ユニット概要
分類
幹(全員必須)
前提
U11(記述統計)
次のユニット
U13(回帰モデル)
使用データ
BaseballDecade.csv, iris
学習目標
標本分布と標準誤差を理解する / 信頼区間の意味と構成を理解する / 仮説検定の論理を理解する / 検出力と効果量の関係を理解する
事前知識
記述統計から推測統計へ
U11では、手元のデータを要約する「記述統計」を学びました。しかし、研究で本当に知りたいのは 手元のデータそのものの性質ではなく、その背後にある母集団の性質 です。
例えば、ある大学の学生100人を調査して平均身長が170cmだったとき、知りたいのは「この100人の平均が170cm」という事実ではなく、「日本の大学生全体の平均身長はどのくらいか」ということです。
手元のデータ(標本)から母集団の性質を推し量る方法が 推測統計(statistical inference) です。
母集団と標本
母集団(population) : 知りたい対象全体。通常は直接調べられない標本(sample) : 母集団から取り出した一部のデータ母数(parameter) : 母集団の特性値(母平均 \(\mu\) 、母分散 \(\sigma^2\) など)統計量(statistic) : 標本から計算される値(標本平均 \(\bar{X}\) 、標本分散 \(s^2\) など)
統計量は母数の 推定値(estimate) として使われます。
標本分布と標準誤差
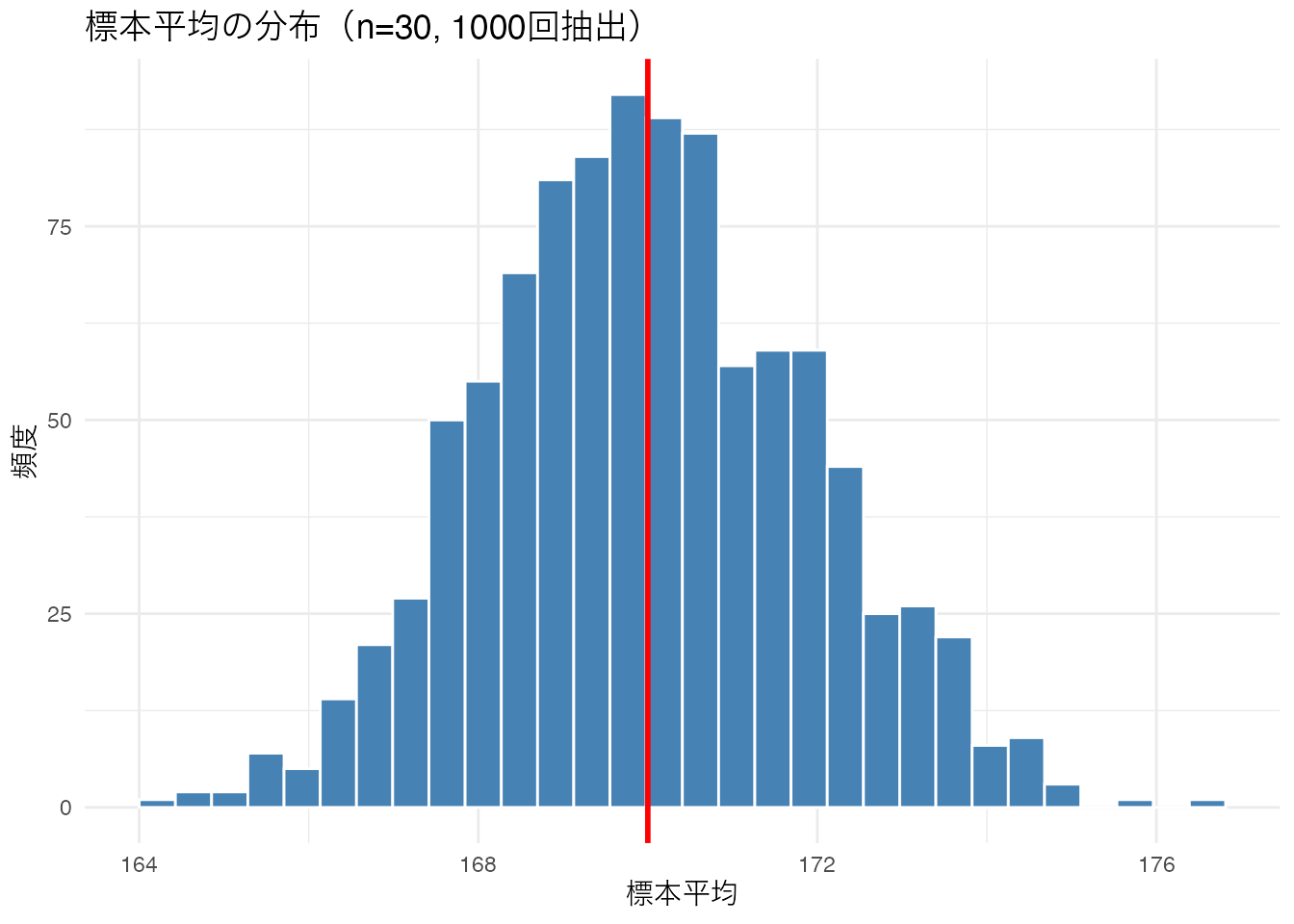
同じ母集団から何度も標本を取ると、そのたびに標本平均は異なる値になります。この 標本平均のばらつき を表す分布が 標本分布(sampling distribution) です。
# 母集団: 平均170, 標準偏差10の正規分布から # n=30の標本を1000回抽出して、それぞれの標本平均を計算 set.seed (42 )<- replicate (1000 , mean (rnorm (30 , mean = 170 , sd = 10 )))# 標本平均の分布を可視化 tibble (sample_mean = sample_means) %>% ggplot (aes (x = sample_mean)) + geom_histogram (bins = 30 , fill = "steelblue" , color = "white" ) + geom_vline (xintercept = 170 , color = "red" , linewidth = 1 ) + labs (title = "標本平均の分布(n=30, 1000回抽出)" ,x = "標本平均" , y = "頻度" ) + theme_minimal ()
標本平均のばらつきの大きさを 標準誤差(standard error; SE) と呼びます。
\[
SE = \frac{s}{\sqrt{n}}
\]
\(s\) : 標本の標準偏差\(n\) : 標本サイズ
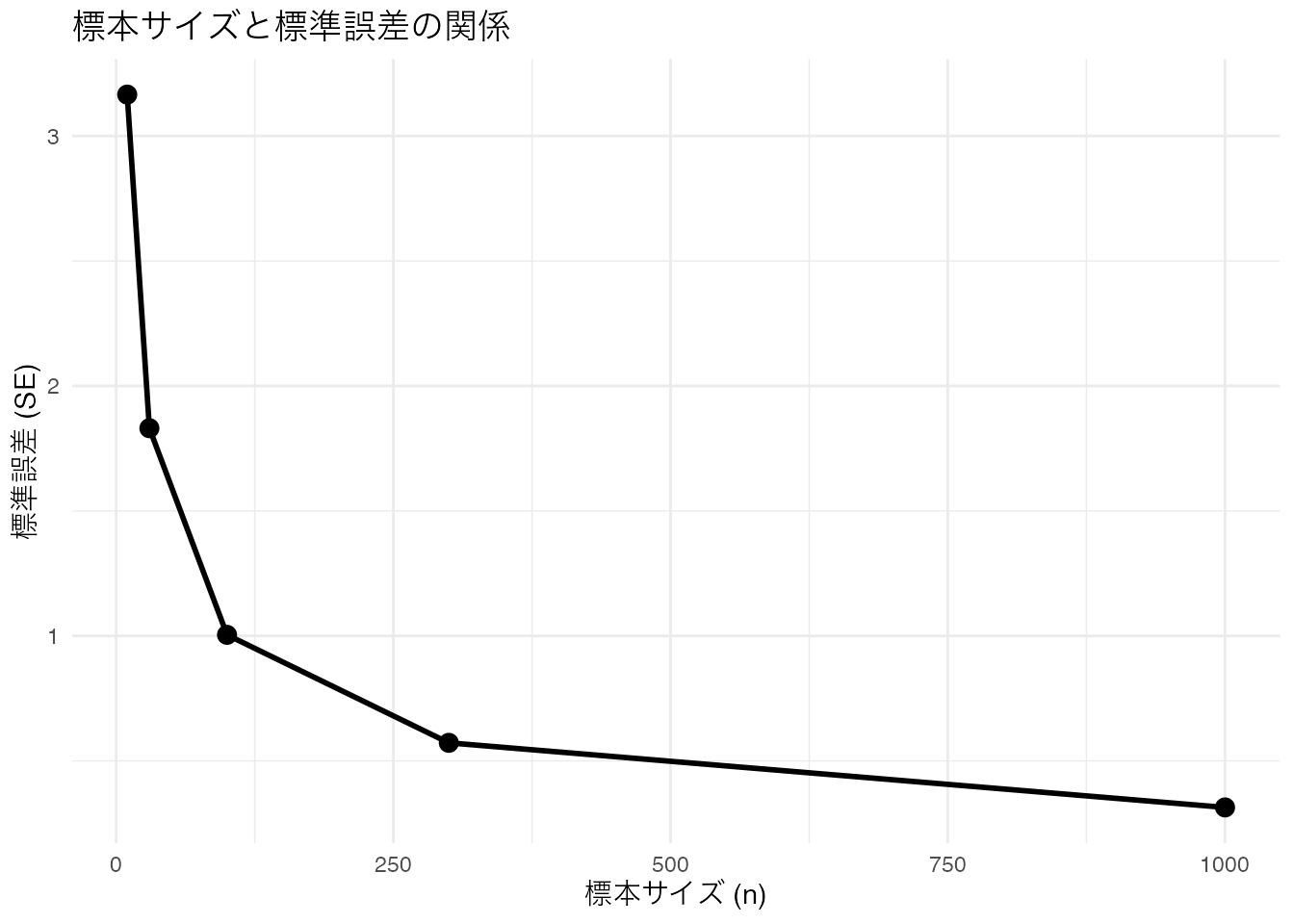
標準誤差は標本サイズ \(n\) が大きいほど小さくなります。つまり、データが多いほど推定は安定します。
# 標本サイズと標準誤差の関係 set.seed (42 )<- tibble (n = c (10 , 30 , 100 , 300 , 1000 )%>% rowwise () %>% mutate (se = sd (replicate (5000 , mean (rnorm (n, mean = 170 , sd = 10 ))))%>% ggplot (aes (x = n, y = se)) + geom_line (linewidth = 1 ) + geom_point (size = 3 ) + labs (title = "標本サイズと標準誤差の関係" ,x = "標本サイズ (n)" , y = "標準誤差 (SE)" ) + theme_minimal ()
信頼区間
信頼区間(confidence interval; CI) は、母数がどのあたりにありそうかを区間で示したものです。
95%信頼区間の計算式(母分散が未知の場合):
\[
\bar{X} \pm t_{0.975,\, n-1} \times \frac{s}{\sqrt{n}}
\]
\(t_{0.975,\, n-1}\) : 自由度 \(n-1\) の \(t\) 分布の上側2.5%点
# 信頼区間の計算例 <- c (168 , 172 , 175 , 163 , 170 , 178 , 165 , 171 , 169 , 174 )<- length (x)<- mean (x)<- sd (x)<- s / sqrt (n)<- qt (0.975 , df = n - 1 ) # t分布の臨界値 <- x_bar - t_crit * se<- x_bar + t_crit * secat (sprintf ("標本平均: %.2f \n " , x_bar))cat (sprintf ("標準誤差: %.2f \n " , se))cat (sprintf ("95%%信頼区間: [%.2f, %.2f] \n " , ci_lower, ci_upper))
95%信頼区間: [167.24, 173.76]
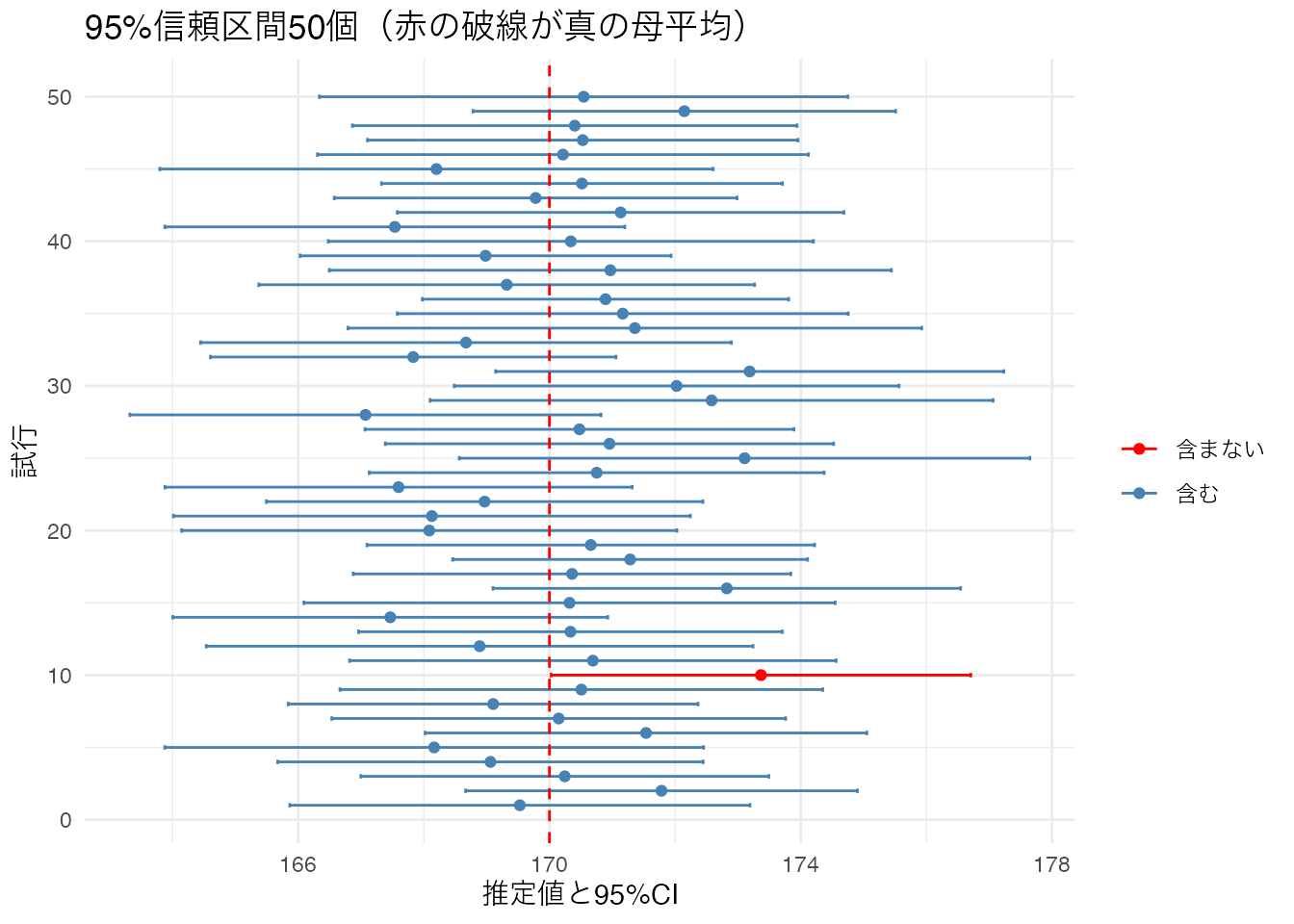
95%信頼区間の正しい解釈 : 同じ方法で100回信頼区間を作ると、そのうち約95回は真の母数を含む。「母数が95%の確率でこの区間にある」という意味では ない ことに注意してください。
# 100個の信頼区間のうち、何個が真の母平均(170)を含むか set.seed (123 )<- 170 <- tibble (trial = 1 : 100 ) %>% rowwise () %>% mutate (sample = list (rnorm (30 , mean = mu, sd = 10 )),x_bar = mean (sample),se = sd (sample) / sqrt (30 ),ci_lower = x_bar - qt (0.975 , 29 ) * se,ci_upper = x_bar + qt (0.975 , 29 ) * se,contains_mu = ci_lower <= mu & mu <= ci_upper%>% ungroup ()# 母平均を含む割合 cat (sprintf ("真の母平均を含む信頼区間: %d/100 \n " , sum (ci_data$ contains_mu)))# 可視化(最初の50個) %>% slice (1 : 50 ) %>% ggplot (aes (x = trial, y = x_bar, color = contains_mu)) + geom_point (size = 1.5 ) + geom_errorbar (aes (ymin = ci_lower, ymax = ci_upper), width = 0.3 ) + geom_hline (yintercept = mu, color = "red" , linetype = "dashed" ) + scale_color_manual (values = c ("TRUE" = "steelblue" , "FALSE" = "red" ),labels = c ("TRUE" = "含む" , "FALSE" = "含まない" )) + labs (title = "95%信頼区間50個(赤の破線が真の母平均)" ,x = "試行" , y = "推定値と95%CI" , color = "" ) + coord_flip () + theme_minimal ()
仮説検定の論理
仮説検定は 背理法に似た論理 で進みます。
帰無仮説(\(H_0\) ) : 否定したい仮説(例: 「差がない」「効果がない」)対立仮説(\(H_1\) ) : 主張したい仮説(例: 「差がある」「効果がある」)\(H_0\) が正しいと仮定して、手元のデータが得られる確率(p値 )を計算するp値が十分小さければ(通常 \(p < .05\) )、\(H_0\) を棄却して \(H_1\) を採択する
# 1標本t検定の例: この標本の母平均は170と異なるか? <- c (175 , 172 , 178 , 180 , 173 , 176 , 174 , 179 , 177 , 171 )<- t.test (x, mu = 170 )
One Sample t-test
data: x
t = 5.7446, df = 9, p-value = 0.0002782
alternative hypothesis: true mean is not equal to 170
95 percent confidence interval:
173.3341 177.6659
sample estimates:
mean of x
175.5
出力の読み方:
t = ...: t統計量の値df = ...: 自由度p-value = ...: p値(\(H_0\) のもとでこのデータ以上に極端な結果が得られる確率)95 percent confidence interval: 95%信頼区間mean of x: 標本平均
2つのエラーと検出力
仮説検定では2種類の誤りが起こりえます。
\(H_0\) を棄却しない正しい判断
第2種の誤り(\(\beta\) )
\(H_0\) を棄却する第1種の誤り(\(\alpha\) ) 正しい判断
第1種の誤り(\(\alpha\) ) : 本当は差がないのに「差がある」と結論する。通常 \(\alpha = .05\) に設定第2種の誤り(\(\beta\) ) : 本当は差があるのに「差がない」と結論する検出力(power) : \(1 - \beta\) 。本当に差があるとき、正しく検出できる確率
検出力は以下の要因で変化します:
効果量が大きい ほど検出力は高い標本サイズが大きい ほど検出力は高い有意水準を緩める(\(\alpha\) を大きくする) ほど検出力は高い(ただしトレードオフ)
# 検出力の計算例: 効果量d=0.5を検出するのに必要なnは? power.t.test (delta = 0.5 , sd = 1 , sig.level = 0.05 , power = 0.80 ,type = "two.sample" , alternative = "two.sided" )
Two-sample t test power calculation
n = 63.76576
delta = 0.5
sd = 1
sig.level = 0.05
power = 0.8
alternative = two.sided
NOTE: n is number in *each* group
この結果は、Cohen’s \(d = 0.5\) (中程度の効果)を80%の検出力で検出するには、各群約64人(合計128人)が必要であることを示しています。
t検定の種類
1標本t検定
1つの標本の平均が特定の値と異なるか
t.test(x, mu = 値)
対応のないt検定
2群の平均が異なるか(独立な2群)
t.test(x1, x2)
対応のあるt検定
対応のある2条件の平均が異なるか
t.test(x1, x2, paired = TRUE)
Welchのt検定
2群の分散が等しくない場合(Rのデフォルト)
t.test(x1, x2)
Rの t.test() はデフォルトで Welchのt検定 (等分散を仮定しない)を行います。等分散を仮定する場合は var.equal = TRUE を指定します。
ランクC: 基礎知識
12-C-1
母集団から標本を取り出して、標本の統計量から母集団の特性を推し量ることを「推測統計」と呼ぶ。
TRUE FALSE
12-C-2
標本平均の標準偏差のことを何と呼ぶか。
標準偏差 標準誤差 信頼区間 効果量
12-C-3
標本サイズ \(n\) を大きくすると、標準誤差は大きくなる。
TRUE FALSE
12-C-4
「95%信頼区間」の正しい解釈はどれか。
母平均が95%の確率でこの区間に入る 同じ方法で繰り返し信頼区間を作ると、約95%が真の母数を含む データの95%がこの区間に含まれる この区間の幅が95%の精度を保証する
12-C-5
仮説検定において、帰無仮説(\(H_0\) )が正しいにもかかわらず棄却してしまう誤りを何と呼ぶか。
第1種の誤り 第2種の誤り 標準誤差 検出力不足
12-C-6
p値が0.03であった場合、有意水準5%で帰無仮説を棄却できる。
TRUE FALSE
12-C-7
検出力(power)とは何か。
帰無仮説が正しいとき、正しく棄却しない確率 帰無仮説が誤りであるとき、正しく棄却できる確率 p値が有意水準を下回る確率 信頼区間が母数を含む確率
12-C-8
Rの t.test() 関数はデフォルトで等分散を仮定したt検定を行う。
TRUE FALSE
12-C-9
効果量(Cohen’s \(d\) )が0.8のとき、その効果の大きさの目安はどれか。
小さい 中程度 大きい 非常に大きい
12-C-10
標本サイズを大きくすると検出力はどうなるか。
高くなる 低くなる 変わらない 効果量に依存する
ランクB: 実践スキル
12-B-1
irisデータセットの Sepal.Length について、母平均が5.5であるかどうかを1標本t検定で検定しなさい。結果のp値と95%信頼区間を確認すること。
模範解答
t.test (iris$ Sepal.Length, mu = 5.5 )
One Sample t-test
data: iris$Sepal.Length
t = 5.078, df = 149, p-value = 1.123e-06
alternative hypothesis: true mean is not equal to 5.5
95 percent confidence interval:
5.709732 5.976934
sample estimates:
mean of x
5.843333
p値が0.05未満なので、母平均が5.5であるという帰無仮説は棄却されます。95%信頼区間は5.5を含んでいないことも確認できます。
12-B-2
irisデータで、setosaとversicolorの Sepal.Length に差があるかを対応のないt検定で検定しなさい。
模範解答
<- iris %>% :: filter (Species %in% c ("setosa" , "versicolor" ))t.test (Sepal.Length ~ Species, data = iris_sub)
Welch Two Sample t-test
data: Sepal.Length by Species
t = -10.521, df = 86.538, p-value < 2.2e-16
alternative hypothesis: true difference in means between group setosa and group versicolor is not equal to 0
95 percent confidence interval:
-1.1057074 -0.7542926
sample estimates:
mean in group setosa mean in group versicolor
5.006 5.936
p値が非常に小さく、2種間の萼片長に有意な差があることがわかります。
12-B-3
BaseballDecade.csvを読み込み、セ・リーグとパ・リーグの打率に有意な差があるかをt検定で検定しなさい。打率は Hit / AtBats で計算し、リーグは team 変数から判定すること(AtBatsが0の行は除外する)。
模範解答
<- readr:: read_csv ("../data/BaseballDecade.csv" )<- c ("巨人" , "阪神" , "中日" , "DeNA" , "広島" , "ヤクルト" )<- bb %>% :: filter (AtBats > 0 ) %>% :: mutate (BA = Hit / AtBats,League = ifelse (team %in% central, "Central" , "Pacific" )t.test (BA ~ League, data = bb_bat)
Welch Two Sample t-test
data: BA by League
t = 0.76341, df = 308.47, p-value = 0.4458
alternative hypothesis: true difference in means between group Central and group Pacific is not equal to 0
95 percent confidence interval:
-0.007576293 0.017181859
sample estimates:
mean in group Central mean in group Pacific
0.2191978 0.2143951
12-B-4
次のデータについて、95%信頼区間を手計算(qt() と基本的な算術演算)で求め、t.test() の結果と一致することを確認しなさい。
データ: x <- c(23, 25, 28, 22, 27, 24, 26, 29, 21, 25)
模範解答
<- c (23 , 25 , 28 , 22 , 27 , 24 , 26 , 29 , 21 , 25 )<- length (x)<- mean (x)<- sd (x)<- s / sqrt (n)<- qt (0.975 , df = n - 1 )<- x_bar - t_crit * se<- x_bar + t_crit * secat (sprintf ("手計算: [%.4f, %.4f] \n " , ci_lower, ci_upper))# t.test()で確認 <- t.test (x)cat (sprintf ("t.test: [%.4f, %.4f] \n " , result$ conf.int[1 ], result$ conf.int[2 ]))
t.test: [23.1530, 26.8470]
12-B-5
irisのsetosaとversicolorの Petal.Length について、Cohen’s \(d\) を手計算で求めなさい。プールした標準偏差 \(s_p\) を使うこと。
\[
d = \frac{\bar{x}_1 - \bar{x}_2}{s_p}, \quad s_p = \sqrt{\frac{(n_1-1)s_1^2 + (n_2-1)s_2^2}{n_1 + n_2 - 2}}
\]
模範解答
<- iris %>% dplyr:: filter (Species == "setosa" ) %>% dplyr:: pull (Petal.Length)<- iris %>% dplyr:: filter (Species == "versicolor" ) %>% dplyr:: pull (Petal.Length)<- length (setosa)<- length (versicolor)<- sqrt (((n1 - 1 ) * var (setosa) + (n2 - 1 ) * var (versicolor)) / (n1 + n2 - 2 ))<- (mean (versicolor) - mean (setosa)) / spcat (sprintf ("Cohen's d = %.3f \n " , d))cat ("目安: 0.2=小, 0.5=中, 0.8=大 \n " )cat (sprintf ("この効果量は「%s」と判断できます \n " ,ifelse (abs (d) >= 0.8 , "大きい" ,ifelse (abs (d) >= 0.5 , "中程度" , "小さい" ))))
12-B-6
power.t.test() を使って、効果量 \(d = 0.3\) (小さい効果)を検出力80%で検出するために必要な1群あたりの標本サイズを求めなさい。
模範解答
power.t.test (delta = 0.3 , sd = 1 , sig.level = 0.05 , power = 0.80 ,type = "two.sample" , alternative = "two.sided" )
Two-sample t test power calculation
n = 175.3851
delta = 0.3
sd = 1
sig.level = 0.05
power = 0.8
alternative = two.sided
NOTE: n is number in *each* group
小さい効果量(\(d = 0.3\) )を検出するには、各群約175人(合計約350人)が必要です。心理学研究で小さい効果を検出するのがいかに大変かがわかります。
12-B-7
シミュレーションで第1種の誤り率を確認しなさい。母平均170、母標準偏差10の正規分布から \(n = 30\) の標本を10000回抽出し、母平均が170であるという帰無仮説を毎回検定する。p値が0.05未満になる割合を求めること。
模範解答
set.seed (42 )<- replicate (10000 , {<- rnorm (30 , mean = 170 , sd = 10 )t.test (x, mu = 170 )$ p.value# 第1種の誤り率(理論値は0.05) cat (sprintf ("第1種の誤り率: %.4f \n " , mean (p_values < 0.05 )))
帰無仮説が正しい(本当に母平均が170)にもかかわらず、約5%の確率で「有意差あり」と誤って判断してしまうことが確認できます。
12-B-8
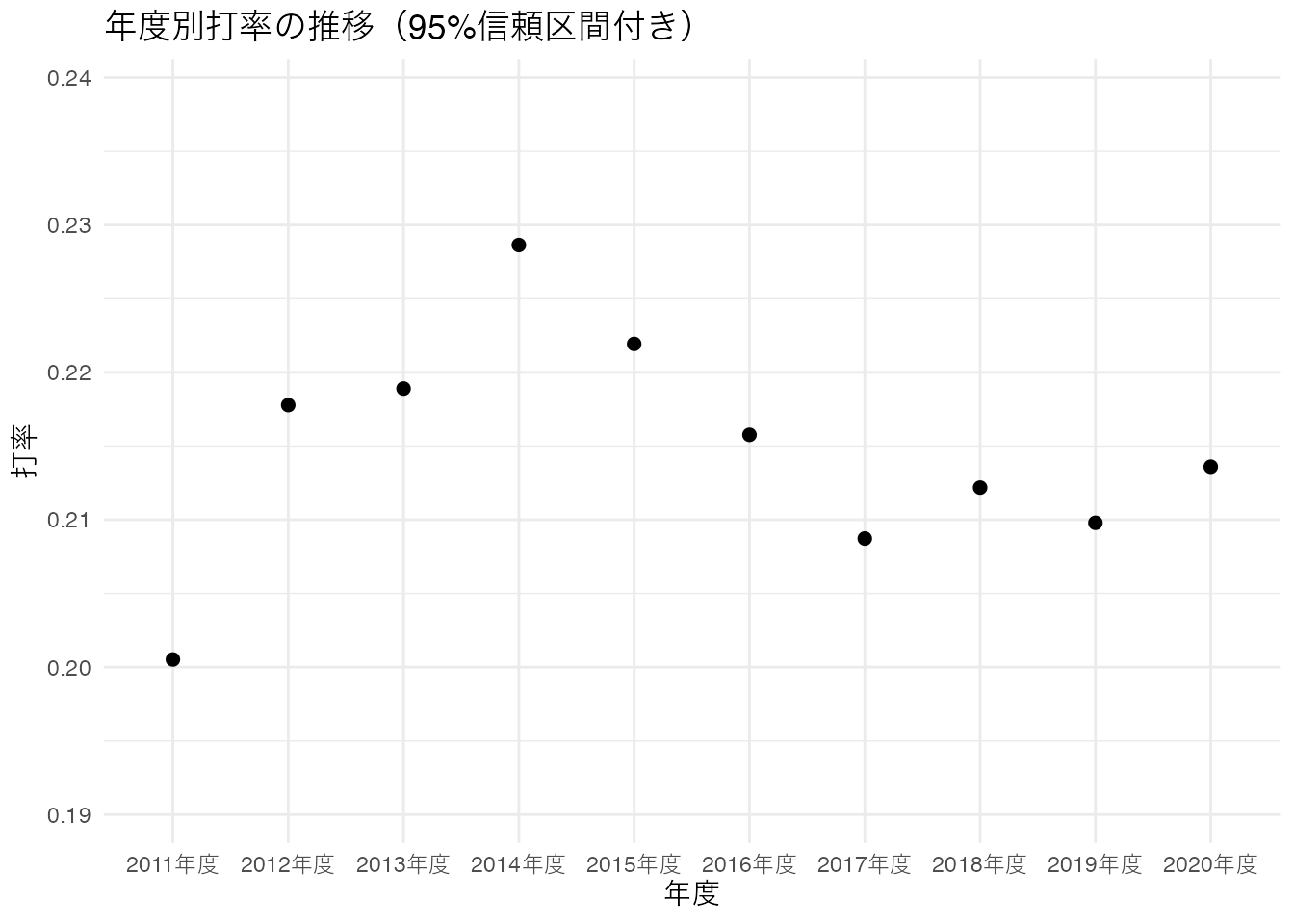
BaseballDecade.csvで、年度(Year)ごとに打率(Hit / AtBats)の平均と95%信頼区間を計算し、エラーバー付きの折れ線グラフを作成しなさい(AtBatsが0の行は除外する)。
模範解答
<- readr:: read_csv ("../data/BaseballDecade.csv" )<- bb %>% :: filter (AtBats > 0 ) %>% :: mutate (BA = Hit / AtBats) %>% :: group_by (Year) %>% :: summarise (mean_BA = mean (BA, na.rm = TRUE ),se = sd (BA, na.rm = TRUE ) / sqrt (dplyr:: n ()),ci_lower = mean_BA - qt (0.975 , dplyr:: n () - 1 ) * se,ci_upper = mean_BA + qt (0.975 , dplyr:: n () - 1 ) * se,.groups = "drop" %>% ggplot (aes (x = Year, y = mean_BA)) + geom_line (linewidth = 1 ) + geom_point (size = 2 ) + geom_ribbon (aes (ymin = ci_lower, ymax = ci_upper), alpha = 0.2 ) + labs (title = "年度別打率の推移(95%信頼区間付き)" ,x = "年度" , y = "打率" ) + theme_minimal ()
ランクA: AI協働
12-A-1
あなたが卒業研究で「SNSの利用時間と孤独感の関係」を調べるとします。先行研究から、相関係数は \(r = .20\) 程度と予想されています。
生成AIに次の内容を相談してください:
この研究で有意な結果を得るために必要な標本サイズはいくらか(検出力80%、有意水準5%)
検出力分析のRコードを書いてもらい、実行して確認する
もし標本サイズが50人しか確保できない場合、検出力はどの程度になるか
検出力を高めるためにどのような研究デザインの工夫ができるか
生成AIとのやりとりの中で、検出力分析の結果を自分でRで実行して検証 すること。AIの回答をそのまま信じるのではなく、自分で確かめることが重要です。
12-A-2
BaseballDecade.csvを使い、生成AIと協力して以下の分析レポートを作成してください:
リーグ間(セ・パ)で本塁打数(HR)に差があるかを検定する
検定の前提条件(正規性、等分散性)を確認する適切な方法をAIに相談する
前提条件が満たされない場合の代替手法(ノンパラメトリック検定など)についてAIに聞く
効果量を算出し、結果を「APA形式」で報告する文章を作成する
分析の各ステップで なぜその手法を選ぶのか をAIに質問し、理解したうえで実行してください。
まとめ
このユニットで学んだこと:
標本分布と標準誤差 : 標本平均のばらつきは \(SE = s / \sqrt{n}\) で表される信頼区間 : 母数の推定を区間で示す方法。「繰り返し作ると約95%が真の値を含む」が正しい解釈仮説検定 : 帰無仮説のもとでデータの希少性(p値)を評価し、判断する2つの誤り : 第1種の誤り(\(\alpha\) )と第2種の誤り(\(\beta\) )のトレードオフ検出力 : 真の効果を正しく検出できる確率。標本サイズと効果量に依存するt検定 : t.test() で1標本・2標本(対応あり/なし)の検定が実行できる
次のU13(回帰モデル)では、2変数間の関係をモデル化する方法を学びます。