これまで,二群の平均値差を比べる\(t\) 検定,三群以上を比べる分散分析(ANOVA)を扱ってきた。これらはいずれも,「群の間で平均値に差があるとはいえない」という帰無仮説を立て,\(t\) 値や\(F\) 値といった検定統計量を計算し,その確率(\(p\) 値)が小さければ帰無仮説を棄却する,という頻度主義的な手続きであった。
この章では,まったく同じ問題をベイズ統計の観点から捉え直してみる。すなわち,「データはどのようなメカニズムで生まれたのか」というデータ生成の視点からモデルを組み立て,平均値や差の大きさを確率分布として直接見積もるのである。さらに,差があるかないかという判断(意思決定)について,ベイズ的なアプローチである ROPE ,ベイズファクター ,事後予測分布 の三つの道具を紹介する。
なお本章では,ベイズ統計の活用の章で導入したbrmsと,ベイジアンモデリングの章で扱ったStanによる確率モデルの記述の両方を用いる。これらの章の内容を前提とするので,必要に応じて読み返してほしい。
検定からモデリングへ
\(t\) 検定や分散分析は,「平均値の差の検定」と総称される。ここで行われていたことを改めて振り返ると,正規分布に従うと仮定されたデータについて,その平均値に差があるかどうか,より正確には「すべての群の母平均が等しい」と仮定したときに手元のデータ(が示す差)がどれほど生じやすいか,を評価していたのであった。
データ生成メカニズムの観点から見ると,この手続きはごく限定的な一面しか見ていない。平均値以外のパラメータを考えることはできないのか。特定の群間の差だけを取り出すことはできないのか。差があるかないかだけでなく,どれぐらいの差があるのか,一方が他方より大きい確率はどれぐらいか,といったことを直接問うことはできないのか。ベイズ推定は,こうした問いに自然な形で答えを与える。
多重比較の問題が生じない
頻度主義的な分散分析を思い出してほしい。三群以上を比較して有意差が得られた場合,帰無仮説\(H_0: \mu_1 = \mu_2 = \mu_3\) が否定されただけで,「どこに差があるのか」はまだわからない。そこで多重比較へと進むのであったが,検定を繰り返すとタイプ1エラーが増大する。\(\alpha=0.05\) で検定していても,独立な検定を二回繰り返せば\(1-(0.95^2)=0.0975\) と,全体としての誤り率は\(5\%\) を大きく上回ってしまう。そのため,テューキー法やボンフェローニ法のように有意水準を調整する工夫が必要だったのである。
ところがベイズ推定の場合,こうした多重性の問題は生じない。なぜなら,確率を伴う二分判断(YesかNoか)を繰り返しているわけではないからである。頻度主義の\(p\) 値は「帰無仮説が正しいという条件のもとで」計算された検定統計量の生じやすさであって,パラメータがどこにあるかという確率ではない。これに対しベイズ推定で得られる事後分布は,パラメータがこのあたりにあるだろう,という確率そのものである。だから\(A\) 群と\(B\) 群の差,\(A\) 群と\(C\) 群の差,というように好きなだけ差の分布を眺めてよいし,「何度も比べたから誤りが増える」という心配は原理的に存在しない。複雑な要因計画を考えるとき,この性質は非常に助けになる。
分散分析の組成を思い出す
ベイズのモデルを組む前に,分散分析がデータの変動をどう分解していたかを思い出しておこう。これがそのままデータ生成モデルになるからである。
分散分析では,あるデータ\(x_{ij}\) (第\(j\) 群の第\(i\) 番目の観測値)を次のように考える。
\[ x_{ij} = \mu + \delta_j + e_{ij} \]
ここで\(\mu\) は全体平均,\(\delta_j\) は第\(j\) 群に属することの効果(全体平均からのずれ),\(e_{ij}\) は個体差・誤差である。三つのクラスの試験の平均点を比べる例でいえば,全体平均が\(60\) 点で,あるクラスの平均が\(68\) 点だったなら,そのクラスに属したことの効果\(\delta_j\) は\(+8\) 点ということになる。効果は全体平均からの相対的なずれなので,すべての群の効果を足し合わせると\(0\) になる(\(\sum_j \delta_j = 0\) )。これが,水準数が\(3\) なのに効果の自由度が\(2\) になる理由であった。
頻度主義の分散分析では,この効果\(\delta_j\) の二乗を群のサイズ分だけ足し合わせた「群間変動」と,誤差\(e_{ij}\) の二乗を足し合わせた「群内変動」を,それぞれの自由度で割って比べ,その比率\(F\) が大きければ「差がある」と判断していた。
ベイズの観点では,この分解の式そのものを,データを生み出す確率モデルとして読み直す。すなわち,誤差\(e_{ij}\) が平均\(0\) ,標準偏差\(\sigma\) の正規分布に従うと考えれば,
\[ x_{ij} \sim N(\mu + \delta_j, \sigma) \]
となる。あとは,未知数である全体平均\(\mu\) ,効果\(\delta_j\) ,誤差の大きさ\(\sigma\) を,データから推定すればよい。頻度主義が「変動を分解して比率を取る」ことに注力したのに対し,ベイズは「効果\(\delta_j\) そのものの分布」を直接求めにいくのである。
二群の平均値差をベイズで(\(t\) 検定)
まずは最も単純な,二群の平均値差,すなわち\(t\) 検定に対応するモデルから始めよう。
カバーストーリーとして,ある学習法の効果を考える。同じ範囲の内容を,異なる三つの学習法(方法A,方法B,方法C)で学んだ受講者に,共通のテストを受けてもらった。各群\(40\) 名である。まずはこのうち方法Aと方法Cの二群だけを取り出して比較してみよう。
データは,分散分析の組成の式にもとづいて生成する。全体平均\(60\) 点に,方法Aは\(+8\) 点,方法Bは\(+6\) 点,方法Cは\(-14\) 点の効果があり(合計\(0\) ),そこに標準偏差\(8\) 点の誤差が乗るものとする。
:: p_load (tidyverse, cmdstanr, bayesplot, bayestestR, brms, logspline)options (brms.backend = "cmdstanr" )set.seed (1234 )<- 60 # 全体平均 <- c (8 , 6 , - 14 ) # 各群の効果(合計0) <- 8 # 誤差の標準偏差 <- 40 # 各群のサンプルサイズ <- c ("方法A" , "方法B" , "方法C" )<- tibble (method = factor (rep (labels, each = N), levels = labels),score = c (rnorm (N, gm + eff[1 ], sigma_true),rnorm (N, gm + eff[2 ], sigma_true),rnorm (N, gm + eff[3 ], sigma_true)|> mutate (idx = as.integer (method))|> group_by (method) |> summarise (平均 = mean (score), 標準偏差 = sd (score), n = n ())
# A tibble: 3 × 4
method 平均 標準偏差 n
<fct> <dbl> <dbl> <int>
1 方法A 64.7 7.30 40
2 方法B 65.4 8.67 40
3 方法C 46.4 6.32 40
群ごとの平均値を見ると,手元のデータでは方法Aと方法Bがほぼ同じ程度で,方法Cだけが低い,という結果になっている。母集団では方法Aと方法Bに\(2\) 点の差をつけて生成したのだが,標本のばらつきによって,得られたデータ上ではほとんど差がなくなっている。このあたりの「標本だからこその揺らぎ」も,ベイズ推定がどう扱うか見どころである。
Stanによるモデルの記述
二群比較のStanコードは次のようになる。これをbayes_ttest.stanという名前で保存しておく。
data {int <lower =0 > N1; // 第1群のサンプルサイズ int <lower =0 > N2; // 第2群のサンプルサイズ array [N1] real X1; // 第1群の観測値 array [N2] real X2; // 第2群の観測値 parameters {real mu1; // 第1群の母平均 real mu2; // 第2群の母平均 real <lower =0 > sigma; // 共通の標準偏差(等分散の仮定) model {// 尤度:各群が同じ散らばりを持つ正規分布から生じる // 事前分布 50 , 50 );50 , 50 );0 , 5 );generated quantities {real diff; // 平均値差そのもの real delta; // 標準化した効果量(Cohen's d 相当) array [N1 + N2] real X_pred; // 事後予測分布のための複製データ for (i in 1 : N1) {for (i in 1 : N2) {dataブロックでは,二つの群それぞれのサンプルサイズと観測値を受け取る。parametersブロックには,二つの母平均mu1,mu2と,共通の標準偏差sigmaを置いた。ここで標準偏差を共通にしているのは,\(t\) 検定でいう「等分散の仮定」に対応する。modelブロックでは,各群のデータがそれぞれの母平均を中心とする正規分布から生じたという尤度を記述し,事前分布を与えている。
注目すべきはgenerated quantitiesブロックである。ここでは平均値差そのものdiffと,それを標準偏差で割って標準化した効果量delta(Cohen’s \(d\) に相当)を計算している。検定と違って,差の大きさを確率分布として直接得られるのがベイズの強みである。さらにX_predとして,推定されたモデルから新しいデータを生成しておく。これは後述する事後予測分布に用いる。
推定と結果の読み取り
このモデルをコンパイルし,方法Aと方法Cのデータを与えて推定する。
<- dat |> filter (method %in% c ("方法A" , "方法C" ))<- sub$ score[sub$ method == "方法A" ]<- sub$ score[sub$ method == "方法C" ]<- cmdstan_model ("bayes_ttest.stan" )<- model_t$ sample (data = list (N1 = length (X1), N2 = length (X2), X1 = X1, X2 = X2),chains = 4 , parallel_chains = 4 ,iter_warmup = 1000 , iter_sampling = 2000 ,refresh = 0 , save_cmdstan_config = TRUE
Running MCMC with 4 parallel chains...
Chain 1 finished in 0.1 seconds.
Chain 2 finished in 0.1 seconds.
Chain 3 finished in 0.1 seconds.
Chain 4 finished in 0.1 seconds.
All 4 chains finished successfully.
Mean chain execution time: 0.1 seconds.
Total execution time: 0.2 seconds.
$ summary (c ("mu1" , "mu2" , "sigma" , "diff" , "delta" ))
# A tibble: 5 × 10
variable mean median sd mad q5 q95 rhat ess_bulk ess_tail
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 mu1 64.7 64.7 1.13 1.12 62.8 66.5 1.00 8594. 5383.
2 mu2 46.4 46.4 1.11 1.13 44.6 48.2 1.00 7999. 6340.
3 sigma 6.87 6.85 0.556 0.556 6.03 7.83 1.00 6844. 5527.
4 diff 18.3 18.3 1.58 1.56 15.7 20.9 1.00 8728. 5529.
5 delta 2.68 2.68 0.314 0.312 2.17 3.22 1.00 7784. 5499.
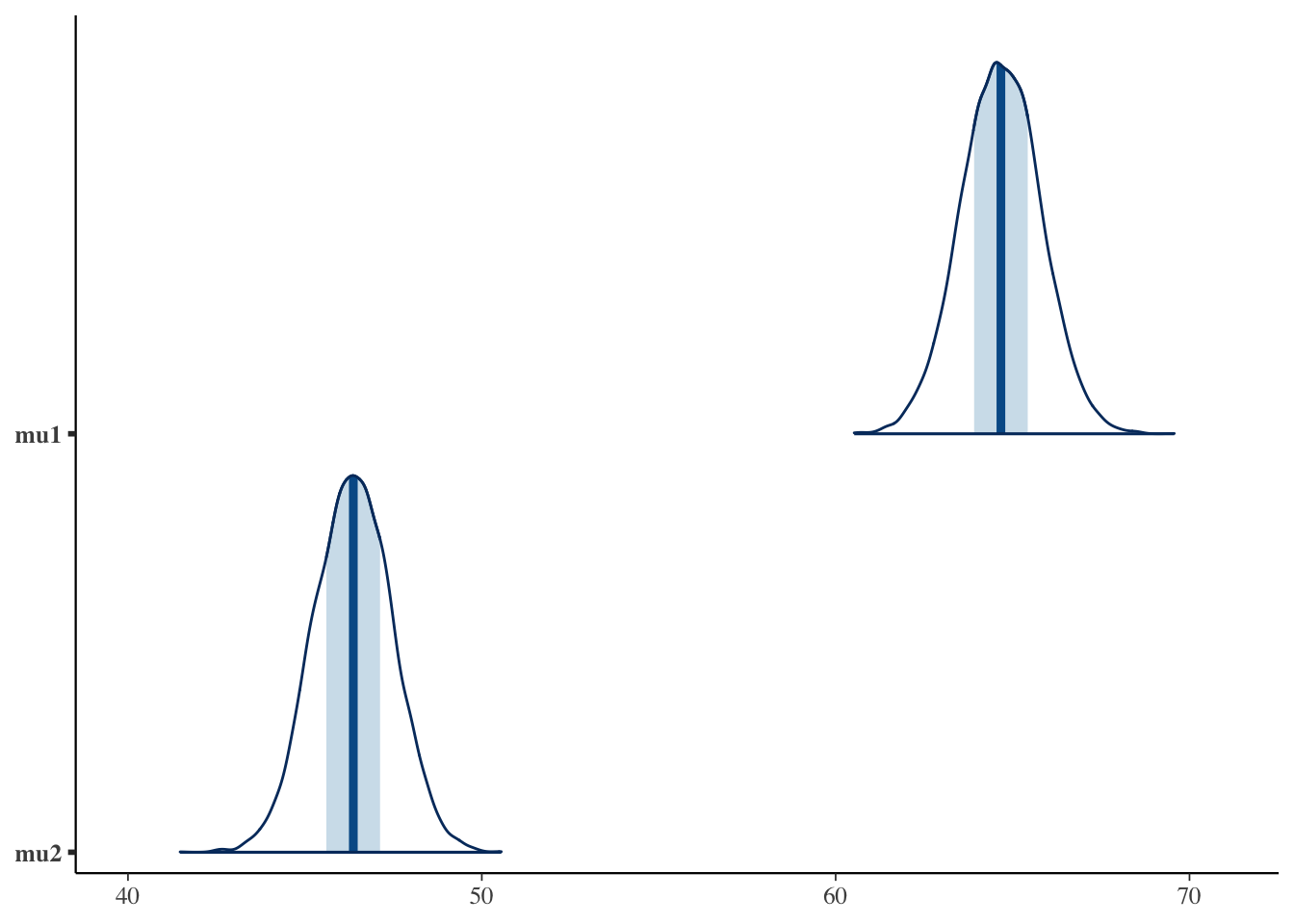
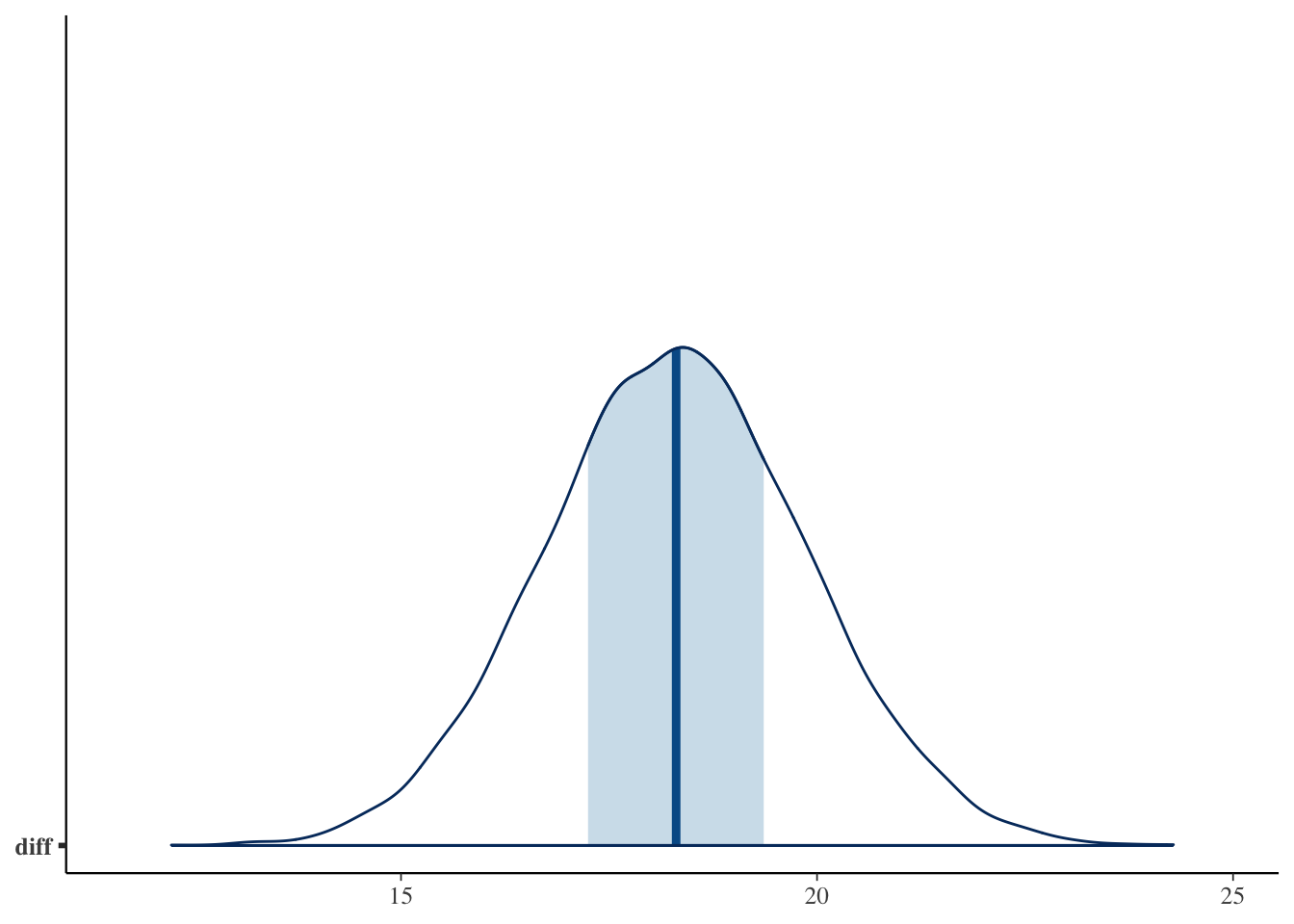
Rhatはいずれも\(1.00\) 付近,ess_bulkも十分大きく,サンプリングはうまくいっている。mu1,mu2が方法A,方法Cの母平均の事後分布の代表値である。注目すべきはdiffで,これは平均値差の事後分布である。点推定としての差だけでなく,その差が\(90\%\) の確率でどの範囲にあるか(q5からq95)まで一目でわかる。標準化効果量deltaも非常に大きく,方法Aと方法Cの間には実質的な差があると考えてよさそうである。
数値だけでなく,事後分布を絵にして眺めるとわかりやすい。bayesplotパッケージのmcmc_areas関数は,パラメータの事後分布を山型の密度で描いてくれる。
# 二群の母平均の事後分布 :: mcmc_areas (fit_t$ draws (c ("mu1" , "mu2" )))# 平均値差の事後分布(破線が差ゼロ) :: mcmc_areas (fit_t$ draws ("diff" )) + :: geom_vline (xintercept = 0 , linetype = "dashed" )
Warning: Removed 1 row containing missing values or values outside the scale range
(`geom_vline()`).
二つの母平均の山がはっきり離れていること,そして差diffの分布が\(0\) (破線)から大きく右に離れていることが一目でわかる。差の山のほぼすべてが正の領域にあるので,先ほどの優越率がほぼ\(1\) だったことも納得できる。
差を確率分布として持っていることの利点は,さまざまな「データレベルの仮説」を後から自由に問える点にある。たとえば「方法Aの母平均が方法Cの母平均より大きい確率」は,差の事後分布のうち正の領域が占める割合として計算できる。これを優越率(probability of superiority)と呼ぶ。
<- fit_t$ draws (format = "df" )# 方法Aが方法Cより大きい確率 mean (draws_t$ diff > 0 )
差のMCMCサンプルのうち正の値が占める割合を数えるだけである。ほぼ\(1\) ,すなわち「方法Aのほうが優れている」とほぼ確実にいえる。頻度主義の\(p\) 値が「帰無仮説のもとでの検定統計量の生じやすさ」という間接的な指標だったのに対し,これは知りたかったことそのものを確率で答えている点に注目してほしい。
多群の平均値差をベイズで(分散分析)
次に三群の比較,すなわち一要因分散分析に対応するモデルを考える。二群モデルを群の数だけ書き足してもよいが,それでは群の数が変わるたびにコードを修正してコンパイルし直すことになる。そこで,先に見た分散分析の組成の式を,群の数によらない一般的な形で書き下す。
すなわち全体平均\(\mu\) (コード中ではgm)と,各群の効果\(\delta_j\) ,誤差\(\sigma\) でモデルを構成する。ただし効果には\(\sum_j \delta_j = 0\) という制約があったから,推定するのは\(\mathrm{Lv}-1\) 個の効果だけでよく,最後の一つは「総和が\(0\) になるように」決まる。
Stanによるモデルの記述
整然データ(tidy data)の形でデータを与えることを前提にした,群の数によらないコードが次である。bayes_anova.stanとして保存しておく。
data {int <lower =0 > Lv; // 水準数(群の数) int <lower =0 > L; // データの総数 array [L] int <lower =1 , upper =Lv> idx; // 各データが属する群のID array [L] real X; // 観測値 parameters {real gm; // 全体平均(grand mean) array [Lv - 1 ] real raw_delta; // 効果。自由度の関係で Lv-1 個 real <lower =0 > sigma; // 群内の散らばり(誤差) transformed parameters {array [Lv] real delta; // 総和が0になるよう作り直した効果 array [Lv] real mu; // 各群の母平均 for (l in 1 : (Lv - 1 )) {// 最初の Lv-1 個はコピー // 最後の1つは「効果の総和=0」から決まる for (l in 1 : Lv) {// 各群の平均 = 全体平均 + 効果 model {// 尤度:l 番目のデータは,その群の平均 mu[idx[l]] を中心に散らばる for (l in 1 : L) {// 事前分布 50 , 50 );0 , 50 );0 , 5 );generated quantities {array [L] real X_pred; // 事後予測分布のための複製データ for (l in 1 : L) {dataブロックでは,水準数Lv,データ総数Lに加え,各データがどの群に属するかを示すインデックスidxと観測値Xを,いずれも長さLの配列で受け取る。これにより,群ごとのサンプルサイズが異なっていても対応できる。
parametersブロックには全体平均gm,効果raw_delta(\(\mathrm{Lv}-1\) 個),誤差sigmaを置いた。transformed parametersブロックでは,raw_deltaの最初の\(\mathrm{Lv}-1\) 個をそのままコピーし,最後の一つを-sum(raw_delta)として総和が\(0\) になるよう作り直すことで効果\(\delta_j\) を完成させ,各群の平均mu[l] = gm + delta[l]を構成している。
modelブロックの尤度は,X[l] ~ normal(mu[idx[l]], sigma)の一行で,\(l\) 番目のデータがその群idx[l]の平均を中心に散らばる,という関係を表している。mu[idx[l]]という入れ子の参照によって,どの群に属するデータかを指定しているのである。generated quantitiesブロックでは,二群のときと同様に事後予測のための複製データX_predを生成しておく。
推定と全ペアの比較
三群すべてのデータを与えて推定する。
<- cmdstan_model ("bayes_anova.stan" )<- model_a$ sample (data = list (Lv = 3 , L = nrow (dat), idx = dat$ idx, X = dat$ score),chains = 4 , parallel_chains = 4 ,iter_warmup = 1000 , iter_sampling = 2000 ,refresh = 0 , save_cmdstan_config = TRUE
Running MCMC with 4 parallel chains...
Chain 1 finished in 0.2 seconds.
Chain 2 finished in 0.2 seconds.
Chain 3 finished in 0.2 seconds.
Chain 4 finished in 0.2 seconds.
All 4 chains finished successfully.
Mean chain execution time: 0.2 seconds.
Total execution time: 0.3 seconds.
$ summary (c ("gm" , "mu[1]" , "mu[2]" , "mu[3]" ,"delta[1]" , "delta[2]" , "delta[3]" , "sigma" ))
# A tibble: 8 × 10
variable mean median sd mad q5 q95 rhat ess_bulk ess_tail
<chr> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
1 gm 58.8 58.8 0.684 0.684 57.7 59.9 1.00 7525. 5741.
2 mu[1] 64.7 64.7 1.17 1.15 62.7 66.6 1.00 6765. 5555.
3 mu[2] 65.4 65.4 1.20 1.19 63.4 67.3 1.00 7005. 5621.
4 mu[3] 46.4 46.4 1.19 1.16 44.4 48.3 1.00 8793. 6423.
5 delta[1] 5.88 5.88 0.964 0.952 4.28 7.43 1.00 6157. 5834.
6 delta[2] 6.56 6.55 0.978 0.984 4.95 8.16 1.00 6594. 5307.
7 delta[3] -12.4 -12.4 0.970 0.979 -14.0 -10.9 1.00 10361. 6105.
8 sigma 7.54 7.51 0.499 0.493 6.77 8.39 1.00 7794. 5961.
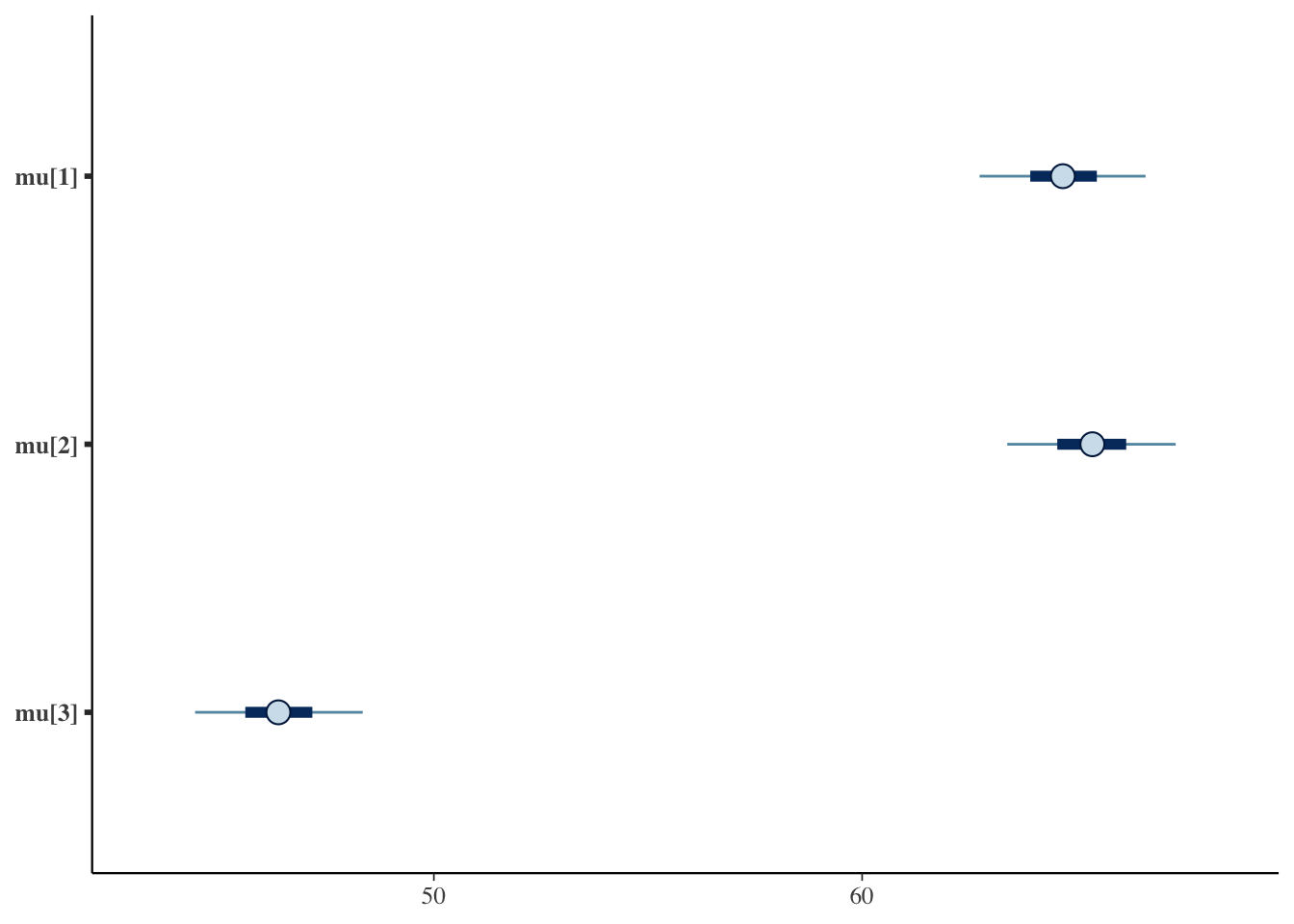
gmが全体平均,mu[1]からmu[3]が各群の母平均,delta[1]からdelta[3]が各群の効果の事後分布である。効果を見ると,方法A・方法Bが正,方法Cが大きく負であり,データの生成構造をおおむね復元できている。
これも可視化してみよう。各群の母平均は区間表示(mcmc_intervals),効果は密度(mcmc_areas)で描く。
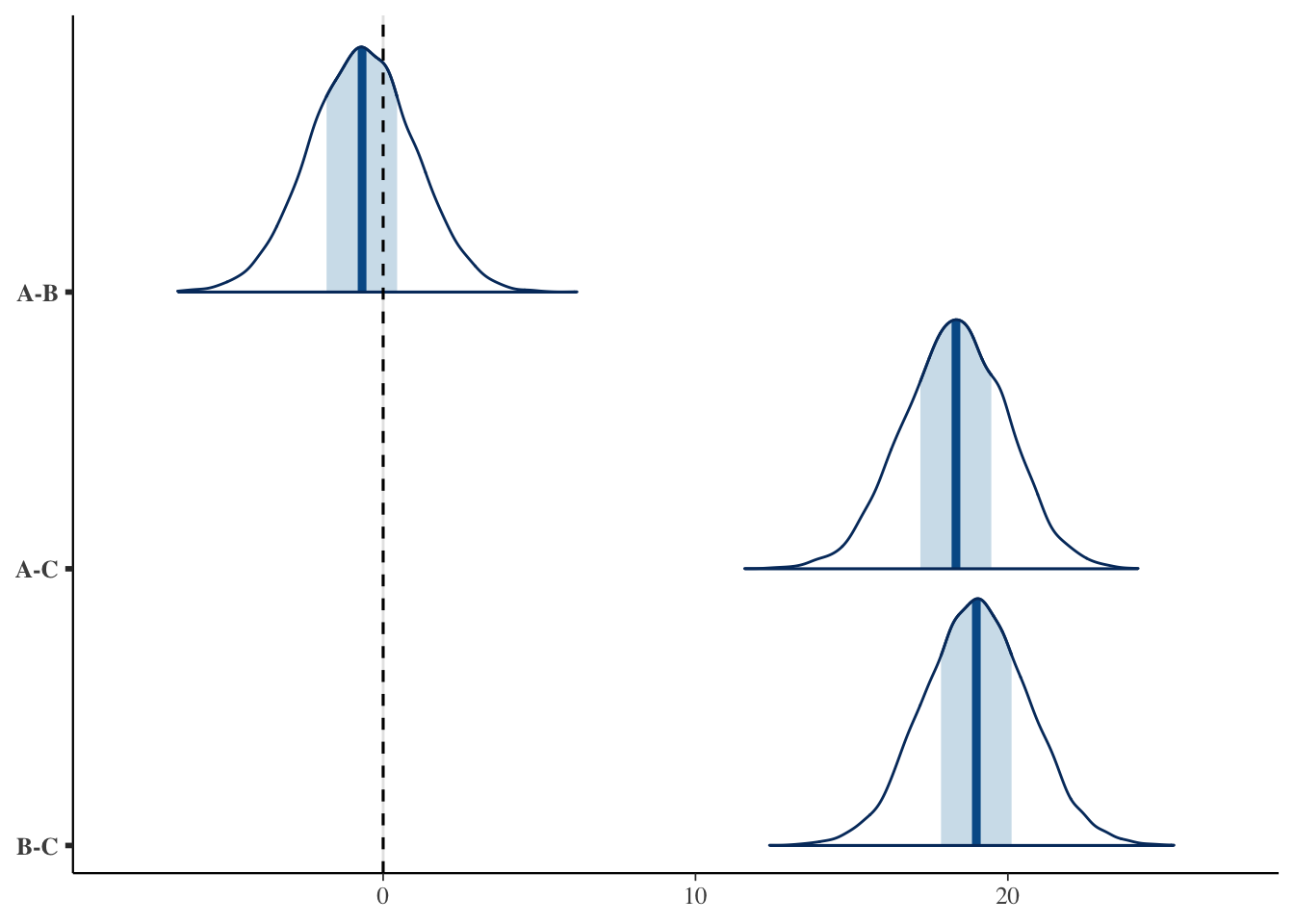
# 各群の母平均(点と区間) :: mcmc_intervals (fit_a$ draws (c ("mu[1]" , "mu[2]" , "mu[3]" )))# 各群の効果(破線が効果ゼロ) :: mcmc_areas (fit_a$ draws (c ("delta[1]" , "delta[2]" , "delta[3]" ))) + :: geom_vline (xintercept = 0 , linetype = "dashed" )
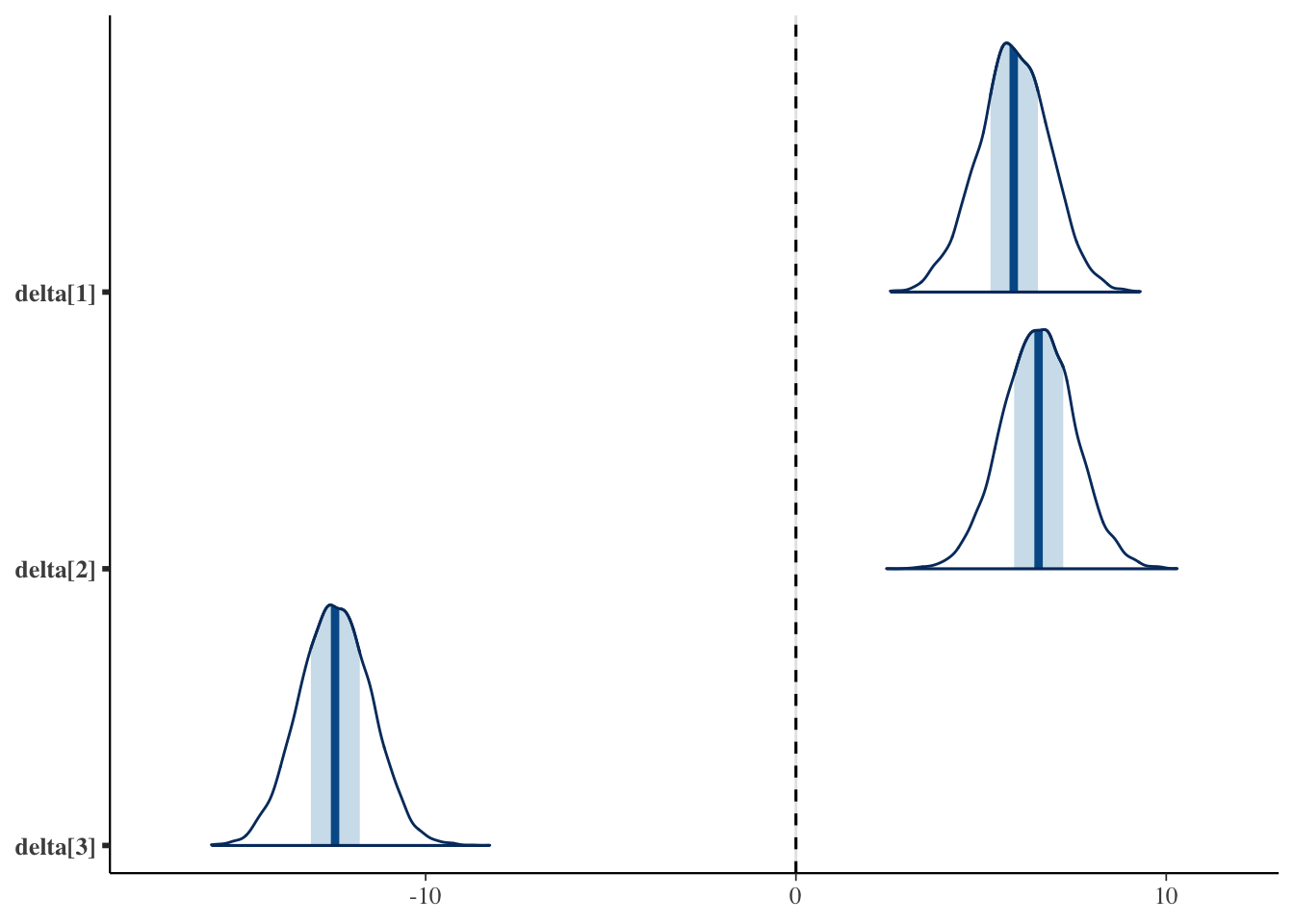
母平均では方法A・方法Bが近い位置に並び,方法Cだけが下にずれている。効果の図でも,方法Cの効果が明確に負側にあるのに対し,方法A・方法Bの効果は\(0\) 付近で重なっていることが見て取れる。
ここで分散分析の後の多重比較に相当することをやってみよう。頻度主義では有意水準の調整が必要だったが,ベイズでは各群の母平均の事後分布(のMCMCサンプル)から,差を引き算するだけでよい。
<- fit_a$ draws (format = "df" )<- tibble (` A-B ` = draws_a$ ` mu[1] ` - draws_a$ ` mu[2] ` ,` A-C ` = draws_a$ ` mu[1] ` - draws_a$ ` mu[3] ` ,` B-C ` = draws_a$ ` mu[2] ` - draws_a$ ` mu[3] ` |> pivot_longer (everything (), names_to = "対" , values_to = "差" ) |> group_by (対) |> summarise (EAP = mean (差),L95 = quantile (差, 0.025 ),U95 = quantile (差, 0.975 ),` P(差>0) ` = mean (差 > 0 )
# A tibble: 3 × 5
対 EAP L95 U95 `P(差>0)`
<chr> <dbl> <dbl> <dbl> <dbl>
1 A-B -0.676 -3.99 2.62 0.346
2 A-C 18.3 15.1 21.5 1
3 B-C 19.0 15.7 22.3 1
結果を見ると,方法Aと方法Cの差,方法Bと方法Cの差は\(95\%\) 区間が\(0\) をまたがず,「差がある」とほぼ確実にいえる(優越率もほぼ\(1\) )。一方で方法Aと方法Bの差は,\(95\%\) 区間が\(0\) をはさんでおり,優越率も\(0.5\) に近い。つまり,この二つの方法には明確な差があるとはいえない,という結果である。母集団では\(2\) 点差をつけて作ったのだが,\(40\) 名ずつのデータからはその差を見分けられなかった,ということになる。
全ペアの差の事後分布を重ねて描くと,どのペアが\(0\) をまたいでいるかがよくわかる。
# 全ペアの差の事後分布(破線が差ゼロ) :: mcmc_areas (as.matrix (pair)) + :: geom_vline (xintercept = 0 , linetype = "dashed" )
方法Aと方法Cの差,方法Bと方法Cの差は,山全体が\(0\) より右に大きく離れている。一方で方法Aと方法Bの差の山は\(0\) をまたいでおり,差があるとはいいきれないことが視覚的に確認できる。
ここで重要なのは,「区間が\(0\) をまたぐから差がない」と即断してはいけない,という点である。これは「差があるとはいえない」のであって,「差がない(同等である)」とは違う。この区別こそが,次に述べる意思決定の道具が必要になる理由である。
意思決定の三つの道具
事後分布が得られたあと,「で,結局どう判断すればよいのか」という問いが残る。頻度主義には「\(p < 0.05\) なら有意」という明快(だが乱用もされてきた)な基準があった。ベイズにはこれに代わる判断の道具がいくつかある。ここでは代表的な三つ,ROPE,ベイズファクター,事後予測分布を見ていく。
ROPE
ROPEはRegion Of Practical Equivalence(実質的同等の領域)の略で,Kruschke (2018 ) によって提唱された判断方法である。考え方はシンプルで,「この範囲に入っていれば,差は実質的にゼロとみなしてよい」という幅をあらかじめ宣言しておく,というものである。
たとえば今回のテスト得点であれば,「\(\pm 2\) 点くらいの差は,実用上は差がないも同然だ」と研究者が判断したとしよう。この\([-2, +2]\) がROPEである。そのうえで,差の事後分布がこのROPEにどれだけ入っているかを見る。
# 方法Aと方法Bの差:実質的同等か? :: rope (pair$ ` A-B ` , range = c (- 2 , 2 ), ci = 1 )
# Proportion of samples inside the ROPE [-2.00, 2.00]:
Inside ROPE
-----------
72.60 %
# 方法Aと方法Cの差:実質的な差があるか? :: rope (pair$ ` A-C ` , range = c (- 2 , 2 ), ci = 1 )
# Proportion of samples inside the ROPE [-2.00, 2.00]:
Inside ROPE
-----------
0.00 %
方法Aと方法Bの差は,その事後分布の大部分(\(7\) 割以上)がROPEの内側に収まっている。つまり「両者の差は実質的に無視できる」と積極的に主張できる。これは頻度主義では原理的に言えなかったこと(帰無仮説の採択)であり,ベイズの大きな利点である。一方,方法Aと方法Cの差はROPEに一切入っておらず,実質的にも明確な差があると判断できる。
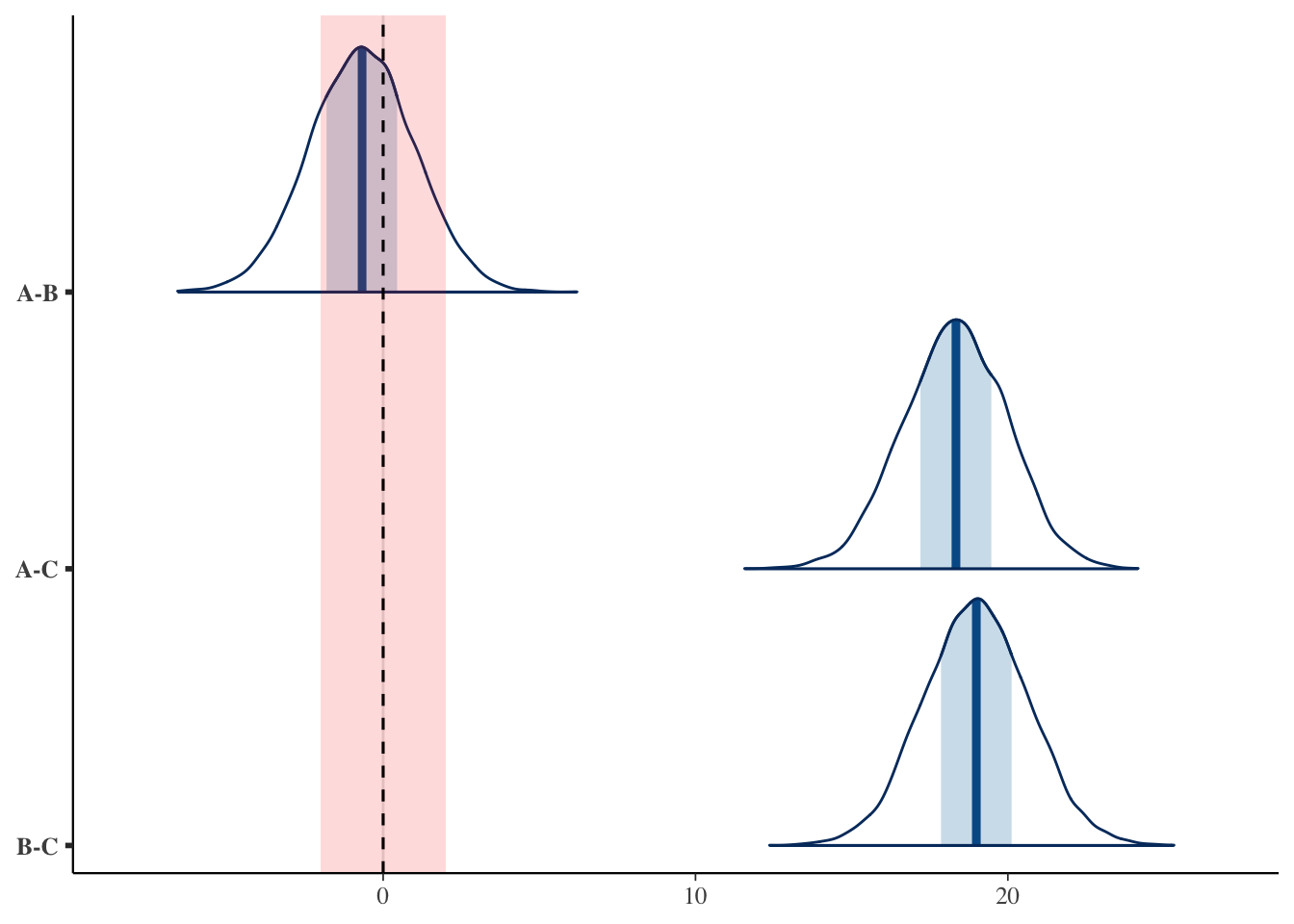
このROPEによる判断も,差の事後分布にROPEの帯を重ねて描くと直感的である。
# 差の事後分布に ROPE [-2, 2] の帯(赤)を重ねる :: mcmc_areas (as.matrix (pair)) + :: annotate ("rect" ,xmin = - 2 , xmax = 2 , ymin = - Inf , ymax = Inf ,alpha = 0.15 , fill = "red" + :: geom_vline (xintercept = 0 , linetype = "dashed" )
赤い帯がROPEである。方法Aと方法Bの差の山は,その大部分が赤い帯の中に収まっている(実質的に同等)。これに対し方法Aと方法C,方法Bと方法Cの差の山は,赤い帯からはるか右に外れている(実質的に差がある)。区間が\(0\) をまたぐかどうかという見方に,ROPEの帯を重ねることで,「差がないとはいえない」のか「実質的に差がない」のかを描き分けられるのである。
ROPEの幅をどう決めるかは研究者の判断であり,分野の知見にもとづくべきものである。基準が思いつかない場合,Kruschke (2018 ) は標準化した尺度で\(\pm 0.1\) 標準偏差を目安として提案している。bayestestRではrange = "default"とすると,この標準化基準にもとづくROPEを自動的に設定してくれる。
ベイズファクター
二つ目の道具はベイズファクター(Bayes Factor, BF)である。これは二つのモデルのどちらがデータをよく説明するかを,相対的な比で表すものである。ベイジアンモデリングの章でも触れたように,ベイズ的なモデル評価はこのBFに一元化できるといってよい。
ここでは,「効果はゼロである(差がない)」というモデルと「効果はゼロでない(差がある)」というモデルを比べる。BFを計算する一つの簡便な方法が,Savage-Dickey密度比である。これは,事前分布と事後分布の,ゼロ点における密度の比を取るというもので,brmsで事前分布もサンプリングしておけばbayestestRで計算できる。
そのためにまず,brmsで同じ分散分析モデルを推定する。Rのformulaにscore ~ methodと書くだけで,内部では全体平均と各群の効果という形のモデルが組まれる。効果コーディング(contr.sum)を指定すると,先ほどStanで推定した効果\(\delta_j\) とほぼ同じものが係数として得られ,答え合わせにもなる。
# 効果コーディング:全体平均からのずれ(効果)として係数を得る contrasts (dat$ method) <- contr.sum (3 )<- brm (~ method,data = dat,prior = set_prior ("normal(0, 50)" , class = "b" ),sample_prior = "yes" , # BFのため事前分布もサンプリング chains = 4 , iter = 11000 , warmup = 1000 ,refresh = 0 , seed = 1
Estimate Est.Error Q2.5 Q97.5
Intercept 58.810085 0.6848841 57.460350 60.157594
method1 5.876573 0.9832975 3.958309 7.811276
method2 6.571917 0.9788995 4.638359 8.501470
method1,method2が方法A,方法Bの効果であり,先ほどStanで得たdelta[1],delta[2]とほぼ一致している。自分で書いたStanモデルと,brmsが自動で組んだモデルが同じ結果を返すことが確認できた。brmsは線型モデルの範囲なら手早く同じ推定ができるので,定型的な分析では便利である。
このモデルからBFを計算する。
:: bayesfactor_parameters (fit_brms, null = 0 )
Sampling priors, please wait...
Bayes Factor (Savage-Dickey density ratio)
Parameter | BF
----------------------
(Intercept) | 9.89e+97
method1 | 1.84e+04
method2 | 3.61e+05
* Evidence Against The Null: 0
method1,method2のBFはいずれも非常に大きな値であり,「効果がゼロ」というモデルに対して「効果がある」というモデルが圧倒的に支持される。一般にBFが\(3\) を超えれば一方のモデルが優っている目安とされるが,ここではそれをはるかに上回っている。
逆に,「差がない(同等である)」ことの証拠もBFで評価できる。方法Aと方法Bの差については,brmsのhypothesis関数で「\(\mu_A - \mu_B = 0\) 」という仮説を検証してみよう。
:: hypothesis (fit_brms, "method1 - method2 = 0" )
Hypothesis Tests for class b:
Hypothesis Estimate Est.Error CI.Lower CI.Upper Evid.Ratio
1 (method1-method2) = 0 -0.7 1.7 -4.02 2.66 38.12
Post.Prob Star
1 0.97
---
'CI': 90%-CI for one-sided and 95%-CI for two-sided hypotheses.
'*': For one-sided hypotheses, the posterior probability exceeds 95%;
for two-sided hypotheses, the value tested against lies outside the 95%-CI.
Posterior probabilities of point hypotheses assume equal prior probabilities.
出力のEvid.Ratioが,「差がない」という仮説を支持するBFである。\(1\) をかなり上回っており,方法Aと方法Bについては「差がない」ほうが支持される。ROPEの結論と整合的である。
サベージ・ディッキー法を絵で見る
Savage-Dickey密度比が何をしているのかは,事前分布と事後分布を重ねて描くとよくわかる。やっていることは単純で,注目するパラメータについて,事前分布と事後分布の,値ゼロにおける密度の高さを比べているだけである。データを見る前(事前分布)に比べて,データを見た後(事後分布)にゼロ点の密度がどれだけ減ったか(または増えたか)を見るのである。ゼロでの密度が減っていれば「効果はゼロでない」証拠,増えていれば「効果はゼロ」の証拠になる。
brmsのフィット結果から事前分布と事後分布のMCMCサンプルを取り出して描いてみよう。事前分布にはnormal(0, 50)を置いたので,描画では解析的な正規分布をそのまま重ねる(二つの効果の差については,独立な二つの効果の差なので事前分布の標準偏差は\(50\sqrt{2}\) になる)。
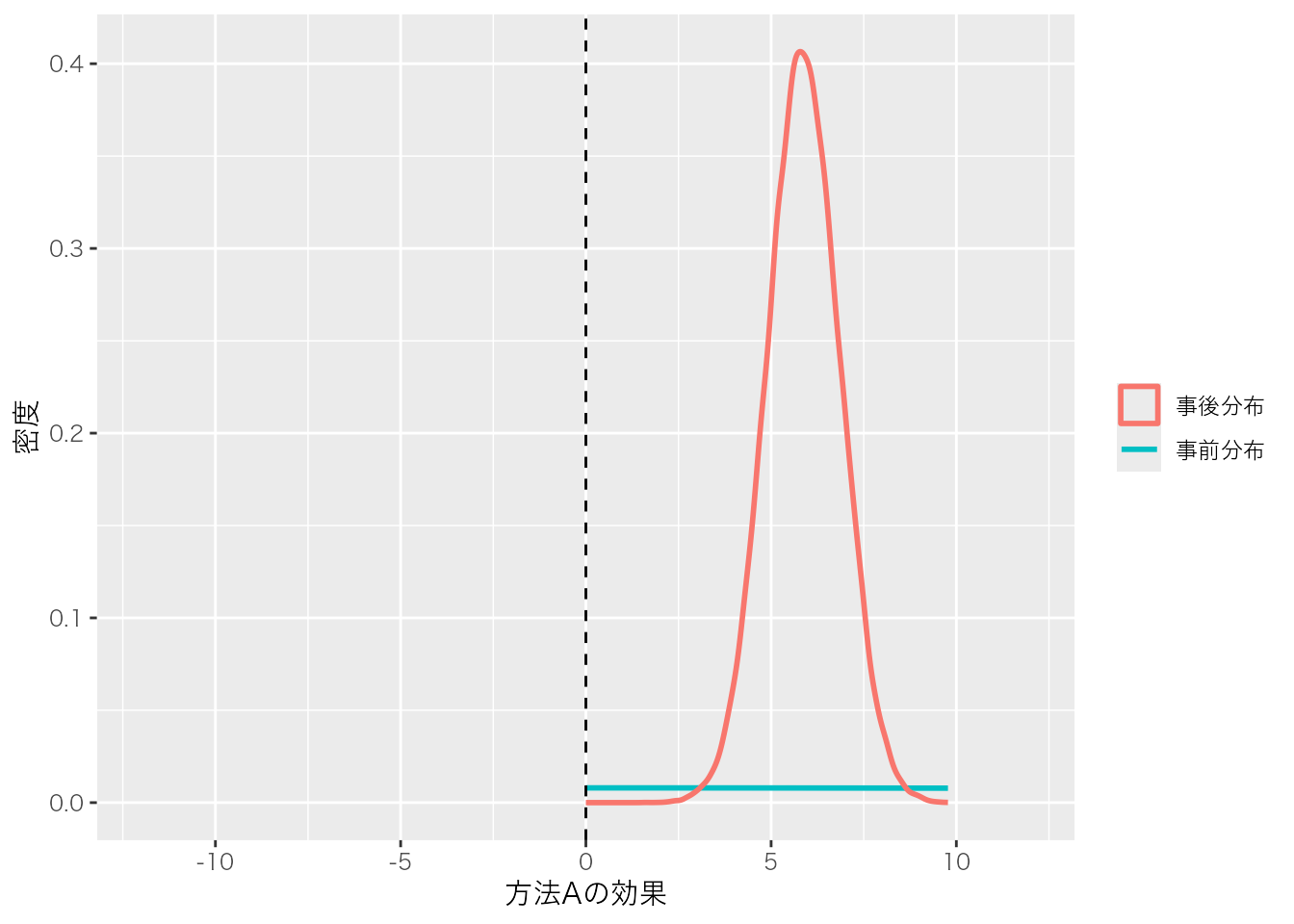
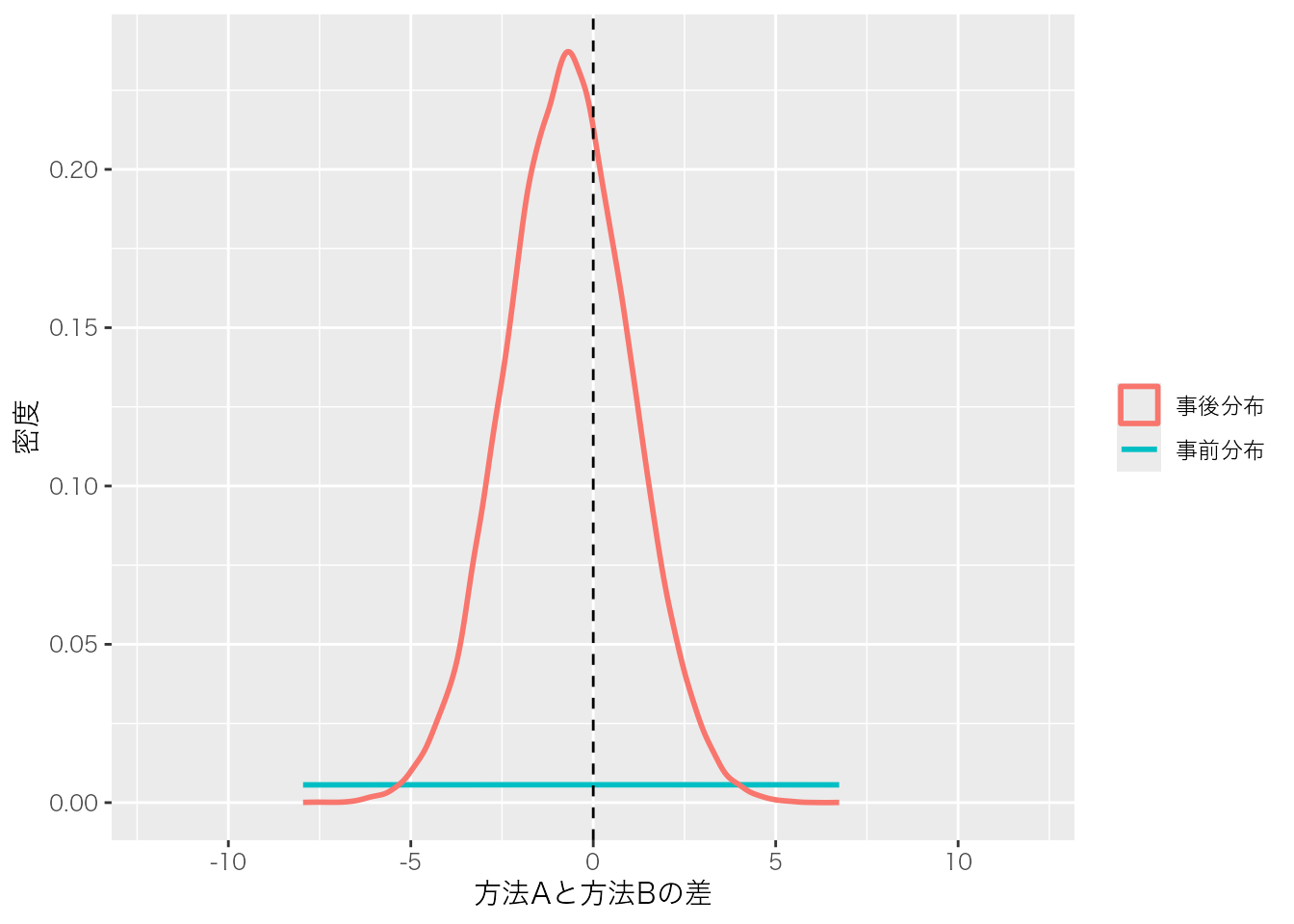
<- brms:: as_draws_df (fit_brms)# サベージ・ディッキー法を絵にする関数 <- function (post, prior_sd, xlim, title) {tibble (value = post) |> ggplot (aes (value)) + # 事前分布(解析的な正規分布) stat_function (fun = dnorm, args = list (mean = 0 , sd = prior_sd),aes (color = "事前分布" ), linewidth = 1 + # 事後分布(MCMCサンプルから推定した密度) geom_density (aes (color = "事後分布" ), linewidth = 1 ) + geom_vline (xintercept = 0 , linetype = "dashed" ) + coord_cartesian (xlim = xlim) + labs (x = title, y = "密度" , color = NULL ) + theme (text = element_text (family = "Hiragino Sans" ))# 方法Aの効果:ゼロ点の密度が大きく減る=「効果はゼロでない」証拠 sd_plot (dd$ b_method1, prior_sd = 50 , xlim = c (- 12 , 12 ), title = "方法Aの効果" )# 方法Aと方法Bの差:ゼロ点に密度が集まる=「差はゼロ」の証拠 sd_plot (dd$ b_method1 - dd$ b_method2,prior_sd = 50 * sqrt (2 ), xlim = c (- 12 , 12 ), title = "方法Aと方法Bの差" )
一枚目の「方法Aの効果」では,平べったい事前分布に対して,事後分布は\(0\) からはっきり右に離れた位置に山を作っている。ゼロ点(破線)における事後分布の高さは,事前分布の高さよりもずっと低くなっている。この高さの比がBFであり,事後分布がゼロ点をほとんど見捨てているので,「効果はゼロでない」という大きなBFになる。
二枚目の「方法Aと方法Bの差」は対照的である。事後分布の山はちょうど\(0\) の真上に乗っており,ゼロ点の高さは事前分布よりも高い。データを見たことで,かえってゼロ点の密度が増えたわけである。だからこのBFは「差はゼロ」を支持する向きになる。先ほどbayesfactor_parametersやhypothesisで得た数値が,この二つの絵の,破線上での高さの比に対応している。
なお,BFには注意も必要である。「\(3\) を超えたら差がある」といった二値判断は,\(p\) 値と同じく過大解釈や基準超えのための不正を招きかねない。またBFは事前分布の置き方によって同じデータでも値が大きく変わることが知られており,事前分布の選択には議論がある。\(t\) 検定や分散分析のような定型的なモデルについては,BayesFactorパッケージや,それをGUIで扱えるJASP(JASP Team 2025 ) がBFを自動計算してくれるので,それらを併用するのもよいだろう。
# BayesFactorパッケージによる古典的なBF(JASPの計算エンジンと同じ) :: p_load (BayesFactor)anovaBF (score ~ method, data = as.data.frame (dat))
事後予測分布
三つ目の道具は事後予測分布(posterior predictive distribution)である。事後予測分布には大きく二つの使い道がある。一つは「そもそも立てたモデルはデータをきちんと再現できているのか」というモデルの妥当性チェック,もう一つは効果の大きさを実際のデータのレベルで評価することである。順に見ていこう。
モデルの妥当性をチェックする
まずは妥当性チェックである。考え方はこうである。推定したパラメータ(の事後分布)を使って,モデルから人工的にデータを生成してみる。もしモデルが適切なら,この人工データ(予測データ)は,実際に観測されたデータとよく似た分布になるはずである。逆に,予測データが実データと食い違っていれば,モデルがデータの何らかの特徴を捉えそこねている,ということになる。
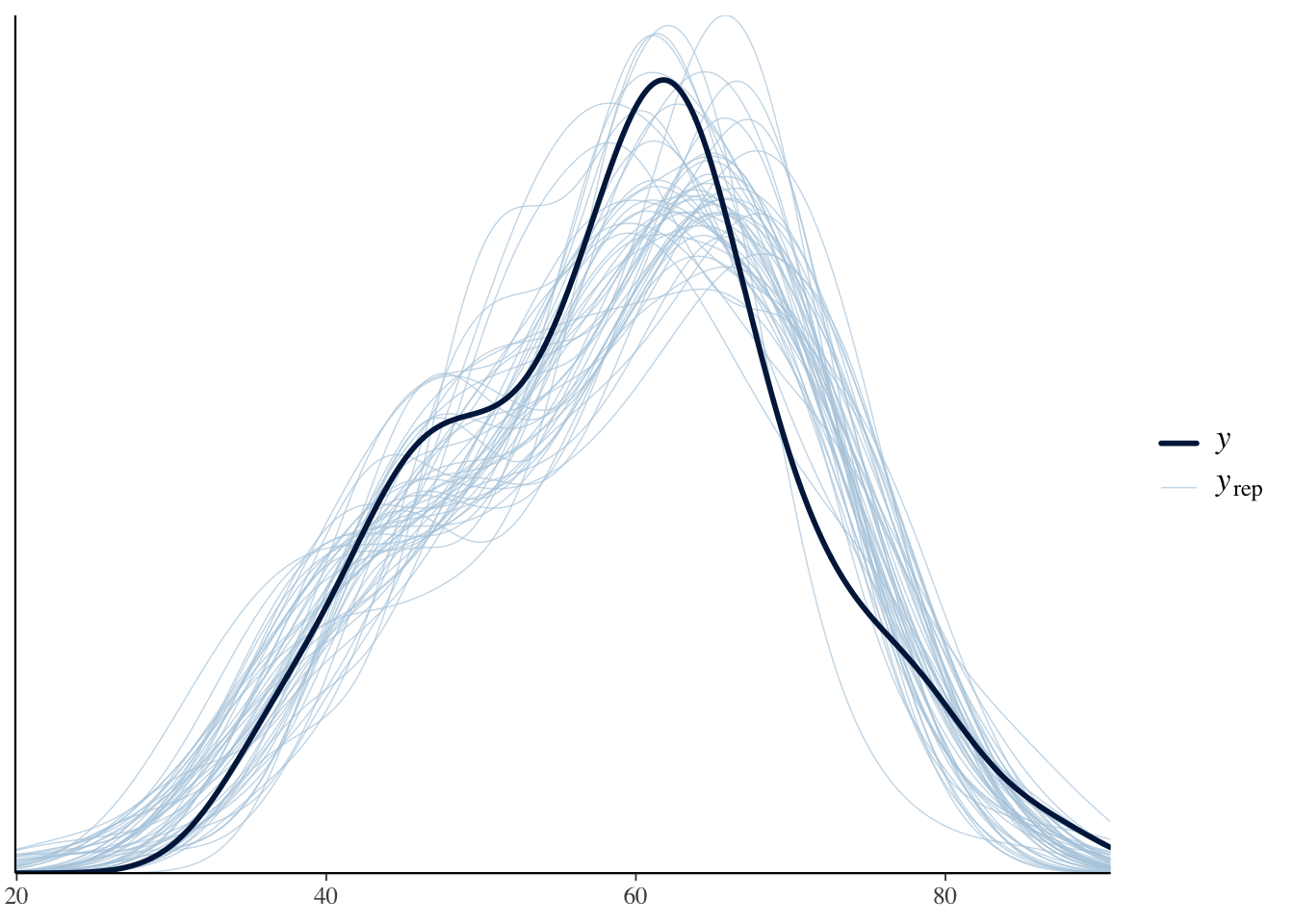
Stanモデルのgenerated quantitiesブロックで生成しておいたX_predが,まさにこの予測データである。MCMCのステップごとに一組のデータが生成されているので,その何本かを実データに重ねて描いてみる。bayesplotパッケージのppc_dens_overlay関数を使う。
<- dat$ score<- fit_a$ draws ("X_pred" , format = "matrix" )# 予測データの中から50本を選んで実データに重ねる :: ppc_dens_overlay (y = y_obs, yrep = y_rep[1 : 50 , ])
濃い線が実際に観測されたデータの分布,薄い線が事後予測分布から生成された予測データの分布である。両者がよく重なっていれば,「正規分布を仮定したこのモデルは,データの全体的な形をうまく再現できている」と判断できる。今回はデータを正規分布から生成したのだから当然うまく重なるが,実データで分布が大きく歪んでいたり外れ値があったりすると,正規モデルの予測がそれを再現できず,重なりの悪さとして検出される。そのときは,より裾の重い\(t\) 分布を使うなど,モデルを見直す手がかりになる。
データのレベルで効果を測る
事後予測分布の使い道は,モデルの妥当性チェックだけではない。むしろ心理学の実践では,こちらの使い方のほうが重要になることも多い。
ここまで見てきた優越率や差の事後分布は,いずれも母平均というパラメータのレベル の話であった。たとえば「方法Aの母平均が方法Cの母平均より大きい確率」はほぼ\(1\) で,集団としての平均には明確な差があるといえる。しかし,現場で本当に知りたいのは「では,方法Aで学んだ一人と方法Cで学んだ一人を連れてきたら,どれくらいの割合でAの人のほうが高得点なのか」といった,個々のデータのレベル の問いであることも多い。
事後予測分布は,まさに予測される個々のデータの分布である。だから,パラメータではなくデータのレベルで効果を測ることができる。母平均の差だけでなく,個人ごとのばらつき\(\sigma\) も込みで「効果がどれほど体感されるか」を表現できるのである。
そのために,各事後サンプルから「無作為な一人」の予測得点を生成し,三つの量を計算してみよう。
set.seed (1 )# 各事後サンプルから,各群の「無作為な一人」の予測得点を生成する <- rnorm (nrow (draws_a), draws_a$ ` mu[1] ` , draws_a$ sigma) # 方法A <- rnorm (nrow (draws_a), draws_a$ ` mu[2] ` , draws_a$ sigma) # 方法B <- rnorm (nrow (draws_a), draws_a$ ` mu[3] ` , draws_a$ sigma) # 方法C # (1) データレベルの優越率:方法Aの一人が方法Cの一人を上回る確率 mean (xA > xC)# 比較:母平均レベルの優越率(先に見たもの) mean (draws_a$ ` mu[1] ` > draws_a$ ` mu[3] ` )# (2) 被覆率(重複度):2群の予測分布がどれだけ重なっているか :: overlap (xA, xC) # 方法A vs 方法C :: overlap (xA, xB) # 方法A vs 方法B # (3) 閾上率:70点以上を取る確率 mean (xA >= 70 )
結果を順に読み取ろう。
優越率 を見ると,母平均のレベルではほぼ\(1\) (確実にAのほうが上)であったのに対し,データのレベルでは\(0.95\) 前後にとどまっている。これは,平均としてはAが明確に上でも,個人差があるために「たまたまCの人がAの人を上回る」ことが\(5\%\) ほど起こりうる,ということを意味する。集団の傾向と,目の前の一人ひとりに起こることは別だという当たり前の事実が,数値として表現されている。このデータレベルの優越率は,共通言語効果量(common language effect size)とも呼ばれ,効果の大きさを直感的に伝えるのに向いている。
被覆率(重複度) は,二つの群の予測分布がどれだけ重なっているかを表す。方法Aと方法Cはおよそ\(2\) 割しか重なっておらず(\(8\) 割は分離している),効果が大きいことがわかる。一方,方法Aと方法Bは\(9\) 割以上が重なっており,両者は実質的にほとんど同じ分布だといえる。重なりが小さいほど効果が大きい,という関係であり,ROPEやベイズファクターで得た「A・Bは同等,CははっきりちがうC」という結論が,分布の重なり具合としても確認できる。
閾上率 は,ある基準値を超える確率である。たとえば合格ラインを\(70\) 点とすると,方法Aでは\(2\) 割以上が合格圏に入るのに対し,方法Cではほとんど誰も届かない。「平均が何点違うか」よりも「合格者が何割出るか」のほうが実務的な意思決定に直結する場面では,このように基準値を決めて閾上率を比べるのがわかりやすい。
このように,事後予測分布を使うと,平均値の差という一点だけでなく,個人のレベルでの優越率,分布の重なり,基準値の超過率といった,さまざまな角度から効果を検証できる。差があるかないかの二値判断にとどまらず,「その差が現場でどういう意味を持つのか」まで踏み込めるのが,データ生成メカニズムから出発するベイズ的アプローチの強みである。
まとめ
この章では,\(t\) 検定と分散分析という最も基本的な平均値差の分析を,ベイズの観点から組み直した。要点を整理しておこう。
分散分析の組成(データ=全体平均+効果+誤差)は,そのままデータ生成モデルになる。これをStanで記述すれば,効果\(\delta_j\) の分布を直接推定できる。
ベイズでは差を確率分布として持つので,区間推定,優越率,全ペアの比較などを多重比較の調整なしで自由に行える。
判断の道具として,ROPE(実質的同等の領域による判断),ベイズファクター(モデル比較),事後予測分布(モデルの妥当性チェックに加え,データレベルの優越率・重複度・閾上率による効果の検証)がある。
「差があるとはいえない」と「差がない(同等である)」は別物であり,後者を積極的に主張できるのがベイズの強みである。
頻度主義の検定が悪いというわけではない。長い歴史の中で洗練された明快な手続きであり,多くの知見がその上に積み重ねられてきた。しかし,平均値差を「差の分布」として直接捉え,意思決定の幅を広げられるベイズのアプローチは,研究者により豊かな表現力を与えてくれる。どちらか一方ではなく,両方の視点を持っておくことが望ましい。
課題
以下のデータセットは,三つの群(group)について測定値(y)を記録したものです。データセットはex_anova_bayes.csv からダウンロードできます。このデータに対して,本章で扱った方法を用いて以下を順に報告してください。
本章のbayes_anova.stanを用いて,整然データの形で三群の平均値差をベイズ推定し,各群の母平均muと効果deltaの事後分布の代表値・\(95\%\) 区間を示す。
MCMCサンプルから,三つの全ペアの差の事後分布を求め,それぞれの\(95\%\) 区間と優越率を報告する。
各ペアの差について,ROPEを\(\pm 0.5\) としてbayestestR::ropeを計算し,「実質的に差がない」といえるペアがあるかどうかを論じる。
brmsで同じモデルを推定し(効果コーディングを使うこと),Stanの結果と係数が一致することを確認する。さらにベイズファクターを計算し,効果がゼロでないといえるかを論じる。事後予測分布をppc_dens_overlayで描き,正規分布を仮定したモデルがデータをうまく再現できているかを評価する。
事後予測分布を使って,群の組ごとに(a)データレベルの優越率,(b)bayestestR::overlapによる予測分布の重複度(被覆率)を求める。さらに適当な基準値を一つ決めて,各群の閾上率を比較する。これらが母平均レベルの結果とどう違うかを論じる。
レポートには,使用したRコードと,各項目の結果に対する簡潔な解釈を含めてください。
JASP Team. 2025.
JASP (Version 0.95.1)[Computer software] .
https://jasp-stats.org/ .
Kruschke, John K. 2018. “Rejecting or Accepting Parameter Values in Bayesian Estimation.” Advances in Methods and Practices in Psychological Science 1 (2): 270–80.