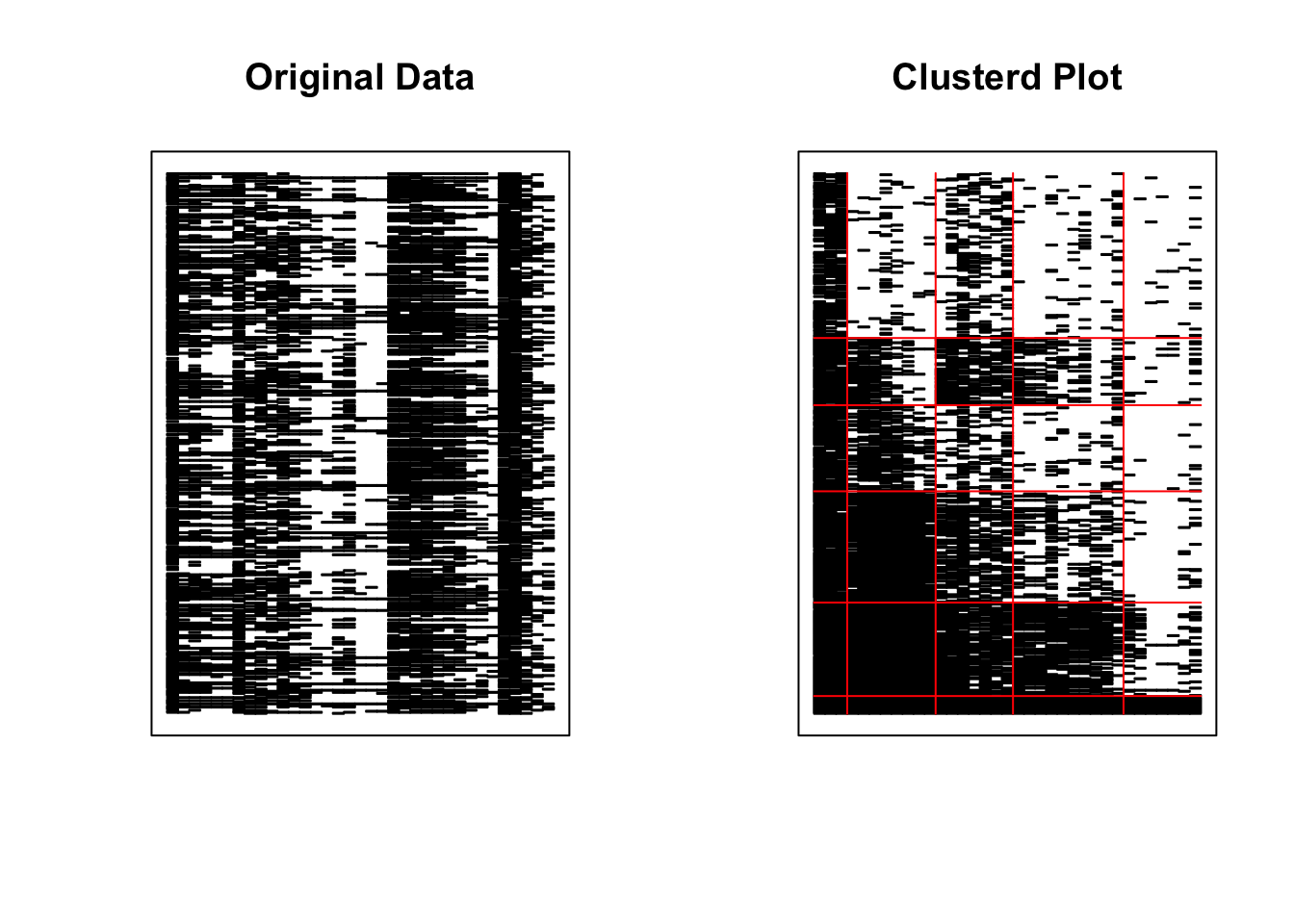
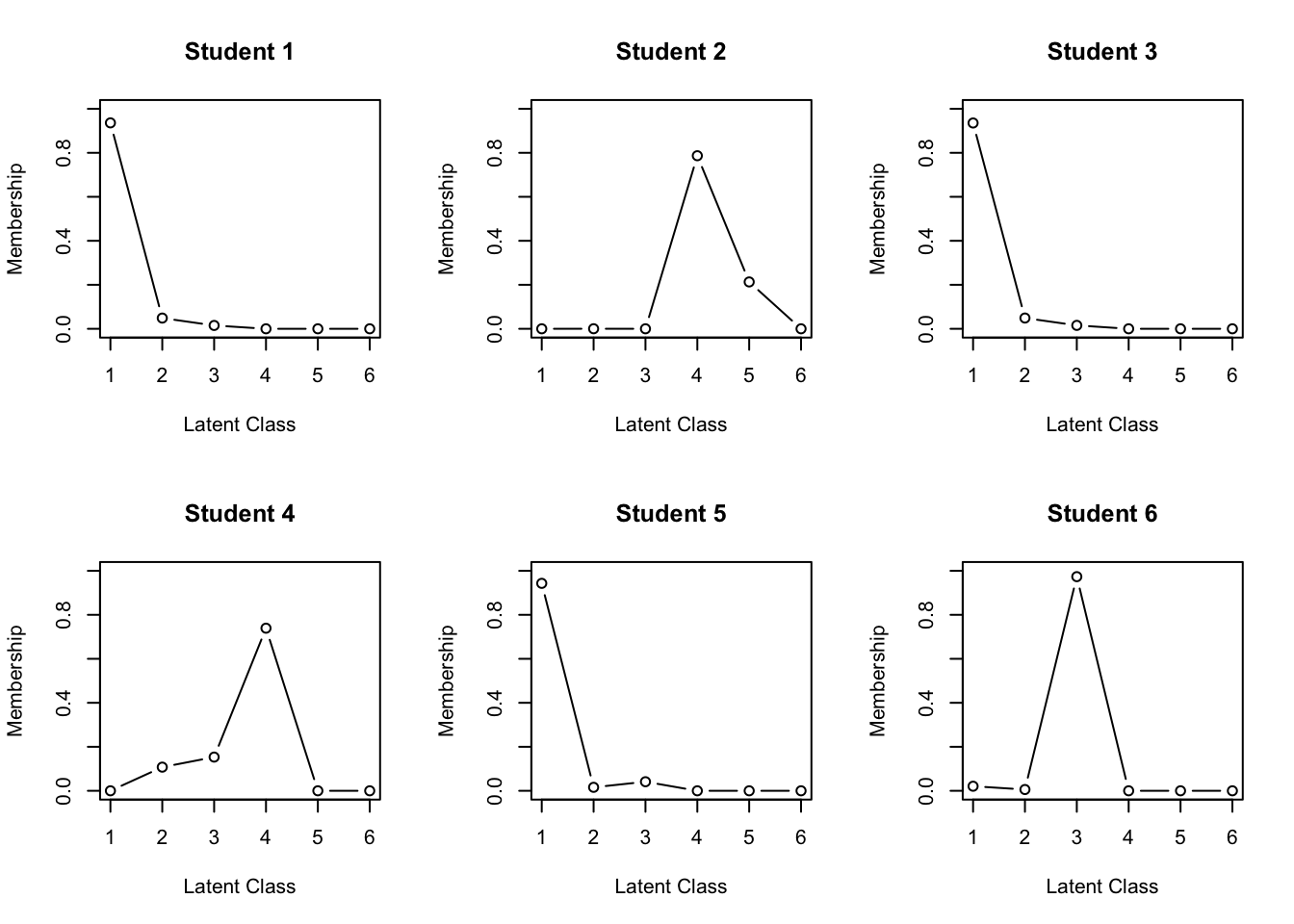
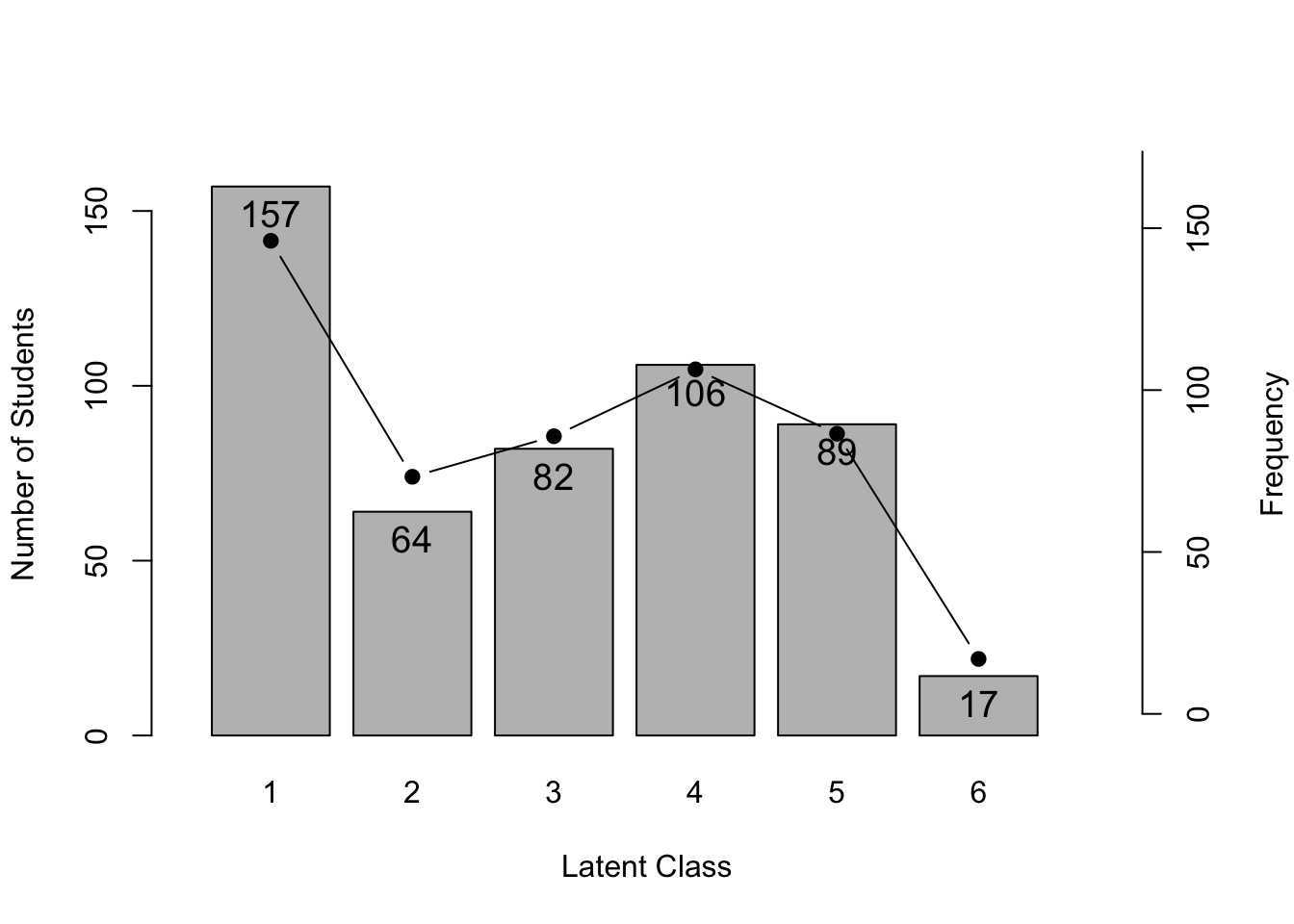
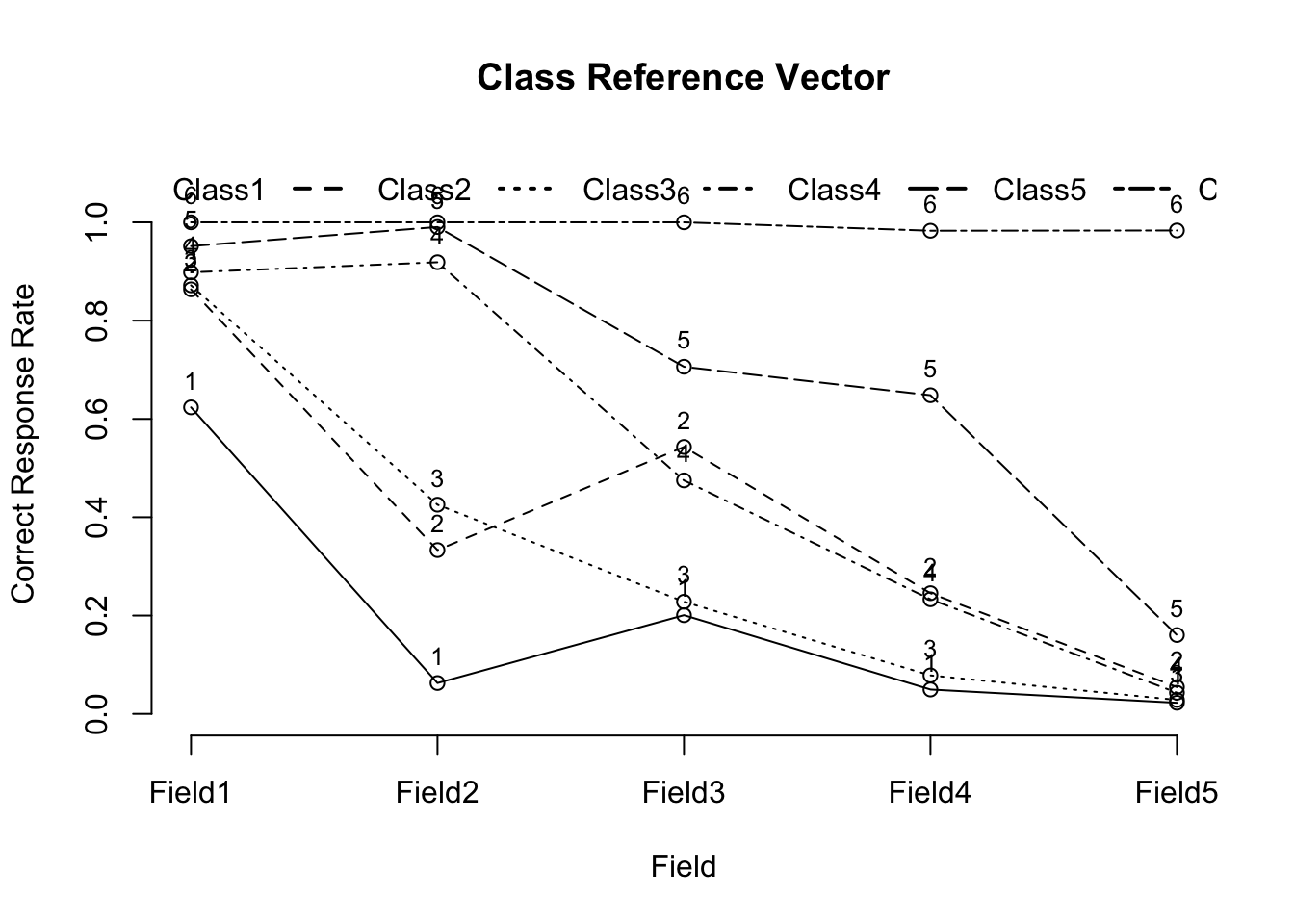
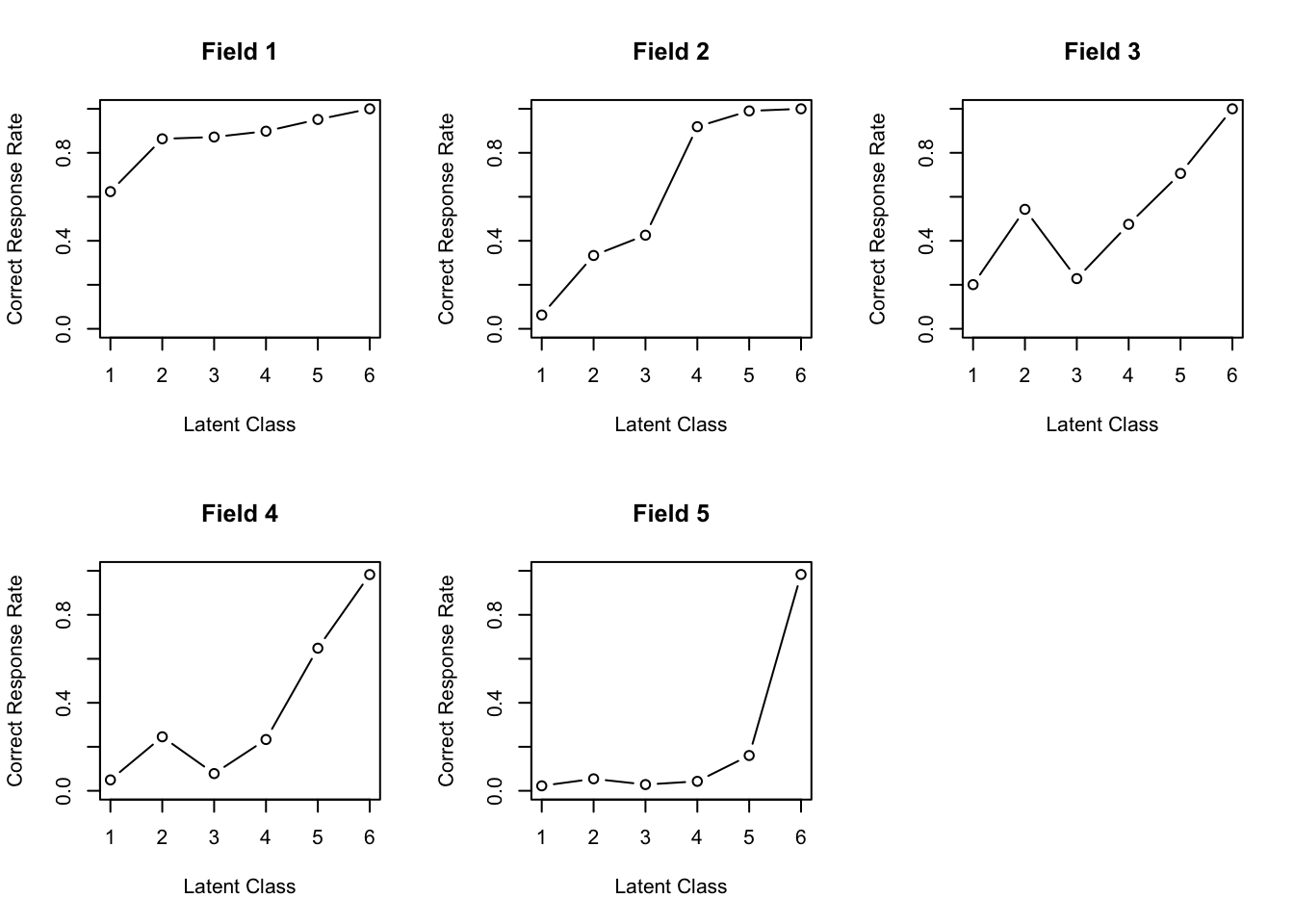
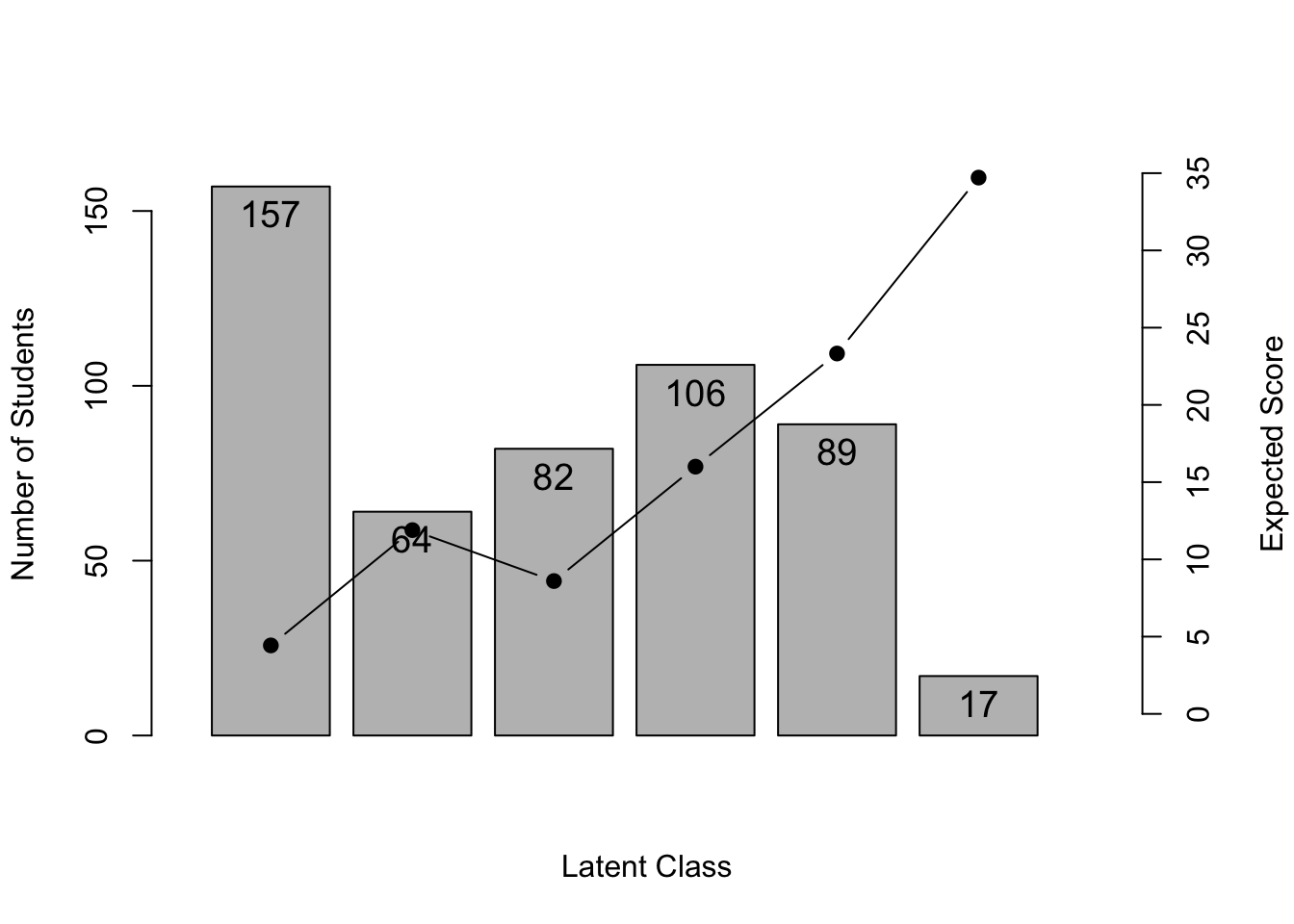
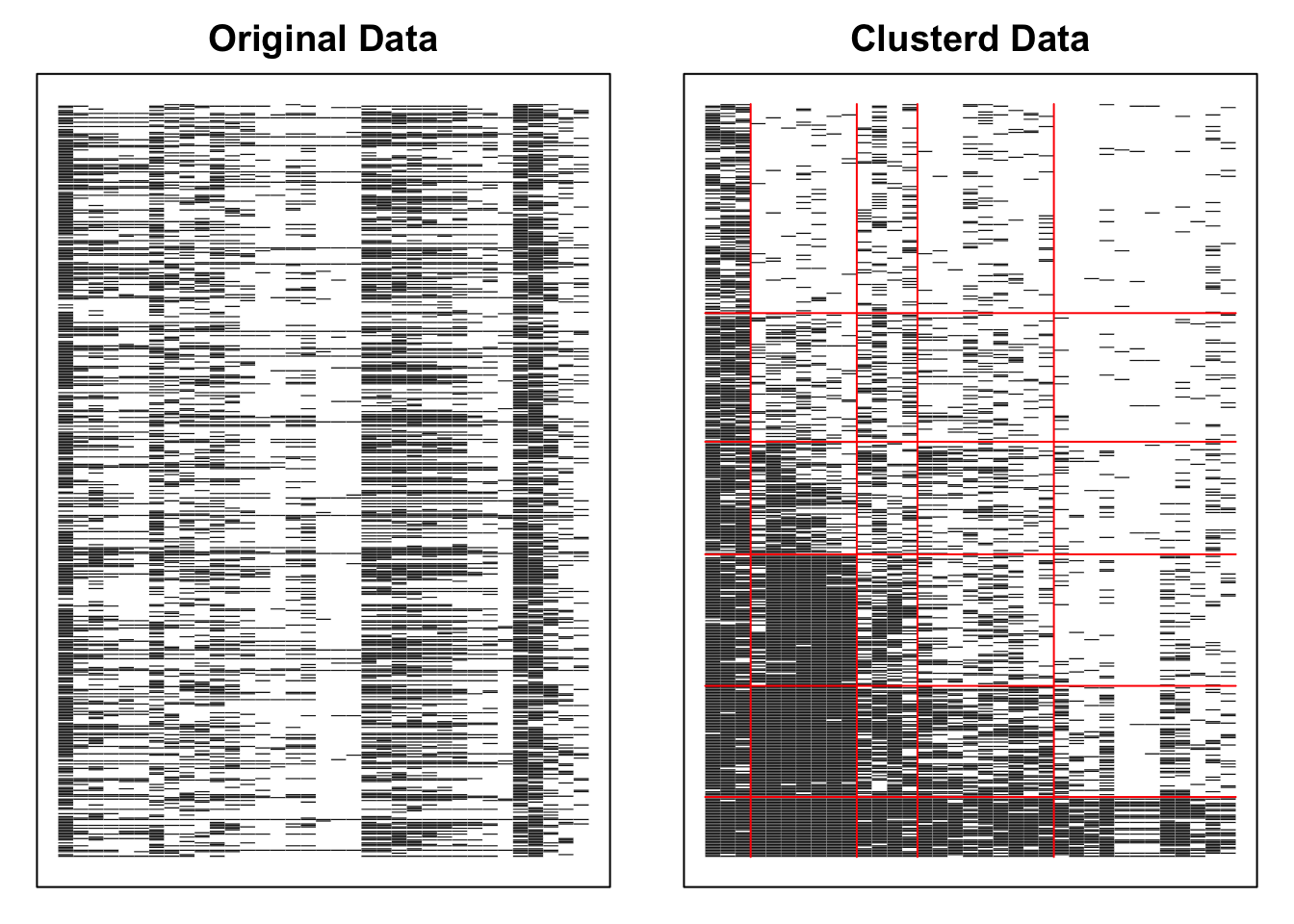
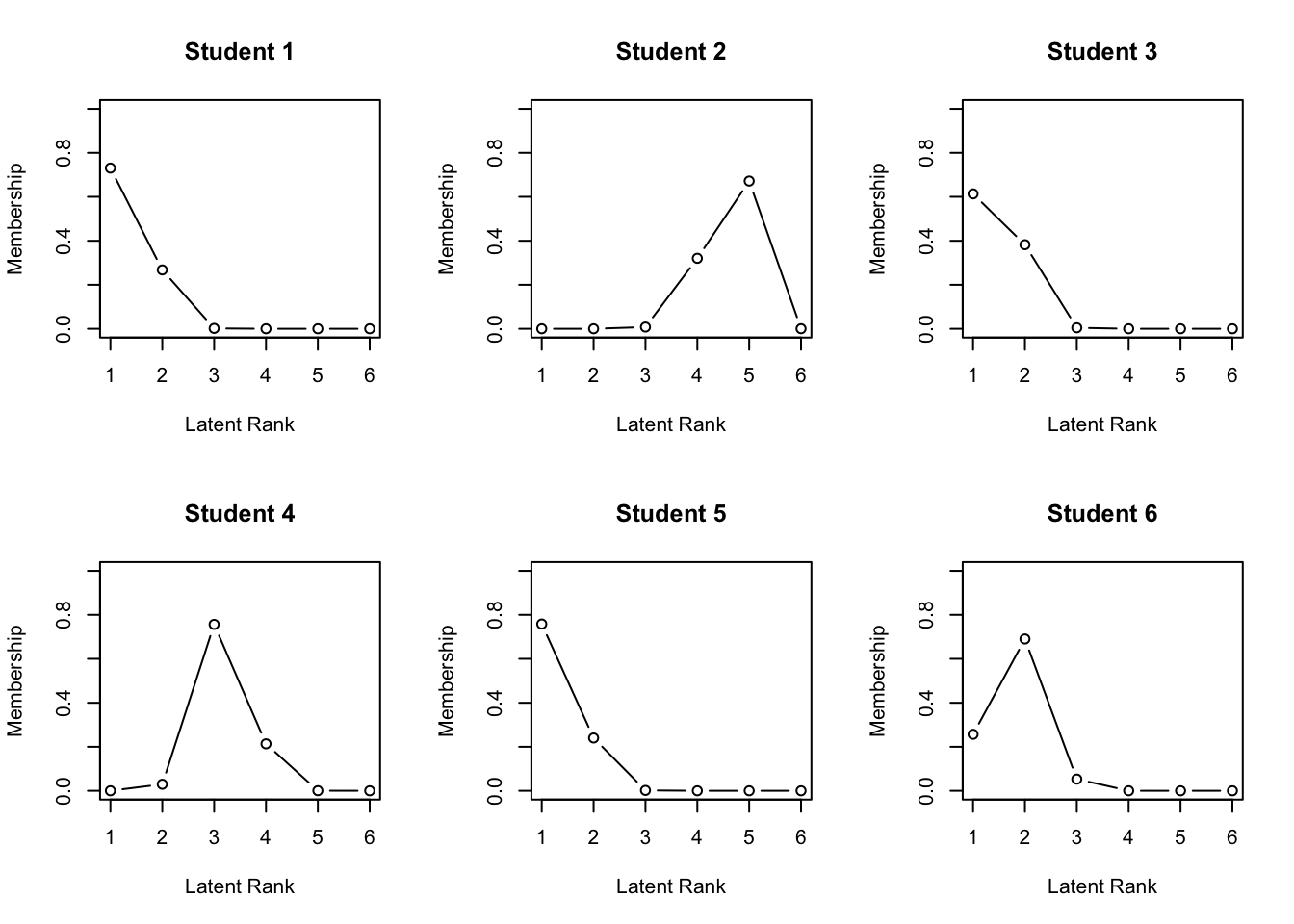
library(exametrika)
dat <- J35S515
dat$U |> head() Item01 Item02 Item03 Item04 Item05 Item06 Item07 Item08 Item09 Item10
[1,] 0 0 0 0 0 0 0 1 1 0
[2,] 1 1 0 0 0 0 1 0 1 1
[3,] 1 0 0 0 0 0 1 1 0 1
[4,] 0 0 1 0 0 0 0 1 1 0
[5,] 1 0 0 0 0 0 1 0 0 0
[6,] 1 0 0 0 0 0 0 0 0 0
Item11 Item12 Item13 Item14 Item15 Item16 Item17 Item18 Item19 Item20
[1,] 0 0 0 0 0 1 0 0 0 0
[2,] 1 1 1 1 0 0 1 0 0 0
[3,] 0 0 0 0 0 0 0 0 1 1
[4,] 0 0 0 0 0 0 0 0 0 0
[5,] 0 0 0 0 0 0 0 0 0 0
[6,] 0 0 0 0 0 0 0 0 0 0
Item21 Item22 Item23 Item24 Item25 Item26 Item27 Item28 Item29 Item30
[1,] 0 0 0 0 0 0 0 0 0 0
[2,] 1 1 1 1 1 1 1 0 0 0
[3,] 0 0 0 0 0 0 0 0 0 0
[4,] 1 0 1 1 1 1 1 1 0 0
[5,] 0 0 0 0 0 0 0 0 0 0
[6,] 1 1 0 0 0 0 1 0 0 0
Item31 Item32 Item33 Item34 Item35
[1,] 1 1 1 0 0
[2,] 1 1 0 0 0
[3,] 1 0 0 0 0
[4,] 1 1 0 1 0
[5,] 1 1 1 0 1
[6,] 1 1 0 0 1