This function takes exametrika Biclustering output as input and generates a Class Reference Vector (CRV) plot using ggplot2. CRV shows how each latent class performs across fields, with one line per class.
Supports both binary (2-valued) and polytomous (multi-valued) biclustering models.
For polytomous data, the stat parameter controls how expected scores
are calculated from category probabilities.
Usage
plotCRV_gg(
data,
title = TRUE,
colors = NULL,
linetype = "solid",
show_legend = TRUE,
legend_position = "right",
stat = "mean",
show_labels = FALSE
)Arguments
- data
An object of class
c("exametrika", "Biclustering")fromexametrika::Biclustering().- title
Logical or character. If
TRUE(default), display an auto-generated title. IfFALSE, no title. If a character string, use it as a custom title.- colors
Character vector of colors for each class. If
NULL(default), a colorblind-friendly palette is used.- linetype
Character or numeric scalar specifying the line type applied to all lines. Default is
"solid".- show_legend
Logical. If
TRUE(default), display the legend.- legend_position
Character. Position of the legend. One of
"right"(default),"top","bottom","left","none".- stat
Character. Statistic for polytomous data:
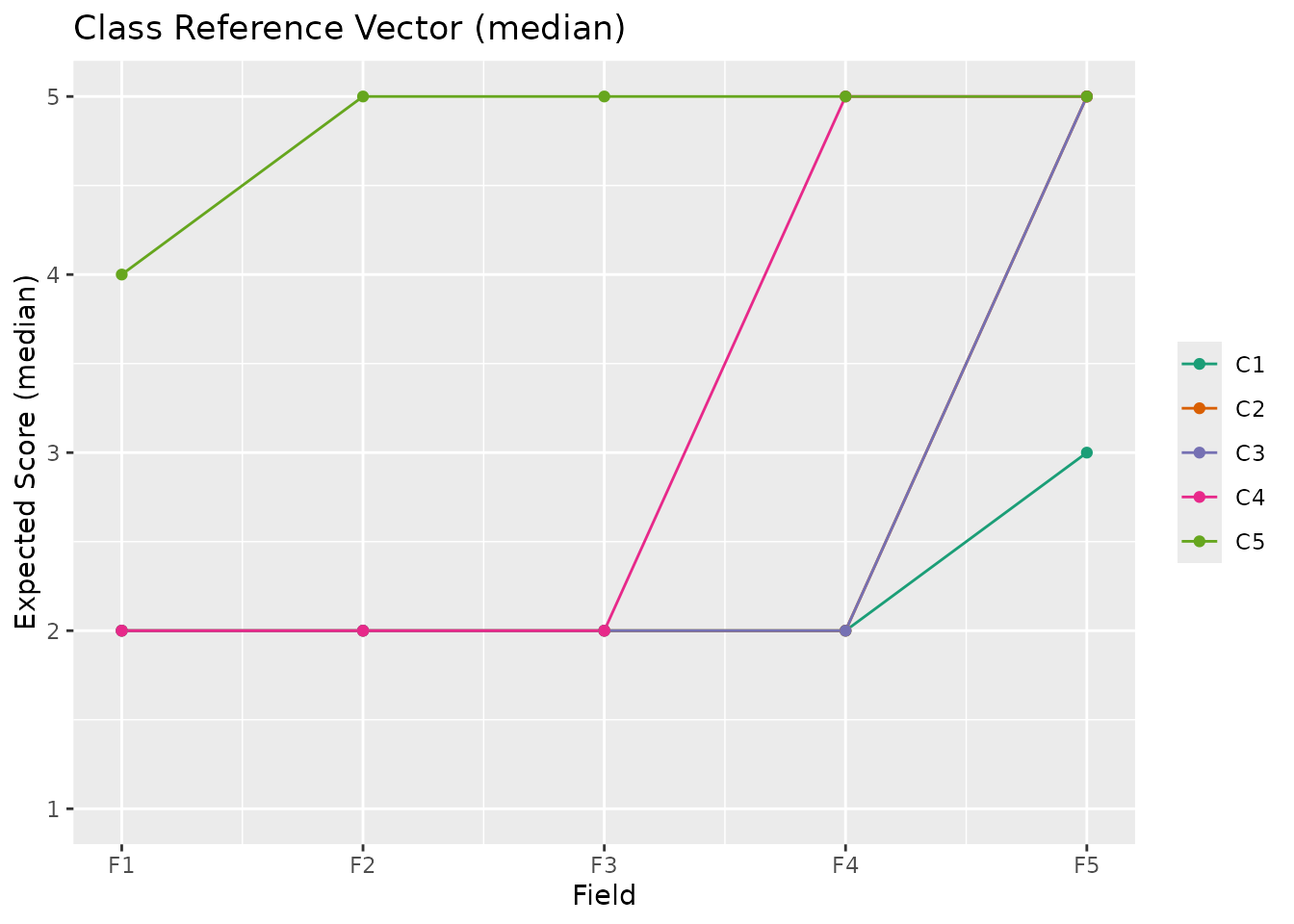
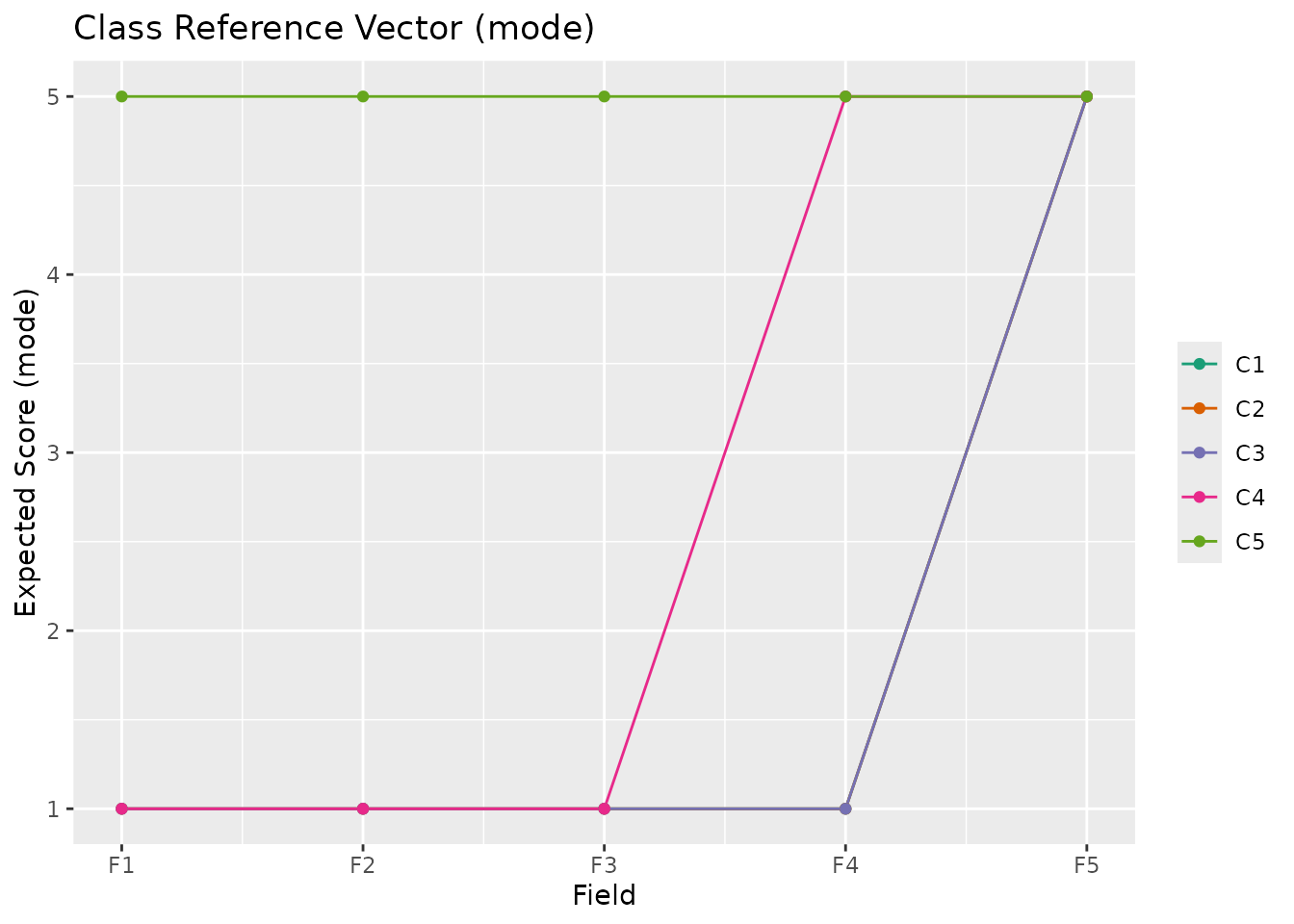
"mean"(default),"median", or"mode". For binary data, this parameter is ignored."mean": Expected score (sum of category x probability)"median": Median category (cumulative probability >= 0.5)"mode": Most probable category
- show_labels
Logical. If
TRUE, displays class labels on each point usingggrepelto avoid overlaps. Defaults toFALSEsince the legend already provides class information.
Details
The Class Reference Vector is the transpose of the Field Reference Profile (FRP). While FRP shows one plot per field, CRV displays all classes in a single plot with fields on the x-axis. Each line represents a latent class, showing its correct response rate pattern across fields.
Binary Data (2 categories):
Y-axis shows "Correct Response Rate" (0.0 to 1.0)
Values represent the probability of correct response
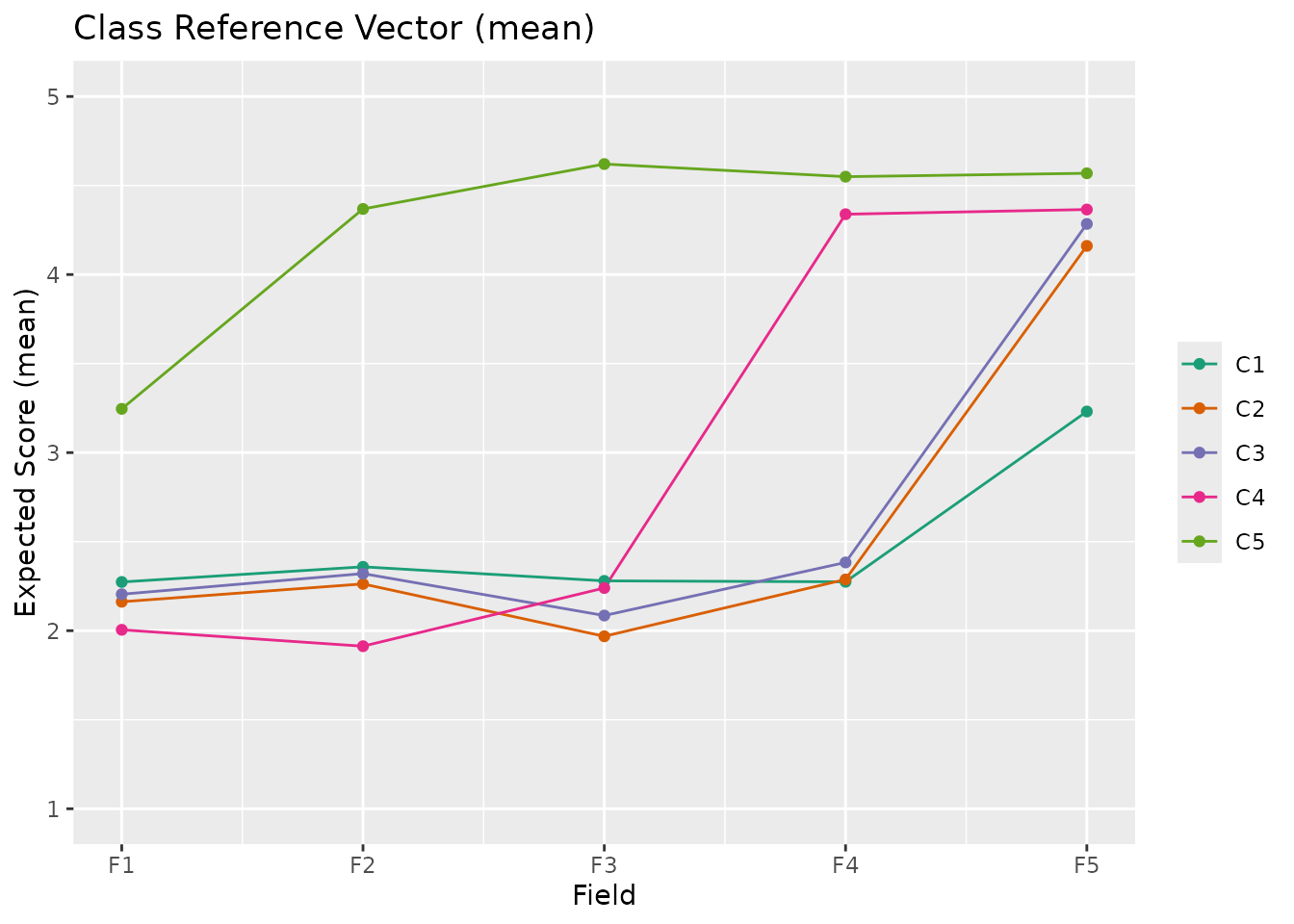
Polytomous Data (3+ categories):
Y-axis shows "Expected Score" (1 to max category)
Values are calculated using the
statparameterHigher scores indicate better performance
CRV is used when latent classes are nominal (unordered). For ordered
latent ranks, use plotRRV_gg instead.
Examples
# Binary biclustering
library(exametrika)
result <- Biclustering(J35S515, nfld = 5, ncls = 6)
plotCRV_gg(result)
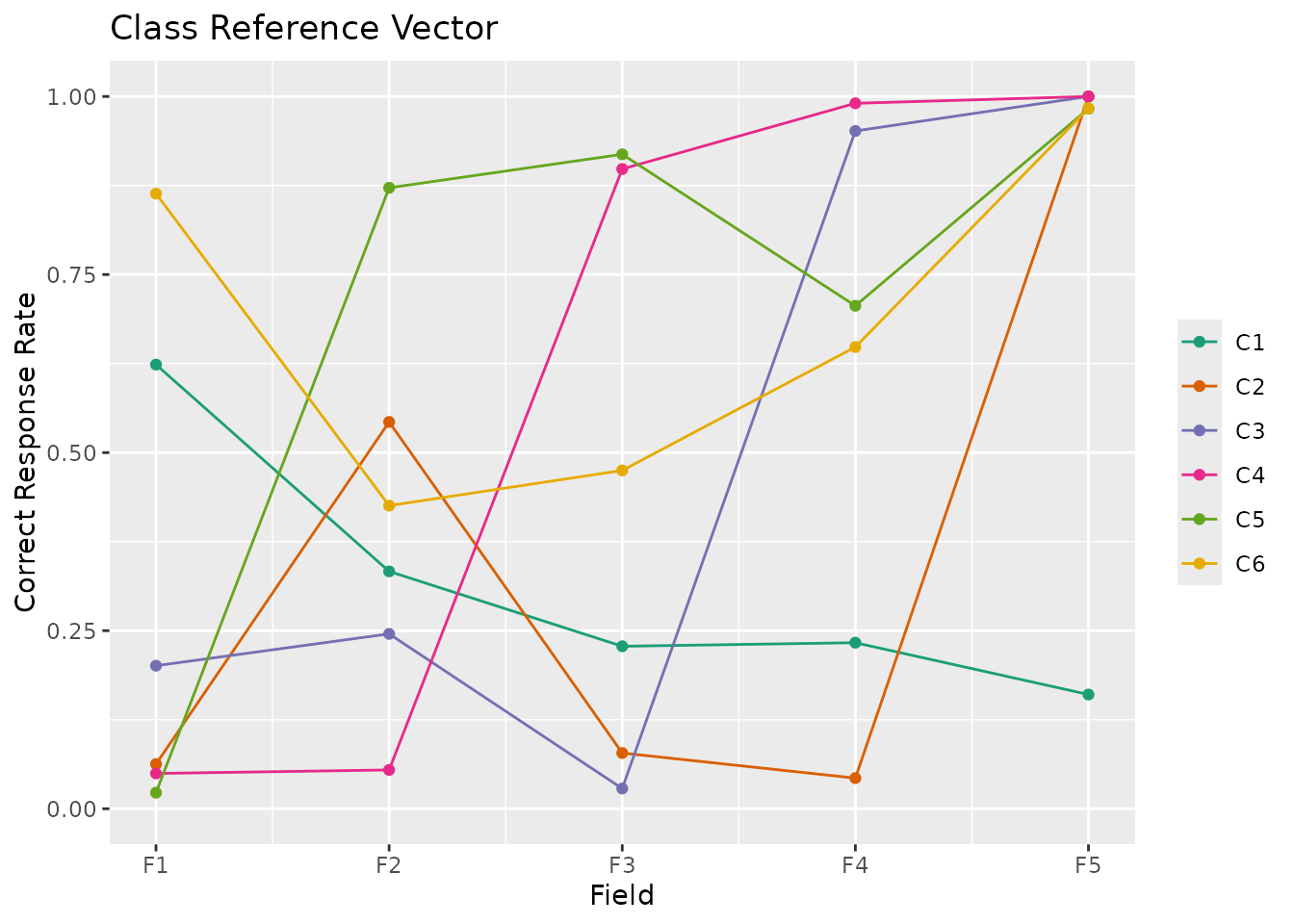 # \donttest{
# Ordinal biclustering (polytomous)
data(J35S500)
result_ord <- Biclustering(J35S500, ncls = 5, nfld = 5, method = "R")
plotCRV_gg(result_ord) # Default: mean
# \donttest{
# Ordinal biclustering (polytomous)
data(J35S500)
result_ord <- Biclustering(J35S500, ncls = 5, nfld = 5, method = "R")
plotCRV_gg(result_ord) # Default: mean
 plotCRV_gg(result_ord, stat = "median")
plotCRV_gg(result_ord, stat = "median")
 plotCRV_gg(result_ord, stat = "mode")
plotCRV_gg(result_ord, stat = "mode")
 # }
# }