which elements to summarize. The constraint “this cross-section is forbidden” does not arise; analysts visualize the whole and freely choose the meaningful cross-sections. Mathematically and statistically there are no model-level restrictions, and with packages such as R any of these analyses is feasible.
With this panoramic view, we turn to factor analysis — the technique psychology most embraces.
We outline factor analysis, one of psychology’s most widely used techniques. Factor analysis is a statistical model of measurement. A related technique, principal component analysis (PCA), is best described as a model of summarization rather than measurement.
The factor model is
\[ z_{ij} = a_{j1}f_{i1} + a_{j2}f_{i2} + \cdots + a_{jm}f_{im} + d_j U_{ij}, \]
where \(z_{ij}\) is the standardized score of person \(i\) on item \(j\); \(a_{j\cdot}\) are the factor loadings of item \(j\); \(f_{i\cdot}\) are person \(i\)’s factor scores; \(d_j\) is the unique-factor loading for item \(j\); and \(U_{ij}\) is the unique factor for person \(i\) on item \(j\). The \(m\) factors carried by the \(a_{j\cdot}\) are called common factors. Typically \(m \ll M\), the number of items. The Big Five personality inventory has \(M = 25\) and \(m = 5\); the YG personality test has \(M = 120\) and \(m = 12\). Factor analysis is thus a model of information compression.
PCA, by contrast, can be written
\[ P_i = w_1 X_{i1} + w_2 X_{i2} + \cdots + w_M X_{iM}, \]
where \(X_{i\cdot}\) is person \(i\)’s response on item \(j\), and \(P_i\) is the principal component formed as a weighted linear combination. The unknowns are the weights \(w_j\), chosen to produce the most discriminating composite — i.e., the weights that maximize the variance of \(P_i\). A single composite cannot in general capture all the information across \(M\) variables, so further principal components are constructed in order.
What, then, distinguishes the \(m\) common factors of factor analysis from \(m\) principal components? Factor analysis is a measurement model: the data \(z_{ij} = (X_{ij} - \bar{X}_j)/\sigma_j\) are assumed to contain measurement error \(d_j U_{ij}\). PCA makes no such assumption and uses \(X_{ij}\) directly.
In practice, responses that plausibly contain measurement error — e.g., psychological scale responses — call for factor analysis; quantities recorded without error — official records, accounting data — call for PCA. The historical spread of factor analysis through psychology and test theory, and of PCA through economics, commerce, and sociology, reflects this division.
Computationally the two share the use of eigenvalue decomposition to extract the most-explanatory components from an inter-variable relationship, so many software packages bundle them in the same menu, with different output styles. The design-level difference is nonetheless worth knowing. Factor analysis typically operates on a correlation matrix, PCA on a variance–covariance matrix; this reflects that psychological measurement is on a relative scale (more extraverted, more introverted), whereas other social-science quantities (trade surpluses, etc.) are absolute. PCA, aimed at compression, typically focuses on the first component; factor analysis, motivated by measurement theory, typically considers several factors. The choice between a single-factor and multi-factor view of intelligence in early intelligence testing reflects exactly this theoretical disagreement.
Similar techniques, different premises: knowing the background helps you pick the right tool.
When unqualified, “factor analysis” usually means exploratory factor analysis (EFA). “Exploratory” reflects that neither the factor loadings nor even the number of common factors are fixed in advance; both are inferred from the data.
EFA proceeds in three steps:
Before any of this, you should have characterized the data with descriptive statistics and visualization.
Mathematically, factor analysis reduces to an eigenvalue decomposition of the correlation matrix \(\mathbb{R}\) among the \(M\) items. The default correlation is the Pearson product-moment; ordinal items call for polychoric correlations, binary items for tetrachoric correlations.
Eigenvalue decomposition exposes the dimensionality of the correlation matrix. Information in \(M\) items occupies \(M\) dimensions. With two variables \(X, Y\), the data live in the 2-D space with \(X\) and \(Y\) as axes. If \(X\) and \(Y\) are correlated, an orthogonal \((X, Y)\) representation may not be the most efficient; a rotated basis with larger variance along one axis may be available. This is the common idea behind factor analysis and PCA: PCA focuses on the axis with the largest variance; factor analysis distinguishes the “useful dimensions” — the common factors — from the rest, which are absorbed into error.
The number of factors is chosen by the analyst, and the determination of “useful dimensions” has a subjective component. Many objective criteria have been proposed and are routinely used today, but treating mathematically extracted dimensions as substantive common factors is the analyst’s responsibility.
A common rule for setting the number of factors is parallel analysis based on the scree plot. We illustrate with the psych package and its bfi sample data — five-item-per-factor measurements of the Big Five.
pacman::p_load(tidyverse, psych)
dat <- psych::bfi |> select(-gender, -education, -age)
# parallel analysis
fa.parallel(dat)
Parallel analysis suggests that the number of factors = 6 and the number of components = 6 A scree plot plots the eigenvalues from largest to smallest as a line graph. By default, both PC (principal-component) and FA (factor-analysis) scree plots are shown. The two differ in whether measurement error is assumed: factor analysis posits per-item error, so the per-item information is below 1 (\(r_{jj} = 1 - h_j^2 = u^2 < 1\), with \(h_j^2\) the communality — the sum of squared common-factor loadings — and \(u_j^2\) the uniqueness). The FA curve therefore always lies below the PC curve.
The legend distinguishes Actual Data, Simulated Data, and Resampled Data. Real data have some semantic structure; their correlation matrix is unevenly distributed across dimensions, producing a gradually decaying scree curve. Simulated data are drawn from random numbers of the same size; resampled data are obtained by shuffling the original matrix. Neither carries semantic structure, so every dimension is uniformly uninformative, and the eigenvalues form a near-flat line. Parallel analysis compares the two: dimensions whose actual eigenvalue exceeds the flat line are meaningful. On this criterion, both the FA and PC solutions support six factors.
A horizontal line at eigenvalue 1 is also drawn, marking the older Kaiser–Guttman criterion that a factor must explain at least one variable’s worth of variance to qualify as a common factor. By this rule three factors are warranted. Yet another rule of thumb is “what proportion of total variance is explained”: if three factors capture less than 50%, that may be too much information discarded, and four or five factors might be retained instead.
Once the number of factors is set, we estimate the loadings. For instance:
result.fa <- fa(dat, nfactors = 6, fm = "ML", rotate = "geominQ")要求されたパッケージ GPArotation をロード中ですpsych::fa() offers many options; here we specify the number of factors (nfactors), the estimation method (fm), and the rotation method (rotate).
For estimation we chose maximum likelihood (ML). For samples of more than ~200, ML — assuming multivariate-normal data — is generally most appropriate. For small samples, the least-squares family (ULS, OLS, WLS, GLS, etc.) minimizes the model–data discrepancy and is the safer choice. Without specification, minimum residual (minres) — the same as ULS in concept, but with an improved algorithm with better convergence — is the default. The principal-axis option (pa) corresponds to a model without estimated errors. The differences across algorithms are usually modest.
Rotation transforms the loadings to ease interpretation. Factor analysis and PCA identify new axes for the data, but those axes can be linearly transformed (rotated) about the origin to any orientation. In practice we want the orientation that is easiest to interpret. Mathematically, this is the rotation that yields simple structure: each item loads on one factor and minimally on the others. If items measuring Extraversion load heavily on the first factor, we prefer that they not also load on factors 2, 3, 4, and 5 — otherwise interpretation becomes a headache.
Within this guiding principle, many algorithms exist. The classical varimax rotation maximizes the variance of squared loadings on each factor. Other choices include oblimin and geomin; for details see 小杉 (2018).
Rotations split into orthogonal and oblique. Orthogonal rotations keep the rotated axes orthogonal — i.e., assume no inter-factor correlation. Oblique rotations allow inter-factor correlations. The latter is mathematically the weaker assumption, so a sensible workflow is to do oblique first and, if the inter-factor correlations are small, re-do orthogonal. Here we used geominQ, the oblique version of geomin.
The (Bernaards and Jennrich 2005) package implements many rotations selectable via rotate; consult its help.
There is no absolute standard for rotation either; algorithms reflect different premises. Unlike estimation, however, loadings can change appreciably under different rotations. Choose whichever rotation makes interpretation easiest, but be ready to explain — in your own words — what the rotation is and what it assumes.
print(result.fa, sort = T, cut = 0.3)Factor Analysis using method = ml
Call: fa(r = dat, nfactors = 6, rotate = "geominQ", fm = "ML")
Standardized loadings (pattern matrix) based upon correlation matrix
item ML1 ML2 ML5 ML3 ML4 ML6 h2 u2 com
E2 12 0.70 0.55 0.45 1.0
E1 11 0.58 0.39 0.61 1.4
N4 19 0.51 0.35 0.48 0.52 2.0
E4 14 -0.50 0.33 0.56 0.44 2.2
E5 15 -0.41 0.40 0.60 2.8
N2 17 0.84 0.69 0.31 1.1
N1 16 0.83 0.71 0.29 1.1
N3 18 0.61 0.52 0.48 1.3
N5 20 0.33 0.37 0.34 0.66 2.8
A2 2 0.70 0.50 0.50 1.2
A3 3 0.65 0.51 0.49 1.1
A1 1 -0.57 0.37 0.33 0.67 1.8
A5 5 0.50 0.48 0.52 1.7
A4 4 0.42 0.28 0.72 1.7
C2 7 0.67 0.50 0.50 1.2
C4 9 -0.60 0.35 0.55 0.45 1.9
C3 8 0.54 0.31 0.69 1.1
C1 6 0.53 0.35 0.65 1.4
C5 10 -0.51 0.43 0.57 1.8
O3 23 0.67 0.48 0.52 1.0
O1 21 0.58 0.34 0.66 1.1
O5 25 -0.49 0.41 0.37 0.63 2.0
O2 22 -0.40 0.34 0.29 0.71 2.3
O4 24 0.40 0.40 0.25 0.75 2.4
E3 13 0.38 0.48 0.52 3.0
ML1 ML2 ML5 ML3 ML4 ML6
SS loadings 2.34 2.25 2.00 1.89 1.77 0.82
Proportion Var 0.09 0.09 0.08 0.08 0.07 0.03
Cumulative Var 0.09 0.18 0.26 0.34 0.41 0.44
Proportion Explained 0.21 0.20 0.18 0.17 0.16 0.07
Cumulative Proportion 0.21 0.41 0.59 0.77 0.93 1.00
With factor correlations of
ML1 ML2 ML5 ML3 ML4 ML6
ML1 1.00 0.24 -0.36 -0.20 -0.28 -0.08
ML2 0.24 1.00 -0.01 -0.12 0.05 0.25
ML5 -0.36 -0.01 1.00 0.19 0.28 0.26
ML3 -0.20 -0.12 0.19 1.00 0.14 0.04
ML4 -0.28 0.05 0.28 0.14 1.00 0.11
ML6 -0.08 0.25 0.26 0.04 0.11 1.00
Mean item complexity = 1.7
Test of the hypothesis that 6 factors are sufficient.
df null model = 300 with the objective function = 7.23 with Chi Square = 20163.79
df of the model are 165 and the objective function was 0.36
The root mean square of the residuals (RMSR) is 0.02
The df corrected root mean square of the residuals is 0.03
The harmonic n.obs is 2762 with the empirical chi square 330.64 with prob < 3.7e-13
The total n.obs was 2800 with Likelihood Chi Square = 1013.79 with prob < 4.6e-122
Tucker Lewis Index of factoring reliability = 0.922
RMSEA index = 0.043 and the 90 % confidence intervals are 0.04 0.045
BIC = -295.88
Fit based upon off diagonal values = 0.99
Measures of factor score adequacy
ML1 ML2 ML5 ML3 ML4 ML6
Correlation of (regression) scores with factors 0.81 0.89 0.81 0.85 0.82 0.74
Multiple R square of scores with factors 0.66 0.80 0.66 0.72 0.67 0.54
Minimum correlation of possible factor scores 0.32 0.59 0.33 0.44 0.34 0.09We set sort (sort items by loading) and cut (suppress loadings smaller than 0.3 in the display). These are display options; the underlying \(5 \times 25\) paths from each factor to each item are all computed.
The output starts with the loading matrix, the communality \(h_j^2\), the uniqueness \(u_j^2 = 1 - h_j^2\), and the complexity.1 These are the post-rotation pattern matrix. In an oblique rotation, the loadings split into the pattern (factor effects, projecting variables orthogonally onto an oblique factor system) and the structure (factor correlations: variable–factor simple correlations).
Below the loadings, the sum of squared loadings (SS loadings) shows the variance explained by each factor; the proportions and cumulative proportions follow. Here the cumulative explained variance is 44%, meaning 56% of the information is discarded — from a compression standpoint, potentially too much.
Because the rotation is oblique, inter-factor correlations are reported next. The largest absolute correlation is −0.36. If all inter-factor correlations are within ±0.3, an orthogonal rotation can be considered.
Goodness-of-fit indices follow; we omit detailed discussion.
So far we have estimated relationships between factors and items. In psychological research one is also interested in person-by-factor relationships: who is high on Extraversion, and what characterizes low-Neuroticism individuals?
Mathematically, the eigenvalue decomposition that produces the loadings also produces eigenvectors; the per-person information has been summarized away by the time the correlation matrix is constructed. After the factor structure is fixed, we therefore back-compute the per-person scores: with the factor loadings known on the right-hand side of the factor model and the observed values on the left, we solve for the factor scores \(f_{i\cdot}\).
psych::fa() returns factor scores by default:
head(result.fa$scores, 10) ML1 ML2 ML5 ML3 ML4 ML6
61617 -0.04010511 -0.13419381 -0.69145376 -1.29299334 -1.6430660 -0.12400705
61618 -0.35267122 0.09080773 -0.04506789 -0.60267233 -0.0566277 0.39616337
61620 -0.05290788 0.69698270 -0.68175428 -0.03704608 0.2334657 0.01280638
61621 0.22194371 -0.07729865 -0.15482554 -0.90538802 -0.9125738 0.95278898
61622 -0.39695952 -0.28825362 -0.61037363 -0.12382926 -0.5814368 0.21976607
61623 -1.05223173 0.41585860 0.29450029 1.35906961 0.8457775 0.45985066
61624 -0.43875292 -1.21974967 0.06875832 0.03201599 0.6001998 -0.69274350
61629 1.42563085 0.35294078 -2.23058559 -0.99435391 -1.2166723 -1.00627947
61630 NA NA NA NA NA NA
61633 -0.62399161 1.11010731 0.53805411 1.05139495 0.4870489 0.04325653Some scores are NA (e.g., ID 61630): this happens when any response is missing.
head(dat, 10) A1 A2 A3 A4 A5 C1 C2 C3 C4 C5 E1 E2 E3 E4 E5 N1 N2 N3 N4 N5 O1 O2 O3 O4
61617 2 4 3 4 4 2 3 3 4 4 3 3 3 4 4 3 4 2 2 3 3 6 3 4
61618 2 4 5 2 5 5 4 4 3 4 1 1 6 4 3 3 3 3 5 5 4 2 4 3
61620 5 4 5 4 4 4 5 4 2 5 2 4 4 4 5 4 5 4 2 3 4 2 5 5
61621 4 4 6 5 5 4 4 3 5 5 5 3 4 4 4 2 5 2 4 1 3 3 4 3
61622 2 3 3 4 5 4 4 5 3 2 2 2 5 4 5 2 3 4 4 3 3 3 4 3
61623 6 6 5 6 5 6 6 6 1 3 2 1 6 5 6 3 5 2 2 3 4 3 5 6
61624 2 5 5 3 5 5 4 4 2 3 4 3 4 5 5 1 2 2 1 1 5 2 5 6
61629 4 3 1 5 1 3 2 4 2 4 3 6 4 2 1 6 3 2 6 4 3 2 4 5
61630 4 3 6 3 3 6 6 3 4 5 5 3 NA 4 3 5 5 2 3 3 6 6 6 6
61633 2 5 6 6 5 6 5 6 2 1 2 2 4 5 5 5 5 5 2 4 5 1 5 5
O5
61617 3
61618 3
61620 2
61621 5
61622 3
61623 1
61624 1
61629 3
61630 1
61633 2Because factor scores are back-computed from the model, a single missing value blocks the calculation. The scores returned are standardized, hence unitless and only relatively comparable. Some authors argue against subsequent tests of mean differences on relative estimates of this kind.
In practice a simpler simple-sum factor score is widely used: identify the items associated with each factor and average their item-level responses. With our example, say the first factor reflects E2, E1, N4, E4, E5. Because E4 and E5 have negative loadings, their values are reverse-scored:
Fscore1.raw <- dat |>
# pick out the items relevant to the first factor
select(E2, E1, N4, E4, E5) |>
# reverse-score
mutate(
E4 = 7 - E4,
E5 = 7 - E5
)
# row-wise mean, ignoring missings
Fscore1 <- apply(Fscore1.raw, 1, function(x) mean(x, na.rm = TRUE))
summary(Fscore1) Min. 1st Qu. Median Mean 3rd Qu. Max.
1.000 2.000 2.800 2.892 3.600 6.000 Reverse-scoring is done by subtracting from 7 (for a 6-point scale starting at 1). The advantage is that the score retains its scale-anchored meaning (above the midpoint = agreement, below = disagreement) and is computable as long as some responses are present.
The drawbacks: it ignores the per-item weighting given by the loadings, and the error variance that factor analysis was supposed to remove is reintroduced. The scale items themselves should ideally have been constructed by proper scaling methods; in practice that rarely happens, and the simple-sum score is consequently a rough estimate.
Even so, simple-sum and model-based scores correlate very highly. If you can accept that psychological data are not so precise as to justify finer measurement, the simple sum is often enough.
cor(result.fa$scores[, 1], Fscore1, use = "pairwise")[1] 0.9595003plot(result.fa$scores[, 1], Fscore1)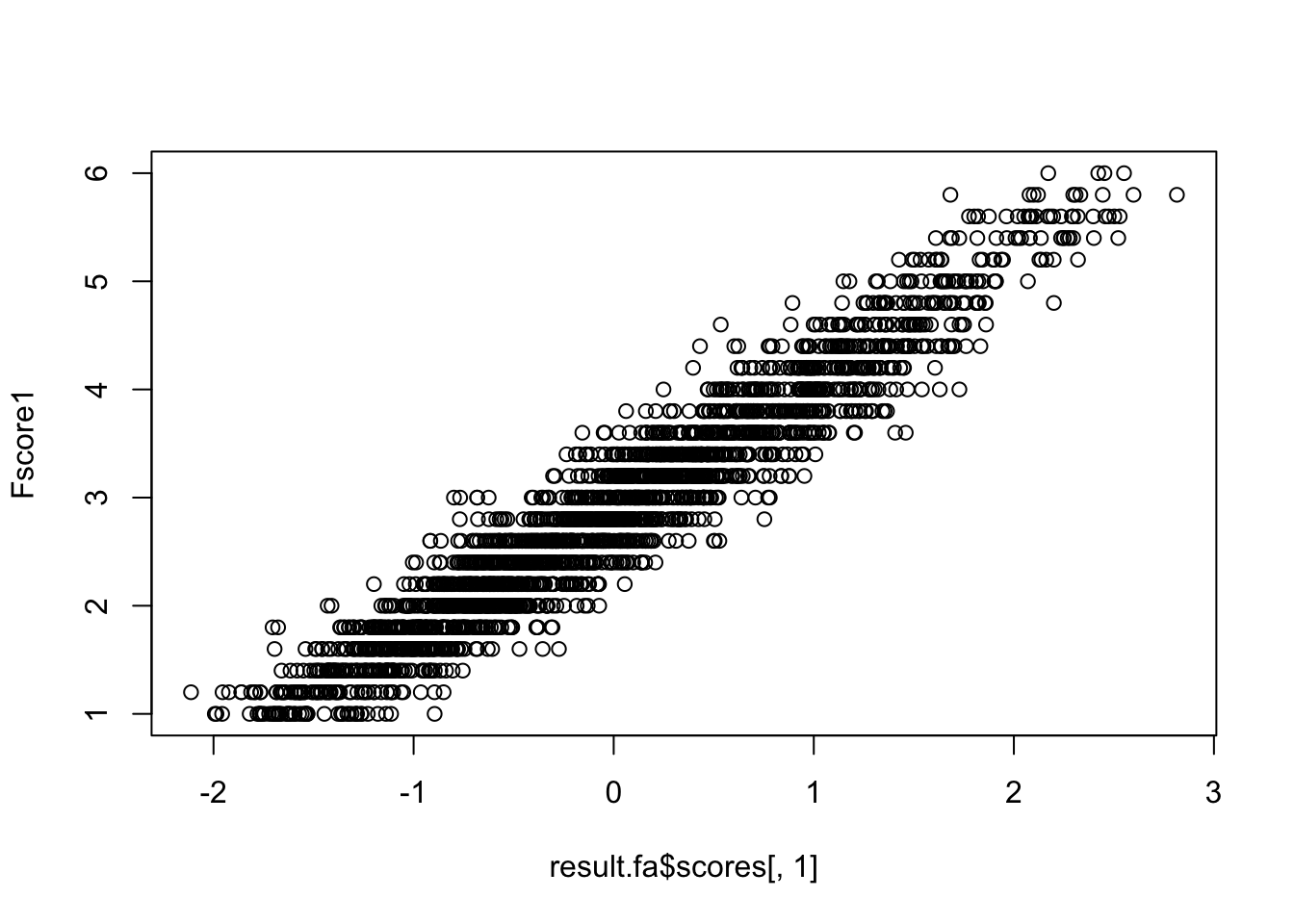
So far we have discussed exploratory factor analysis. There the number of factors and the loadings are not specified a priori; the data speak, and interpretation is post hoc. In our example the first factor consists mainly of Extraversion items, but a Neuroticism item (N4) also slips in, complicating interpretation. The Big Five name implies five factors, yet the data prefer six.
Sometimes the theory is firmer than that: personality inventories have well-grounded structures, and one prefers to test a hypothesized structure. Confirmatory factor analysis (CFA) is the appropriate tool: factor structure is specified in advance and fitted to the data. CFA sits inside structural equation modeling (SEM): the relationships between items and latent variables are expressed as equations and estimated.
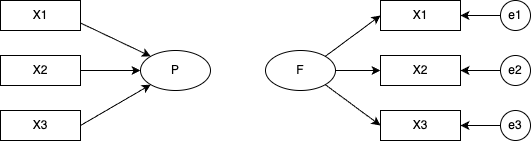
SEM fits equations involving latent variables to a covariance/correlation structure. The relationships are often drawn as a path diagram: bidirectional arrows for correlations, unidirectional arrows for regressions, rectangles for observed variables, ovals for latent variables. The diagram makes the difference between factor analysis and PCA stark:
And between EFA and CFA:
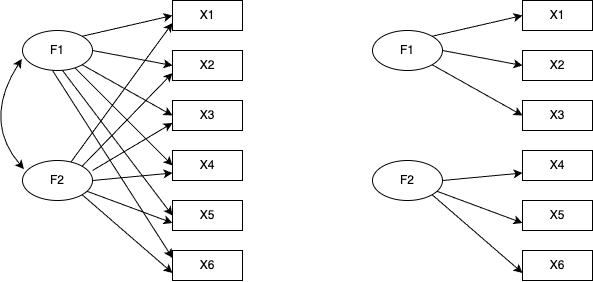
In CFA, each factor’s effect on each item is specified individually — equivalently, the paths assumed absent are fixed to zero. The figure assumes zero inter-factor correlations, which is why no path is drawn between the factors (correlations can of course be drawn).
The model comes first; the covariance matrix implied by the model is fit to the observed covariance matrix. Estimation methods include OLS, ML, and Bayesian methods; in practice you should know the algorithm name as well. Post-estimation you assess goodness of fit, with several indices considered together.
A worked example in R, using the lavaan package.2 Specify a CFA model3:
pacman::p_load(lavaan)
# model specification
model <- "
Neuroticism =~ N1 + N2 + N3 + N4 + N5
Agreeableness =~ A1 + A2 + A3 + A4 + A5
Extraversion =~ E1 + E2 + E3 + E4 + E5
Openness =~ O1 + O2 + O3 + O4 + O5
Conscientiousness =~ C1 + C2 + C3 + C4 + C5
"Note that the model is a string in quotes. Latent variables go on the left, indicators on the right, connected by =~ (the measurement equation). Correlations use ~~; regressions use ~. Equations between latent variables are called structural equations.
No inter-factor correlations are specified; by default a covariance between any two latent variables not declared zero is freely estimated. To force a zero, write Neuroticism ~~ 0 * Openness.
With the model specified, fit it. We use ML and request fit measures and standardized coefficients in the summary:
# model estimation
model.fit <- sem(model, estimator = "ML", data = dat)
summary(model.fit, fit.measures = TRUE, standardized = TRUE)lavaan 0.6-21 ended normally after 55 iterations
Estimator ML
Optimization method NLMINB
Number of model parameters 60
Used Total
Number of observations 2436 2800
Model Test User Model:
Test statistic 4165.467
Degrees of freedom 265
P-value (Chi-square) 0.000
Model Test Baseline Model:
Test statistic 18222.116
Degrees of freedom 300
P-value 0.000
User Model versus Baseline Model:
Comparative Fit Index (CFI) 0.782
Tucker-Lewis Index (TLI) 0.754
Loglikelihood and Information Criteria:
Loglikelihood user model (H0) -99840.238
Loglikelihood unrestricted model (H1) -97757.504
Akaike (AIC) 199800.476
Bayesian (BIC) 200148.363
Sample-size adjusted Bayesian (SABIC) 199957.729
Root Mean Square Error of Approximation:
RMSEA 0.078
90 Percent confidence interval - lower 0.076
90 Percent confidence interval - upper 0.080
P-value H_0: RMSEA <= 0.050 0.000
P-value H_0: RMSEA >= 0.080 0.037
Standardized Root Mean Square Residual:
SRMR 0.075
Parameter Estimates:
Standard errors Standard
Information Expected
Information saturated (h1) model Structured
Latent Variables:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
Neuroticism =~
N1 1.000 1.300 0.825
N2 0.947 0.024 39.899 0.000 1.230 0.803
N3 0.884 0.025 35.919 0.000 1.149 0.721
N4 0.692 0.025 27.753 0.000 0.899 0.573
N5 0.628 0.026 24.027 0.000 0.816 0.503
Agreeableness =~
A1 1.000 0.484 0.344
A2 -1.579 0.108 -14.650 0.000 -0.764 -0.648
A3 -2.030 0.134 -15.093 0.000 -0.983 -0.749
A4 -1.564 0.115 -13.616 0.000 -0.757 -0.510
A5 -1.804 0.121 -14.852 0.000 -0.873 -0.687
Extraversion =~
E1 1.000 0.920 0.564
E2 1.226 0.051 23.899 0.000 1.128 0.699
E3 -0.921 0.041 -22.431 0.000 -0.847 -0.627
E4 -1.121 0.047 -23.977 0.000 -1.031 -0.703
E5 -0.808 0.039 -20.648 0.000 -0.743 -0.553
Openness =~
O1 1.000 0.635 0.564
O2 -1.020 0.068 -14.962 0.000 -0.648 -0.418
O3 1.373 0.072 18.942 0.000 0.872 0.724
O4 0.437 0.048 9.160 0.000 0.277 0.233
O5 -0.960 0.060 -16.056 0.000 -0.610 -0.461
Conscientiousness =~
C1 1.000 0.680 0.551
C2 1.148 0.057 20.152 0.000 0.781 0.592
C3 1.036 0.054 19.172 0.000 0.705 0.546
C4 -1.421 0.065 -21.924 0.000 -0.967 -0.702
C5 -1.489 0.072 -20.694 0.000 -1.012 -0.620
Covariances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
Neuroticism ~~
Agreeableness 0.141 0.018 7.712 0.000 0.223 0.223
Extraversion 0.292 0.032 9.131 0.000 0.244 0.244
Openness -0.093 0.022 -4.138 0.000 -0.112 -0.112
Conscientisnss -0.250 0.025 -10.117 0.000 -0.283 -0.283
Agreeableness ~~
Extraversion 0.304 0.025 12.293 0.000 0.683 0.683
Openness -0.093 0.011 -8.446 0.000 -0.303 -0.303
Conscientisnss -0.110 0.012 -9.254 0.000 -0.334 -0.334
Extraversion ~~
Openness -0.265 0.021 -12.347 0.000 -0.453 -0.453
Conscientisnss -0.224 0.020 -11.121 0.000 -0.357 -0.357
Openness ~~
Conscientisnss 0.130 0.014 9.190 0.000 0.301 0.301
Variances:
Estimate Std.Err z-value P(>|z|) Std.lv Std.all
.N1 0.793 0.037 21.575 0.000 0.793 0.320
.N2 0.836 0.036 23.458 0.000 0.836 0.356
.N3 1.222 0.043 28.271 0.000 1.222 0.481
.N4 1.654 0.052 31.977 0.000 1.654 0.672
.N5 1.969 0.060 32.889 0.000 1.969 0.747
.A1 1.745 0.052 33.725 0.000 1.745 0.882
.A2 0.807 0.028 28.396 0.000 0.807 0.580
.A3 0.754 0.032 23.339 0.000 0.754 0.438
.A4 1.632 0.051 31.796 0.000 1.632 0.740
.A5 0.852 0.032 26.800 0.000 0.852 0.528
.E1 1.814 0.058 31.047 0.000 1.814 0.682
.E2 1.332 0.049 26.928 0.000 1.332 0.512
.E3 1.108 0.038 29.522 0.000 1.108 0.607
.E4 1.088 0.041 26.732 0.000 1.088 0.506
.E5 1.251 0.040 31.258 0.000 1.251 0.694
.O1 0.865 0.032 27.216 0.000 0.865 0.682
.O2 1.990 0.063 31.618 0.000 1.990 0.826
.O3 0.691 0.039 17.717 0.000 0.691 0.476
.O4 1.346 0.040 34.036 0.000 1.346 0.946
.O5 1.380 0.045 30.662 0.000 1.380 0.788
.C1 1.063 0.035 30.073 0.000 1.063 0.697
.C2 1.130 0.039 28.890 0.000 1.130 0.650
.C3 1.170 0.039 30.194 0.000 1.170 0.702
.C4 0.960 0.040 24.016 0.000 0.960 0.507
.C5 1.640 0.059 27.907 0.000 1.640 0.615
Neuroticism 1.689 0.073 23.034 0.000 1.000 1.000
Agreeableness 0.234 0.030 7.839 0.000 1.000 1.000
Extraversion 0.846 0.062 13.693 0.000 1.000 1.000
Openness 0.404 0.033 12.156 0.000 1.000 1.000
Conscientisnss 0.463 0.036 12.810 0.000 1.000 1.000The output begins with a model summary (estimator, etc.) and then a battery of fit indices (CFI, TLI, AIC, BIC, RMSEA, SRMR, …). These fall into three categories:
First, comparative indices anchored at a null model (worst possible) of 0 and a saturated model (perfect fit) of 1 — CFI and TLI fall here. The saturated model fits the data perfectly with all possible paths; the null (independence) model assumes no inter-variable association whatsoever and is the most constrained.
Second, likelihood-based relative indices — AIC, BIC, SABIC. The likelihood expresses how close the model’s distribution is to the data, so it is meaningful only for comparing models on the same data. AIC (Akaike Information Criterion) combines \(-2\) log-likelihood with the number of parameters: \(-2\text{LL} + 2p\). Smaller is better. BIC (Bayesian Information Criterion) penalizes parameters more heavily, scaled by the sample size. SABIC is a sample-size-adjusted variant.
Third, residual-based indices — RMSEA, SRMR. RMSEA (Root Mean Square Error of Approximation) targets the model’s approximation error; values below 0.05 are conventionally “good.” SRMR (Standardized Root Mean Square Residual) is the standardized root mean square of the residuals between observed and model-implied data; values below 0.08 are “good.”
When evaluating model fit, look at several indices together rather than rely on any single one.
Below the fit indices come the estimates and test statistics. In psychology, the column most often consulted is Std.all, with all variables standardized.4 Small or non-significant path coefficients can be dropped to improve fit — but improving fit should not be a research goal. If conventional thresholds cannot be met, revisit the assumptions; adding paths inconsistent with theory just to push fit up is the same kind of QRP as “engineering significance.”
Packages also automate path-diagram drawing. Several exist (lavaanExtra, tidySEM, lavaanPlot, lavaanPlot2); we illustrate with the classical semPlot:
pacman::p_load(semPlot)
semPaths(model.fit, what = "stand", style = "lisrel")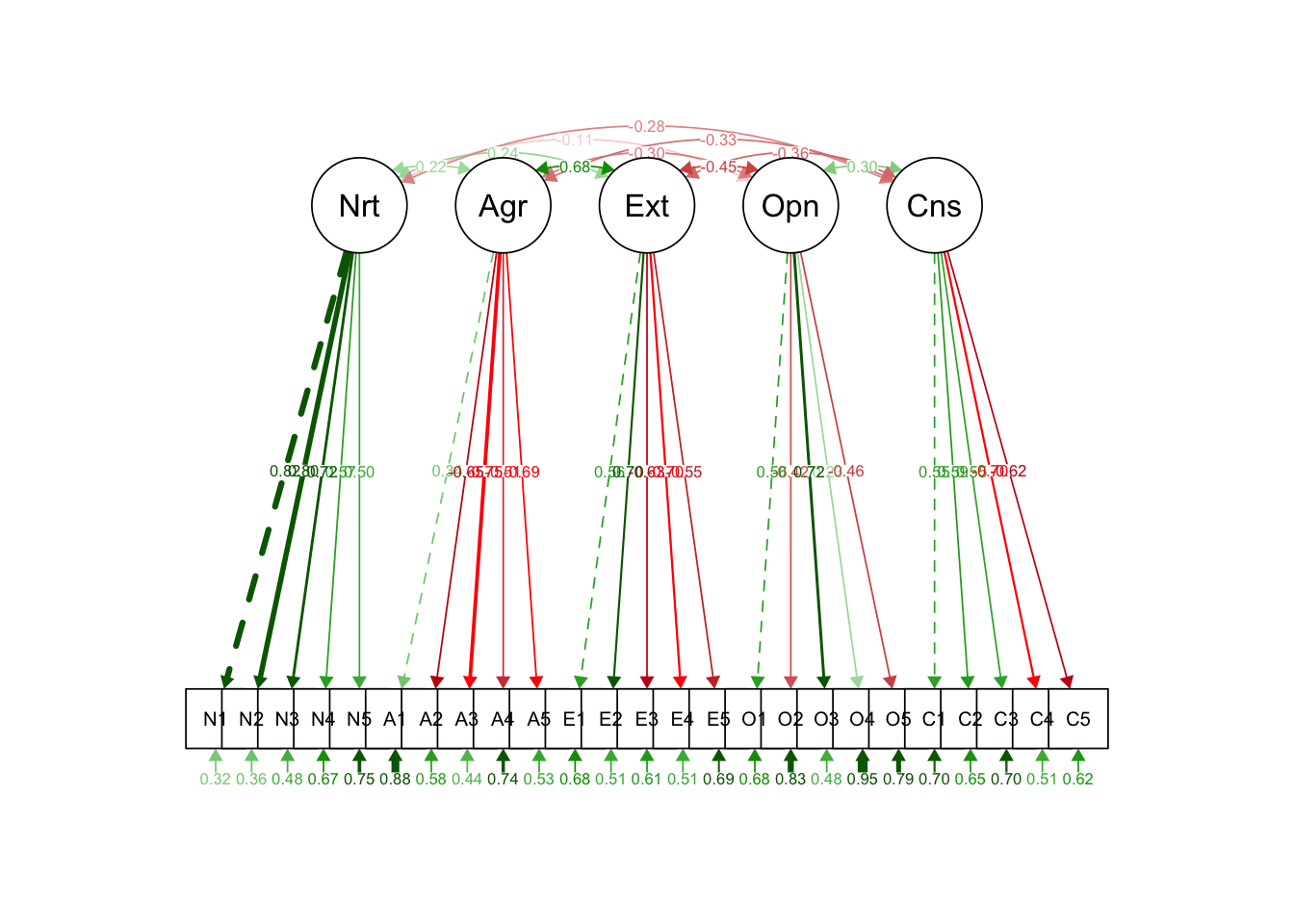
That concludes the overview of factor analysis.
Factor analysis is a model of measurement and is heavily used when designing psychological scales. But because it identifies common dimensions from inter-item correlations, neither “the construct has been measured directly” nor “the existence of the construct has been demonstrated” follows. For example, write items about ramen and have respondents rate them quantitatively, and you can extract a “ramen factor” or a “tonkotsu factor” with some interpretive content. That does not mean people have internalized a psychological “tonkotsu factor.”
SEM can specify regression or correlation paths between latent variables, but it pays to think about how those relationships actually manifest. Even a strongly fitting model with strong cross-factor influence may have small measurement-model coefficients: ask what concretely changes when a factor score increases by one unit, and how that shows up in behavior or measurement. A statistically valid but substantively meaningless model is a paper exercise.
Issues of measurement and substantive impact run in parallel between factor analysis and item response theory (a relative of factor analysis), to which we now turn.
SEM is not confined to confirmatory factor analysis; it provides a flexible vocabulary for structural relationships between latent variables and so supports several useful extensions.
Next, item response theory (IRT). Sometimes called modern test theory in contrast to classical test theory (CTT), IRT is grounded in test theory and so assumes a binary outcome (0 = incorrect, 1 = correct). It can also be viewed as factor analysis with a binary indicator, and its mathematical equivalence to categorical factor analysis is established.
A further difference from factor analysis: factor analysis (rooted in personality psychology) emphasizes exploring factor structure, while IRT (rooted in test theory) emphasizes refining factor-score estimation. In personality psychology the number of factors is itself a research question; in test theory a single-factor “ability” structure is preferred. This is why scale construction via factor analysis cultivates “simple structure” and prunes items, while IRT — given a sufficiently large first-factor loading (around 30% variance is typical) — treats the data as essentially unidimensional and pools items rather than discarding them.
Computer adaptive testing (CAT) is the leading current application of IRT: items are served dynamically from a pool based on the respondent’s pattern of correct/incorrect answers, efficiently estimating the latent ability. CAT requires an IRT-based model, an item pool calibrated for various ability levels, and a database-and-delivery system tying them together.5
IRT is a single-factor model for binary data. Because of the binary outcome, dimensional analysis uses tetrachoric correlations rather than Pearson’s. Modeling treats item responses as regressed on a person parameter \(\theta\) that corresponds to the factor — a logistic-regression-like setup.
The person parameter is assumed standard normal; expressed via the normal CDF, this is well approximated by a logistic curve, and the linear placement of item parameters fits naturally inside a logistic model.6 The standard normal density, its CDF, and a logistic approximation thereof are plotted below. The logistic model conventionally uses the constant 1.702 in the exponent to better approximate the normal CDF:
\[ f(x) = \frac{1}{1 + \exp(-1.702 x)}. \]
pacman::p_load(ggplot2, patchwork)
x <- seq(-4, 4, length.out = 1000)
normal_df <- data.frame(
x = x,
density = dnorm(x),
cdf = pnorm(x),
logistic = 1 / (1 + exp(-1.702 * x))
)
# 1. standard normal density
p1 <- ggplot(normal_df, aes(x = x, y = density)) +
geom_line() +
labs(title = "Standard normal density", x = "x", y = "density") +
theme_minimal()
# 2. standard normal CDF
p2 <- ggplot(normal_df, aes(x = x, y = cdf)) +
geom_line() +
labs(title = "Standard normal CDF", x = "x", y = "cumulative probability") +
theme_minimal()
# 3. logistic approximation
p3 <- ggplot(normal_df, aes(x = x, y = logistic)) +
geom_line() +
labs(title = "Logistic approximation", x = "x", y = "probability") +
theme_minimal()
p1 + p2 + p3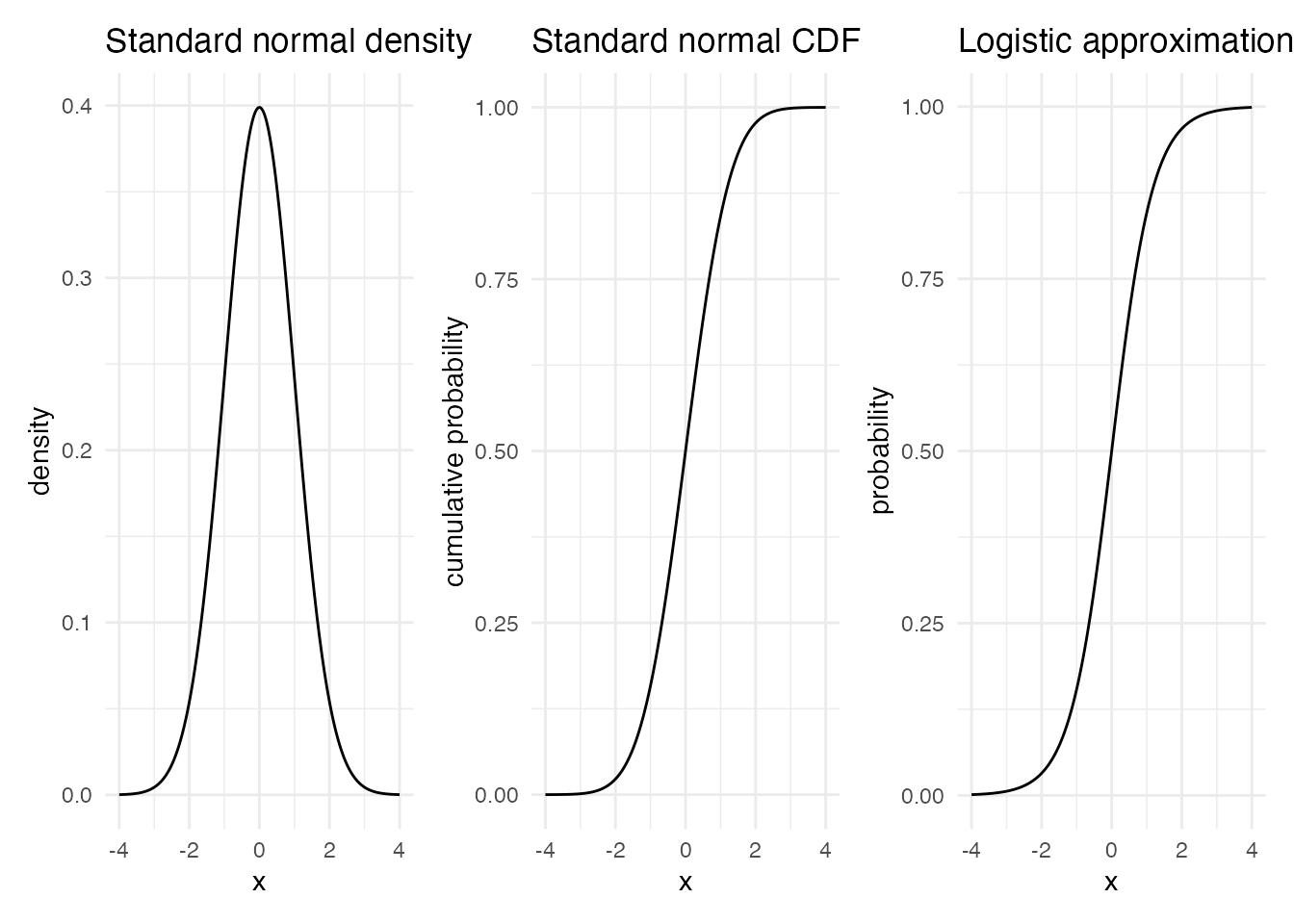
Using this logistic function we now characterize items via item parameters. IRT logistic models come with various numbers of parameters, with the more elaborate ones containing the simpler as special cases.
The one-parameter logistic (1PL) model has a single item parameter \(b\):
\[ P(Y_{ij} = 1 \mid \theta_i, b_j) = \frac{1}{1 + \exp(-1.702 (\theta_i - b_j))}. \]
\(Y_{ij}\) is the binary indicator of correctness for person \(i\) on item \(j\); \(\theta_i\) is the person’s ability; \(b_j\) is the item’s difficulty. Larger \(b_j\) shifts the curve to the right (so the same probability of correct response requires higher ability), and smaller \(b_j\) shifts it left.
logistic_1pl <- function(theta, b) {
1 / (1 + exp(-1.702 * (theta - b)))
}
x <- seq(-4, 4, length.out = 1000)
normal_df <- data.frame(
x = x,
default = logistic_1pl(x, 0),
easy = logistic_1pl(x, -1),
hard = logistic_1pl(x, 1)
)
ggplot(normal_df) +
geom_line(aes(x = x, y = default, color = "default (b=0)")) +
geom_line(aes(x = x, y = easy, color = "easy (b=-1)")) +
geom_line(aes(x = x, y = hard, color = "hard (b=1)")) +
scale_color_brewer(palette = "Set2") +
labs(
title = "1PL logistic model",
x = "theta",
y = "P(correct)",
color = "difficulty"
) +
theme_minimal() +
theme(legend.position = "bottom")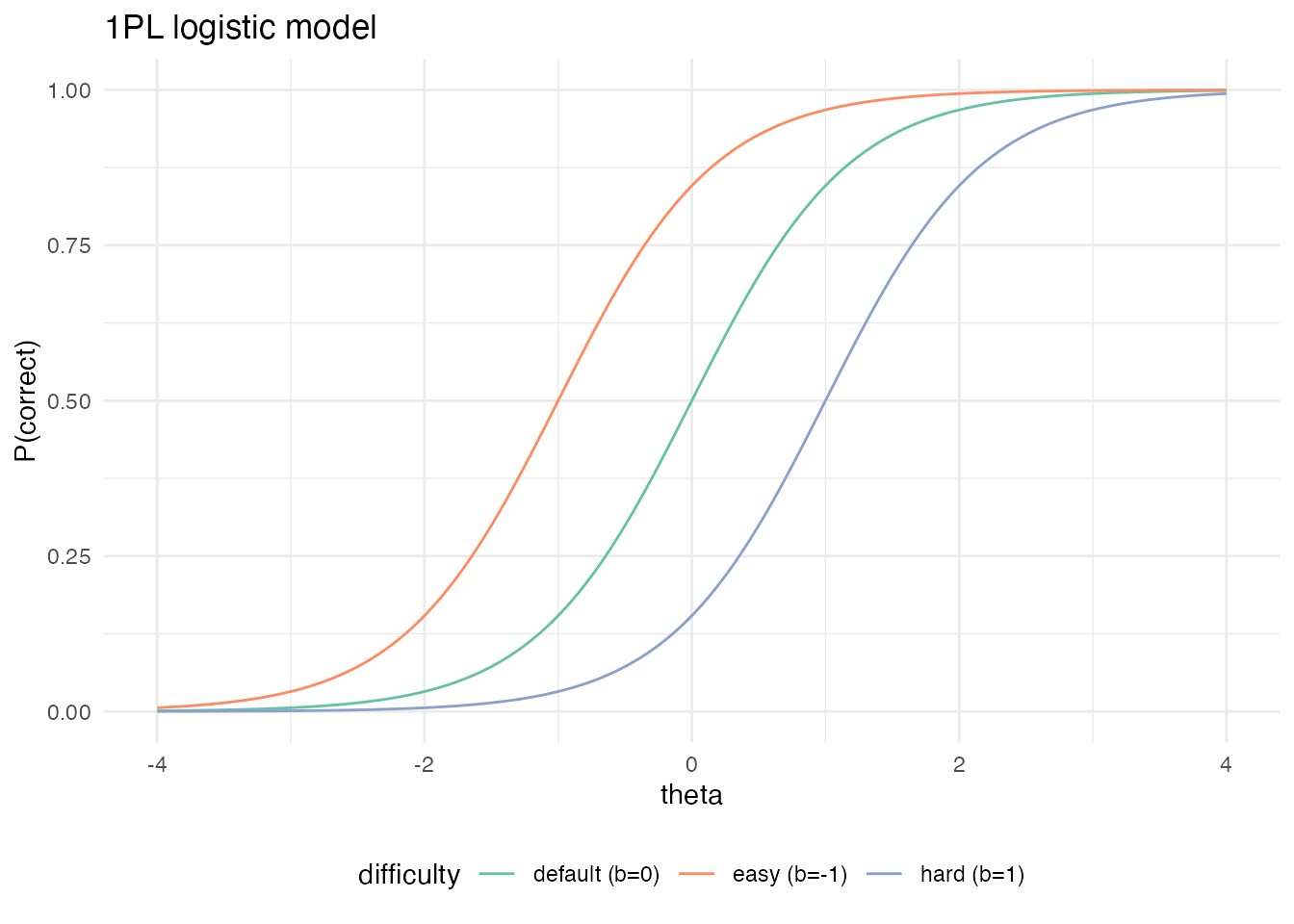
The 2PL model adds an item parameter \(a_j\) — the discrimination:
\[ P(Y_{ij} = 1 \mid \theta_i, a_j, b_j) = \frac{1}{1 + \exp(-1.702 a_j (\theta_i - b_j))}. \]
It is called the discrimination parameter because it controls the slope of the logistic curve. A steep slope means a sharp transition from incorrect to correct around a particular \(\theta\); a shallow slope means the item only weakly distinguishes ability levels. In categorical factor analysis, \(b_j\) corresponds to a threshold and \(a_j\) to a loading.
logistic_2pl <- function(theta, a, b) {
1 / (1 + exp(-1.702 * a * (theta - b)))
}
x <- seq(-4, 4, length.out = 1000)
normal_df <- data.frame(
x = x,
default = logistic_2pl(x, 1, 0),
easy = logistic_2pl(x, 1.5, -1),
hard = logistic_2pl(x, 0.5, 1)
)
ggplot(normal_df) +
geom_line(aes(x = x, y = default, color = "default (b=0, a=1)")) +
geom_line(aes(x = x, y = easy, color = "b=-1, a=1.5")) +
geom_line(aes(x = x, y = hard, color = "b=1, a=0.5")) +
scale_color_brewer(palette = "Set2") +
labs(
title = "2PL logistic model",
x = "theta",
y = "P(correct)",
color = "model and settings"
) +
theme_minimal() +
theme(legend.position = "bottom")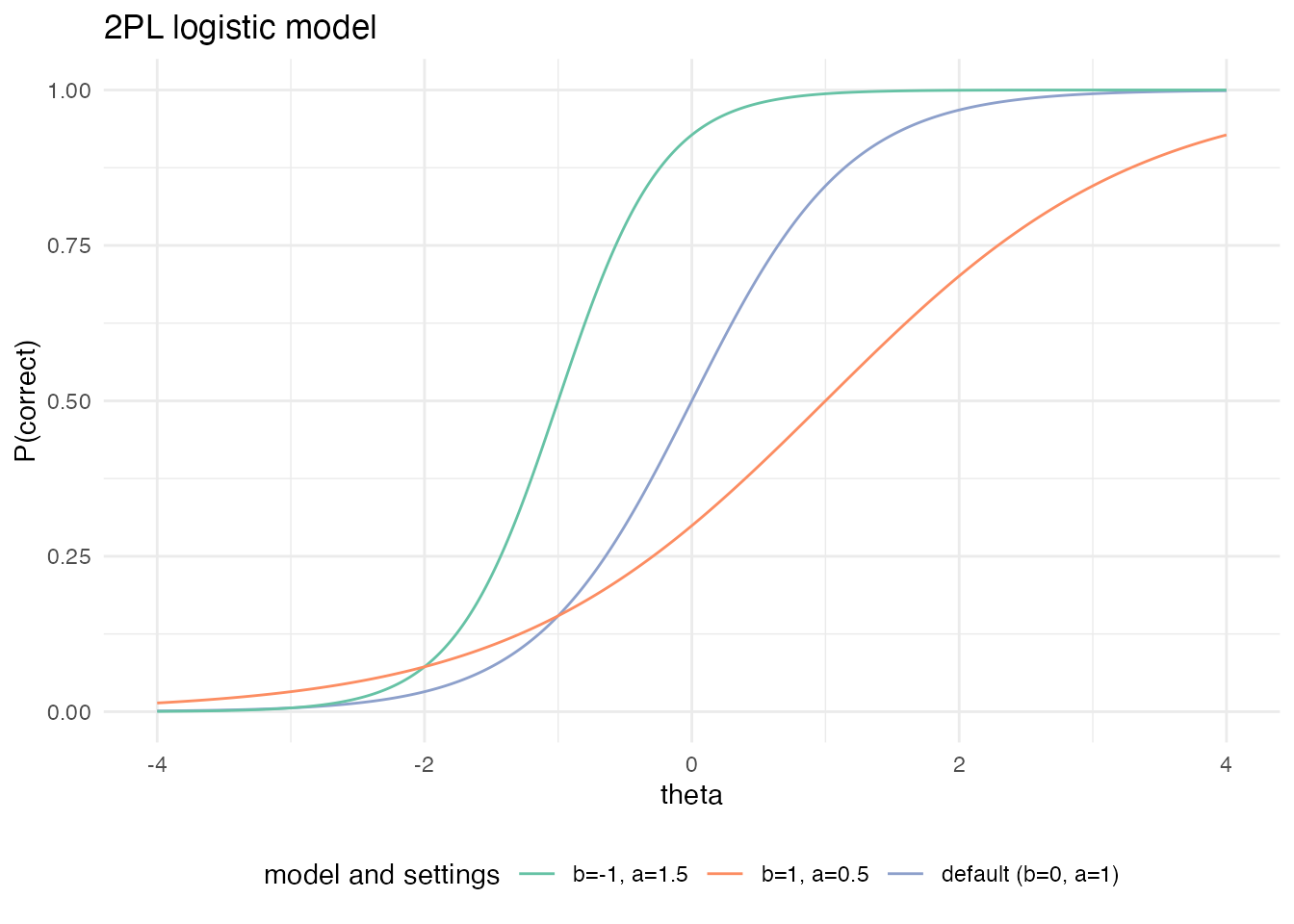
In practice the 2PL is the most common, but 3PL, 4PL, and 5PL models exist:
\[ P(Y_{ij} = 1 \mid \theta_i, a_j, b_j, c_j) = c_j + \frac{1 - c_j}{1 + \exp(-1.702 a_j (\theta_i - b_j))}, \]
\[ P(Y_{ij} = 1 \mid \theta_i, a_j, b_j, c_j, d_j) = c_j + \frac{d_j - c_j}{1 + \exp(-1.702 a_j (\theta_i - b_j))}, \]
\[ P(Y_{ij} = 1 \mid \theta_i, a_j, b_j, c_j, d_j, e_j) = c_j + \frac{d_j - c_j}{\{1 + \exp(-1.702 a_j (\theta_i - b_j))\}^{e_j}}. \]
\(c_j\) is the lower-asymptote parameter (guessing), \(d_j\) the upper-asymptote parameter, and \(e_j\) the asymmetry parameter. More parameters demand larger samples for estimation and complicate operational use (e.g., equating across forms), so these are not widely used.
The logistic curve characterizing an item is the item response function (IRF) or item characteristic curve (ICC). Several R packages fit IRT models — ltm, exametrika, and others. We use the author’s own exametrika package and its sample data. J15S500 is data from 500 respondents answering 15 items.
pacman::p_load(exametrika)
result.2pl <- IRT(J15S500, model = 2, verbose = FALSE)
print(result.2pl)Item Parameters
slope location PSD(slope) PSD(location)
Item01 0.698 -1.683 0.1093 0.266
Item02 0.810 -1.552 0.1166 0.221
Item03 0.559 -1.838 0.0988 0.338
Item04 1.416 -1.178 0.1569 0.113
Item05 0.681 -2.242 0.1152 0.360
Item06 0.997 -2.162 0.1499 0.273
Item07 1.084 -1.039 0.1281 0.130
Item08 0.694 -0.558 0.1002 0.153
Item09 0.347 1.630 0.0766 0.427
Item10 0.492 -1.421 0.0907 0.306
Item11 1.122 1.020 0.1314 0.124
Item12 1.216 1.031 0.1385 0.117
Item13 0.875 -0.720 0.1111 0.133
Item14 1.200 -1.232 0.1407 0.134
Item15 0.823 -1.203 0.1127 0.180
Item Fit Indices
model_log_like bench_log_like null_log_like model_Chi_sq null_Chi_sq
Item01 -263.524 -240.190 -283.343 46.669 86.307
Item02 -252.914 -235.436 -278.949 34.954 87.025
Item03 -281.083 -260.906 -293.598 40.353 65.383
Item04 -205.851 -192.072 -265.962 27.558 147.780
Item05 -232.072 -206.537 -247.403 51.070 81.732
Item06 -173.930 -153.940 -198.817 39.981 89.755
Item07 -252.039 -228.379 -298.345 47.320 139.933
Item08 -313.754 -293.225 -338.789 41.057 91.127
Item09 -325.692 -300.492 -327.842 50.399 54.700
Item10 -309.448 -288.198 -319.850 42.500 63.303
Item11 -250.836 -224.085 -299.265 53.501 150.360
Item12 -240.247 -214.797 -293.598 50.900 157.603
Item13 -291.816 -262.031 -328.396 59.571 132.730
Item14 -224.330 -204.953 -273.212 38.754 136.519
Item15 -273.120 -254.764 -302.847 36.713 96.166
model_df null_df NFI RFI IFI TLI CFI RMSEA AIC CAIC
Item01 12 13 0.459 0.414 0.533 0.488 0.527 0.076 22.669 -39.906
Item02 12 13 0.598 0.565 0.694 0.664 0.690 0.062 10.954 -51.621
Item03 12 13 0.383 0.331 0.469 0.414 0.459 0.069 16.353 -46.222
Item04 12 13 0.814 0.798 0.885 0.875 0.885 0.051 3.558 -59.017
Item05 12 13 0.375 0.323 0.440 0.384 0.432 0.081 27.070 -35.505
Item06 12 13 0.555 0.517 0.640 0.605 0.635 0.068 15.981 -46.595
Item07 12 13 0.662 0.634 0.724 0.699 0.722 0.077 23.320 -39.255
Item08 12 13 0.549 0.512 0.633 0.597 0.628 0.070 17.057 -45.518
Item09 12 13 0.079 0.002 0.101 0.002 0.079 0.080 26.399 -36.177
Item10 12 13 0.329 0.273 0.405 0.343 0.394 0.071 18.500 -44.076
Item11 12 13 0.644 0.615 0.700 0.673 0.698 0.083 29.501 -33.075
Item12 12 13 0.677 0.650 0.733 0.709 0.731 0.081 26.900 -35.675
Item13 12 13 0.551 0.514 0.606 0.570 0.603 0.089 35.571 -27.004
Item14 12 13 0.716 0.692 0.785 0.765 0.783 0.067 14.754 -47.822
Item15 12 13 0.618 0.586 0.706 0.678 0.703 0.064 12.713 -49.862
BIC
Item01 -27.906
Item02 -39.621
Item03 -34.222
Item04 -47.017
Item05 -23.505
Item06 -34.595
Item07 -27.255
Item08 -33.518
Item09 -24.177
Item10 -32.076
Item11 -21.075
Item12 -23.675
Item13 -15.004
Item14 -35.822
Item15 -37.862
Model Fit Indices
value
model_log_like -3890.655
bench_log_like -3560.005
null_log_like -4350.217
model_Chi_sq 661.300
null_Chi_sq 1580.424
model_df 180.000
null_df 195.000
NFI 0.582
RFI 0.547
IFI 0.656
TLI 0.624
CFI 0.653
RMSEA 0.073
AIC 301.300
CAIC -637.330
BIC -457.330Numerically, the Item Parameters block reports the slope (discrimination) and the location (difficulty) with their standard errors. Item Fit Indices gives per-item fit; Model Fit Indices gives test-level fit. Viewed through the lens of SEM fit indices, IRT models tend to fit poorly — a price of modeling binary data, in part.
IRT’s strength is less in the numerical fit and more in the ease of visualizing items. exametrika::plot() draws the IRFs:
plot(result.2pl, item = 1:5, type = "IRF", overlay = TRUE)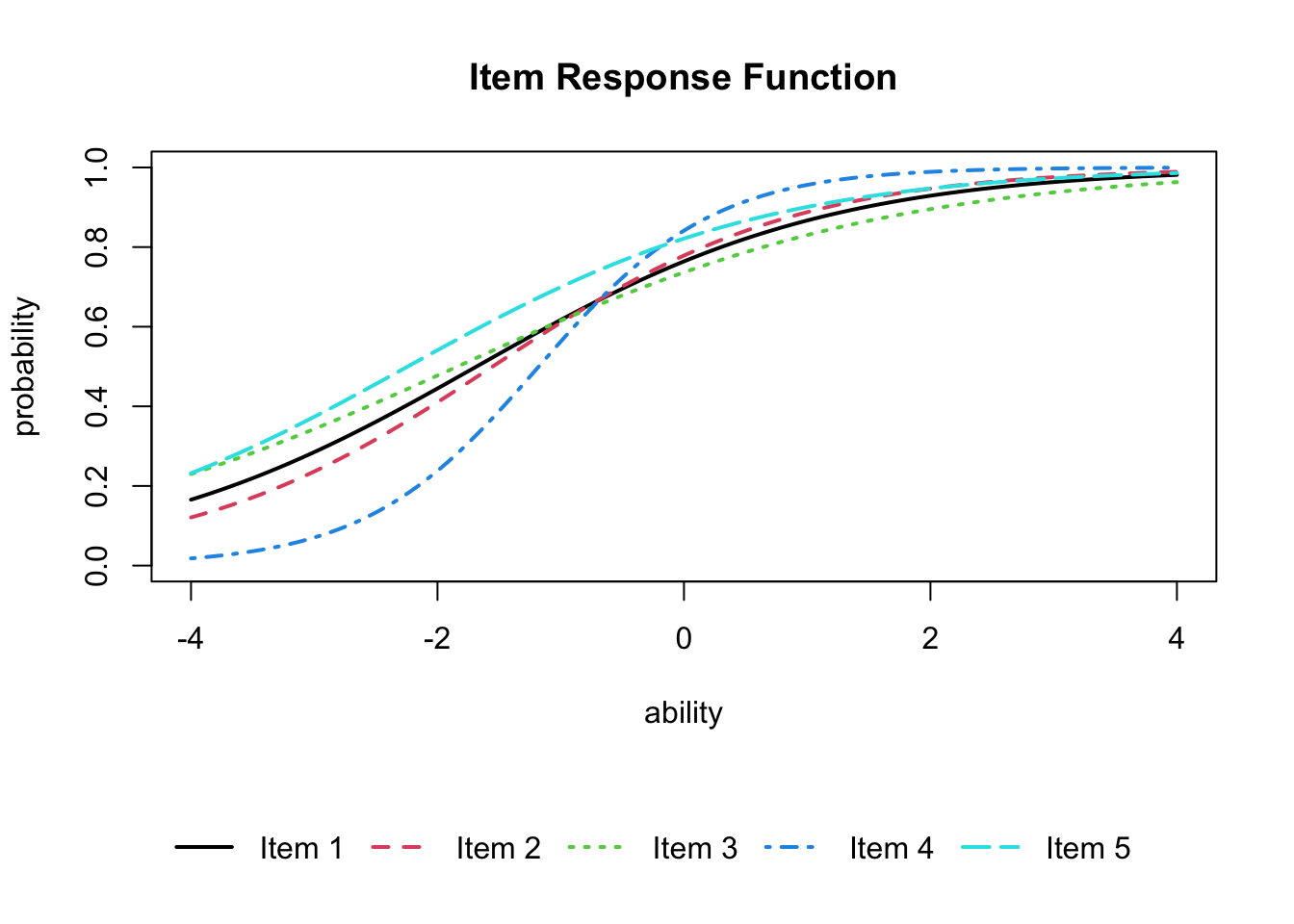
Summing the IRFs across the whole test gives the test response function (TRF):
plot(result.2pl, type = "TRF")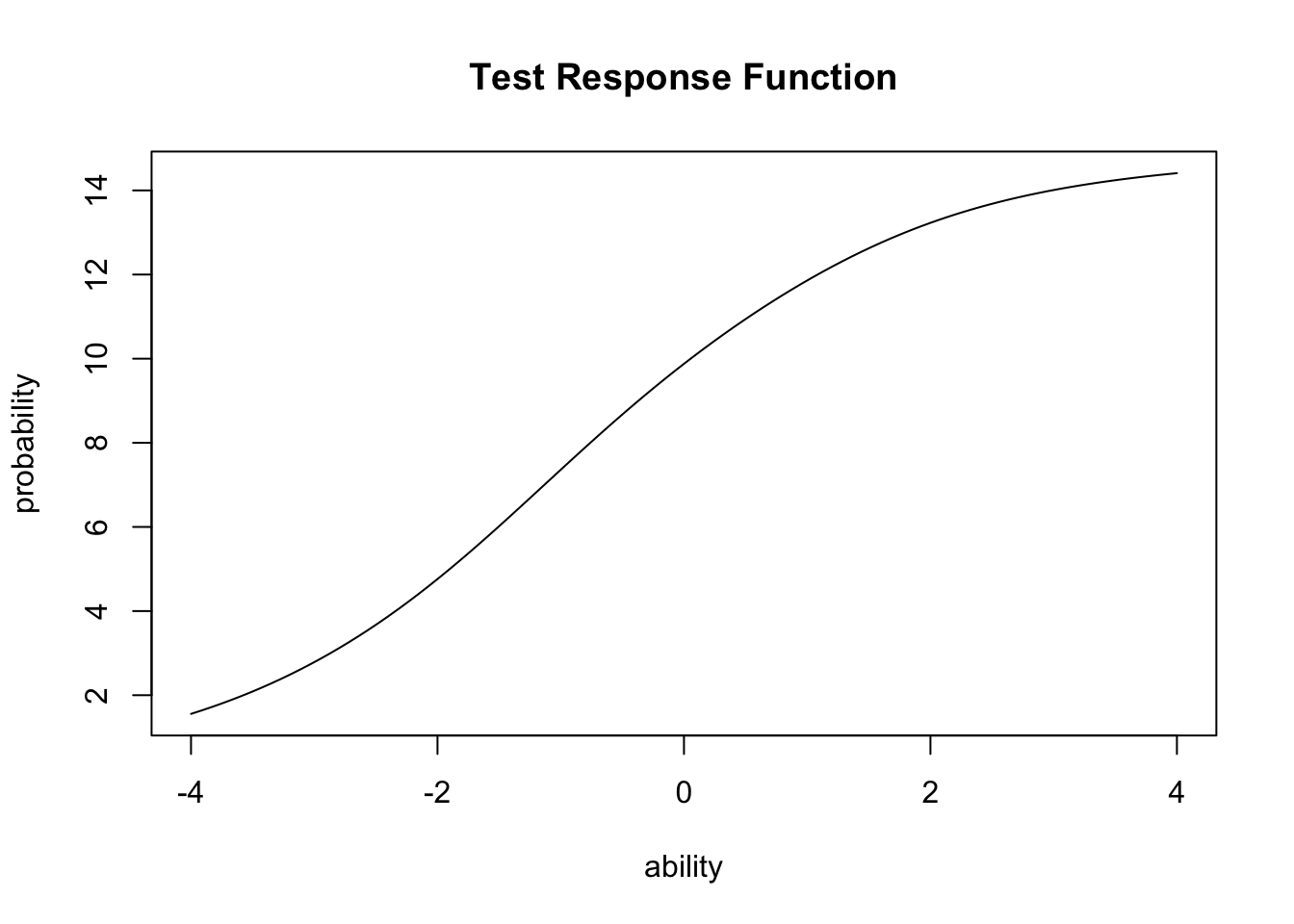
A transformation of the IRF yields the item information function (IIF). The IIF peaks where the variance is greatest — at \(P = 0.5\) — and is defined by
\[ I_j(\theta) = \frac{P_j^{\prime}(\theta)^2}{P_j(\theta)\bigl(1 - P_j(\theta)\bigr)}. \]
Roughly, the larger the gap between correct- and incorrect-response probabilities, the more information the item carries. Plot with type = "IIF":
plot(result.2pl, item = 4, type = "IRF")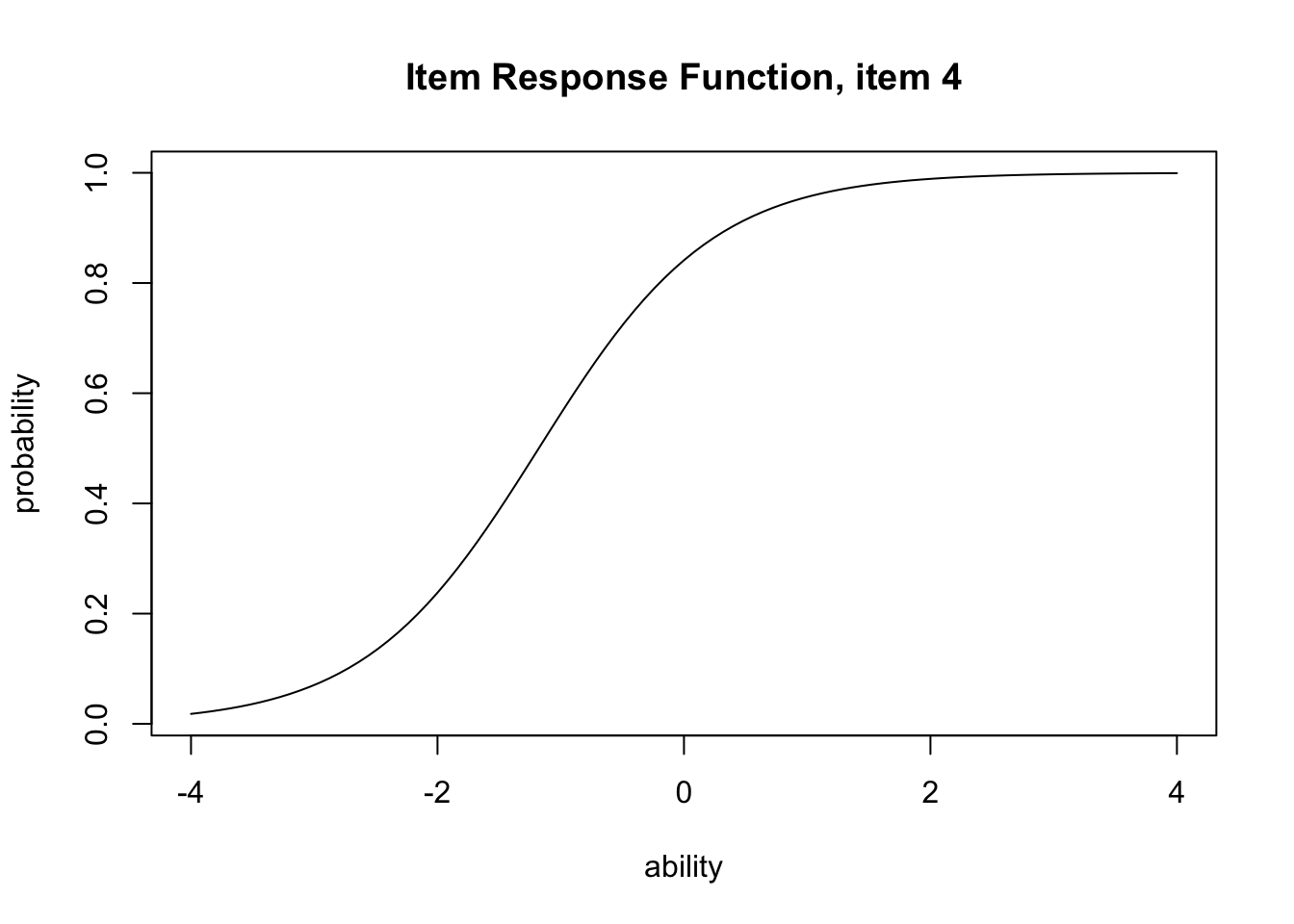
plot(result.2pl, item = 4, type = "IIF")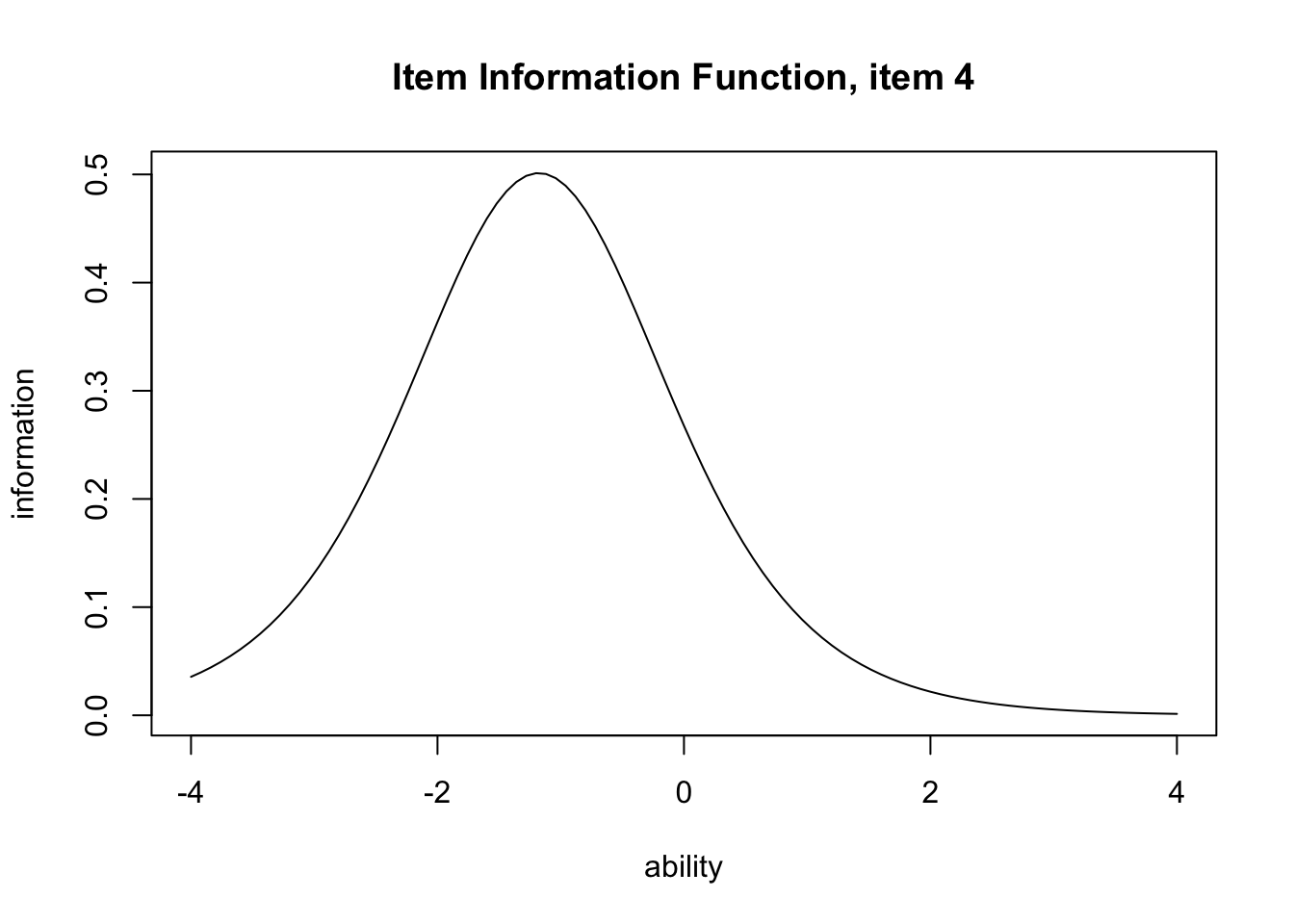
The IIF encodes IRT’s notion of reliability: reliability is a function of \(\theta\), telling us where in the ability range the item works most efficiently.
For contrast, classical test theory expresses reliability as the proportion of true-score variance in the overall test; factor analysis expresses it via item-level communality \(h_j^2\). CTT goes from the test to the items; modern test theory goes the other way and evaluates per-function, per-item performance.
In IRT, even items that are too easy or too hard are not deleted: they are needed to assess high- or low-ability respondents. Such items will not contribute much variance, and may have low communalities, but they are kept — a philosophical contrast with the factor-analytic approach.
The whole-test information function is the sum of per-item IIFs. Use type = "TIF":
plot(result.2pl, type = "TIF")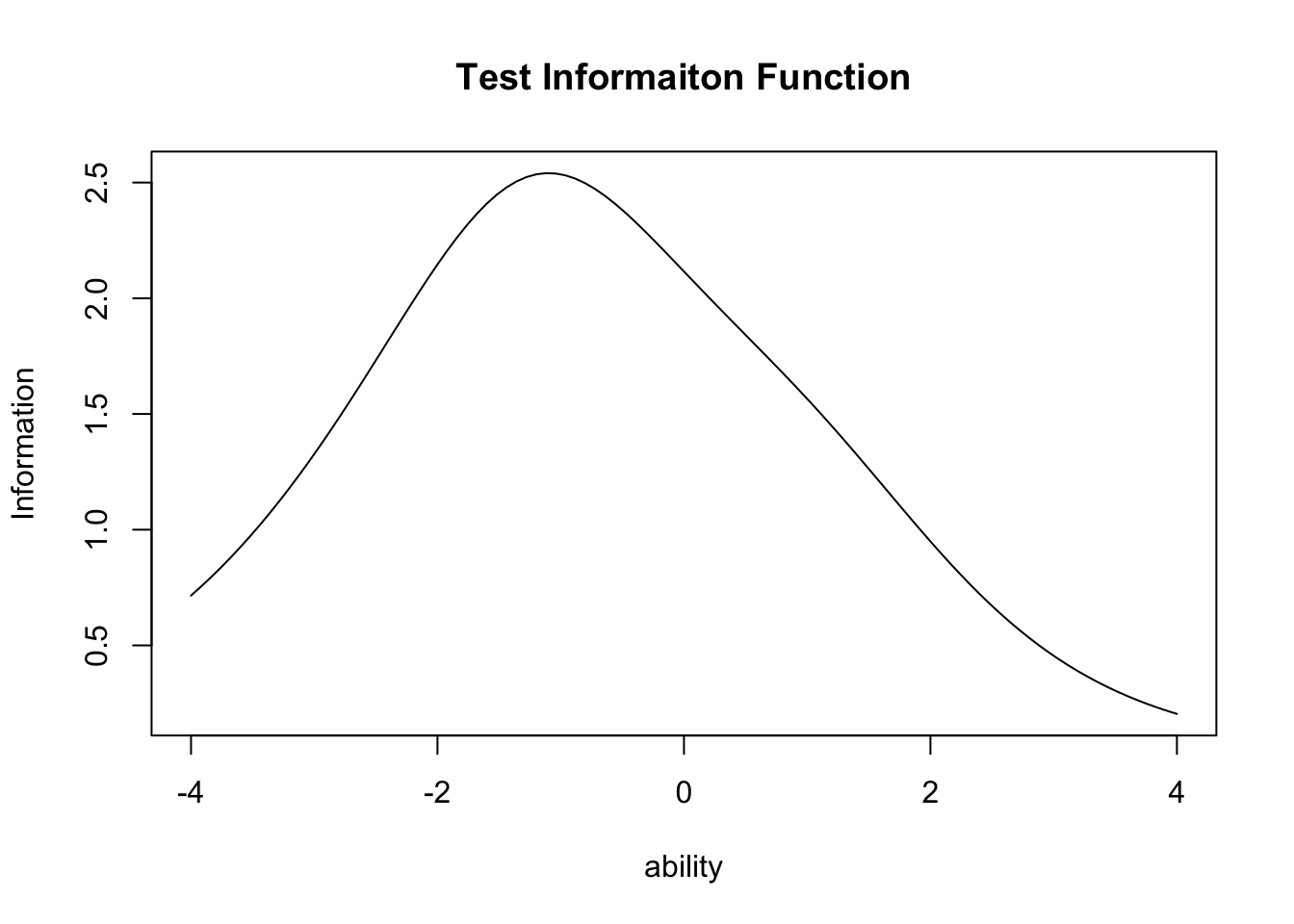
This 15-item test peaks near \(\theta = -1\) — it offers its sharpest measurement for respondents of somewhat-below-average ability. When item parameters are known for a large pool, IRT lets the test designer engineer the precision in advance by selecting items.
The person parameter \(\theta\) is estimated from the response pattern. A standard-normal prior with Bayesian estimation is typical.7 exametrika returns these along with the item parameters:
head(result.2pl$ability) ID EAP PSD
1 Student001 -0.66456781 0.5457047
2 Student002 -0.14853699 0.5626979
3 Student003 0.01362532 0.5699764
4 Student004 0.58775685 0.6012839
5 Student005 -0.97796872 0.5415527
6 Student006 0.85892501 0.6187224IRT is fundamentally for binary data, but models for graded and multi-category responses exist. For Likert-style multi-step responses, the graded response model (GRM) and the partial credit model (PCM) are common. These let one assume an ordinal level of measurement on psychological-scale data.
Psychological scales’ Likert-style responses are typically thought to support, at best, ordinal-level measurement, yet they have long been treated as interval-level for mathematical convenience (and for the unflattering reason that anything more careful was thought unwarranted). One reason this “treat as interval” practice persisted was that GRM/PCM were unavailable in mainstream packages. Today the mathematical equivalence of GRM and the 2PL means common software (e.g., Mplus) can estimate them as the same latent-variable model, and R packages such as ltm provide GRM and PCM. “We don’t have the tools” is no longer a valid excuse.
A further advantage of graded-response modeling is in choosing the right number of response categories. Five-point and seven-point Likert items are common conventions but lack any theoretical justification; the more important question is whether respondents can actually discriminate between 5 or 7 categories.8
A concrete example using ltm::grm() on the Science dataset — science-attitude items on a 4-point scale.
pacman::p_load(ltm)
data(Science)
result.grm <- grm(Science)
print(result.grm)
Call:
grm(data = Science)
Coefficients:
Extrmt1 Extrmt2 Extrmt3 Dscrmn
Comfort -10.768 -5.645 3.097 0.411
Environment -2.154 -0.790 0.627 1.570
Work 32.102 9.261 -24.402 -0.074
Future -30.602 -11.806 10.455 0.108
Technology -2.462 -0.885 0.642 1.650
Industry -2.870 -1.529 0.286 1.642
Benefit -21.232 -5.982 10.297 0.136
Log.Lik: -2998.129The output reports three thresholds (Extrmt) and the corresponding discrimination (Dscrmn). Like the logistic model, GRM admits IRF/IIF/TIF plots; we draw the IRF (called ICC in ltm):
plot(result.grm, items = 2, type = "ICC")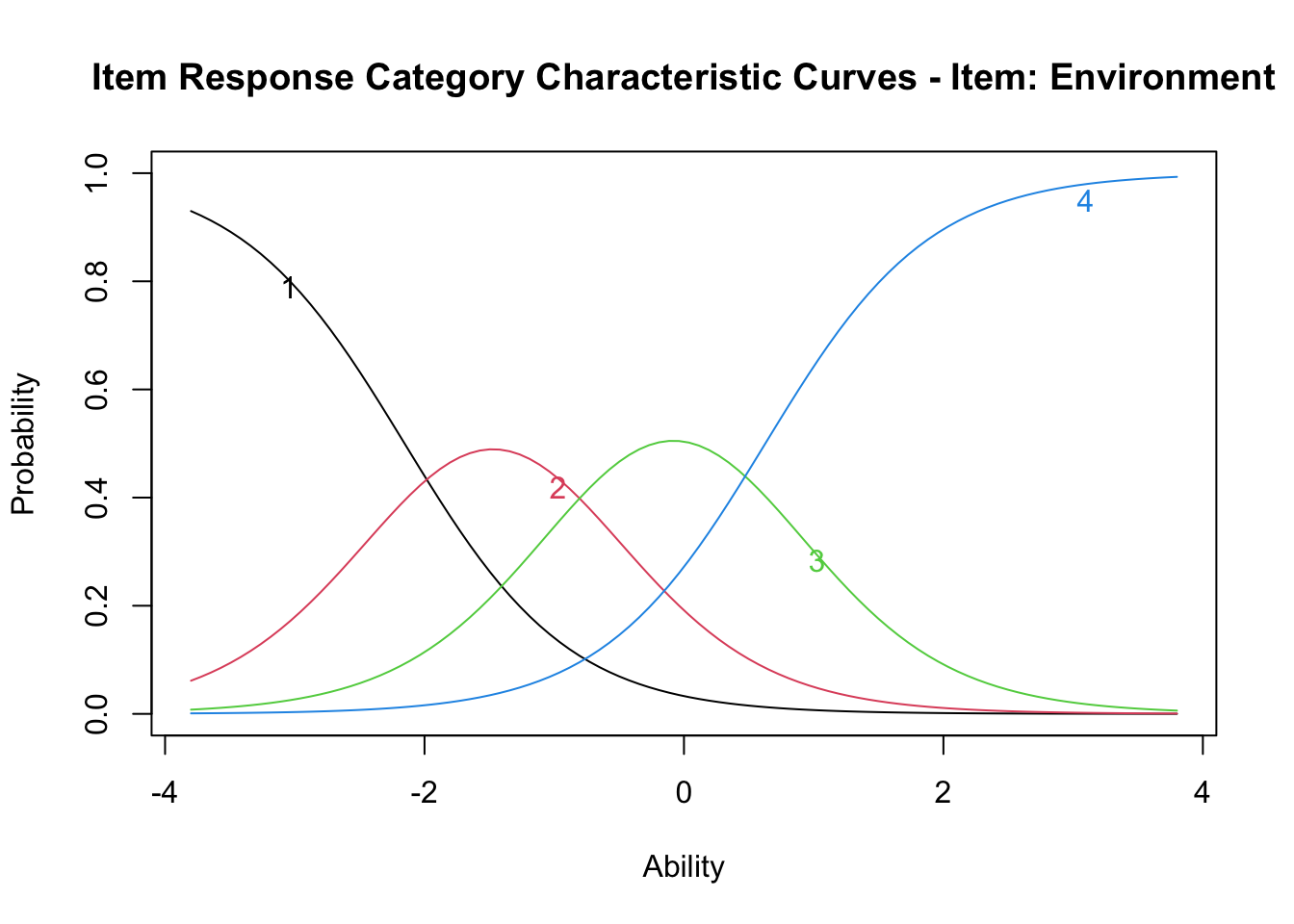
Each category’s response probability is plotted as a function of \(\theta\). As \(\theta\) rises, the modal category shifts from 1 to 2 to 3, in order.
The next item, however, looks different:
plot(result.grm, items = 1, type = "ICC")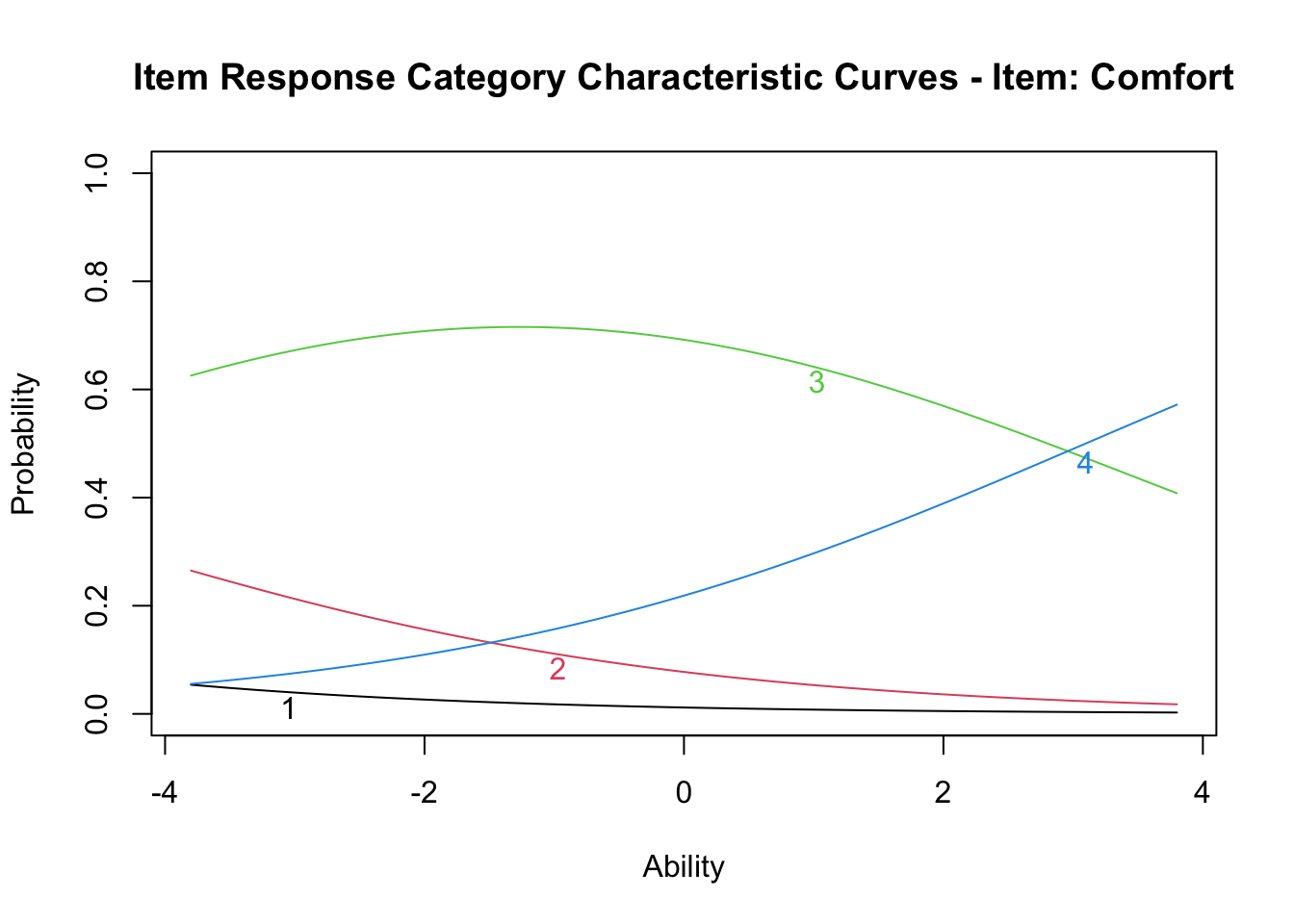
Categories 1 and 2 never become the modal response; nearly the whole range is dominated by category 3, with category 4 only beginning to appear above \(\theta = 3\). The plot spans \(-4 \leq \theta \leq +4\); expanding the negative side might recover category-1 and -2 modes, but that is not realistic. Some items have no clear category modes, suggesting that the response scale was poorly designed.
The IRT approach is increasingly recommended for designing psychological scales. The single-factor assumption can also be relaxed; multidimensional IRT models exist (the mirt package provides them). There is no longer a reason not to use the IRT approach.
We have covered the basics and the practice of exploratory factor analysis, confirmatory factor analysis (under SEM), and item response theory.
Their common thread is constructing measurement models with latent variables, grounded in covariance or correlation matrices. With tetrachoric/polychoric/polyserial correlations for ordinal scales, the analysis becomes a categorical factor analysis — which is also a (graded) IRT model. Software capable of computing correlations appropriate to the level of measurement can run these models with the same workflow (lavaan lets you set the scale level of each variable; Mplus is also well known for this).
Knowing the historical roots and theoretical lineage of each model informs its application, but as a user one should use whichever tool fits the task. Design research with the respondent in mind. Letting mathematical limitations, software constraints, or — worst of all — a researcher’s incomprehension or laziness force respondents into ill-fitting designs degrades the quality of the data.
Practice the multivariate techniques of this chapter on the following problems, which aim to deepen understanding through hands-on analysis. As an example we use psych::small.msq — the Motivational State Questionnaire — a 14-variable, 200-case dataset.9
Its 14 variables comprise energetic arousal (active, alert, arousal, sleepy, tired, drowsy), tense arousal (anxious, jittery, nervous, calm, relaxed, at.ease), plus gender and drug (a drug-condition factor). Excluding gender and drug, the structure is presumed two-factor.
Perform an exploratory factor analysis.
Steps:
Fit a two-factor model with lavaan. Use ordered = TRUE in the model specification to treat the indicators as ordinal.
Steps:
lavaan.Apply ltm’s GRM. Because GRM assumes unidimensionality, split the data into the energetic-arousal and tense-arousal item sets and fit a GRM to each.
Steps:
Use mirt (multidimensional IRT) to fit a two-factor graded model:
pacman::p_load(mirt)
# two factors, graded response
result.mirt <- mirt(dat, model = 2, itemtype = "graded")
# oblique rotation in the summary
summary(result.mirt, rotate = "geominQ")
# multidimensional ICC
plot(result.mirt, type = "trace", which.items = 1)
# multidimensional information
plot(result.mirt, type = "info")Complexity is the index of how cleanly each item loads on a single factor: values near 1 mean the item loads essentially on one factor; larger values mean the item is spread across multiple factors. For loadings \(a_{jk}\), complexity is \((\sum_k a_{jk}^2)^2 / \sum_k a_{jk}^4\).↩︎
An idiosyncratic name; “lavaan” stands for LAtent VAriable ANalysis.↩︎
The lavaangui package lets you specify models via a GUI.↩︎
Std.all standardizes both observed and latent variables to unit variance; Std.lv standardizes only the latent variables.↩︎
Japan’s national university-entrance examinations briefly considered CAT but rejected it: the need for a huge item pool (requiring extensive pre-testing) and the difficulty of providing the same network and operating environment at remote and island sites as in urban areas made it impractical. The existing paper-and-pencil (mark-sheet) system runs an extraordinary error rate below one percent even with 500,000 simultaneous test-takers each year; given its social impact, CAT adoption demands extreme caution.↩︎
It is also possible, of course, to model with the normal CDF directly.↩︎
With MLE, a respondent who gets everything right or everything wrong has an infinite \(\theta\) estimate — not practically useful.↩︎
Frequently asked: “If the prior literature uses 5 points, do we have to?” and “Can we mix 5-point and 7-point scales?” The correct answers: if you are using the prior literature’s scoring or standardization, follow the prior literature; otherwise (e.g., when running EFA and setting your own loadings), design the scale around what respondents can actually distinguish. If you do not know in advance, use a graded-response IRT model to check responses to each category.↩︎
A subset of the more than 2,500 sample MSQ; the full data are in the psychTools package.↩︎