ユニット概要
| 分類 |
幹(全員必須) |
| 前提 |
U12(統計的推測の基礎) |
| 次のユニット |
なし(幹ユニットの終点) |
| 使用データ |
BaseballDecade.csv, iris |
| 学習目標 |
回帰分析の考え方と最小二乗法を理解する / 単回帰・重回帰をRで実行し結果を解釈できる / モデルの診断と仮定の確認ができる / モデル選択の基準(AIC等)を理解する |
事前知識
回帰分析とは
回帰分析(regression analysis) は、ある変数(目的変数 / 従属変数)を他の変数(説明変数 / 独立変数)で予測・説明するための統計手法です。
例えば、「身長から体重を予測できるか?」「練習時間とテストの点数に関係はあるか?」といった問いに答えるために使います。
単回帰モデル
説明変数が1つの場合を 単回帰(simple regression) と呼びます。
\[
y_i = \beta_0 + \beta_1 x_i + e_i
\]
- \(y_i\): 目的変数(\(i\) 番目の観測値)
- \(x_i\): 説明変数
- \(\beta_0\): 切片(intercept)。\(x = 0\) のときの \(y\) の期待値
- \(\beta_1\): 傾き(slope)。\(x\) が1単位増えたとき \(y\) がどれだけ変化するか
- \(e_i\): 残差(誤差項)。モデルで説明できないばらつき
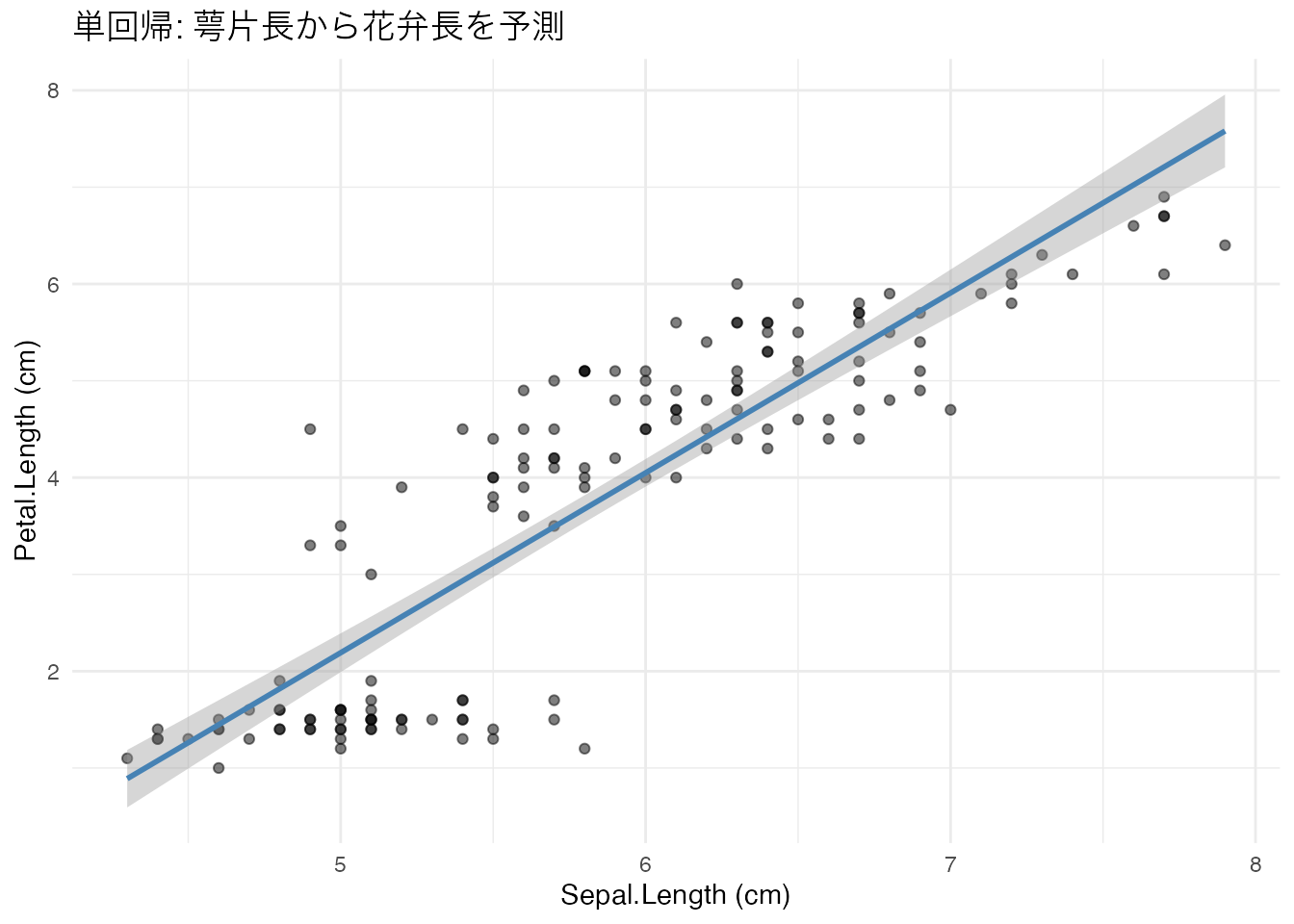
# 単回帰の例: irisのSepal.LengthからPetal.Lengthを予測
model_simple <- lm(Petal.Length ~ Sepal.Length, data = iris)
summary(model_simple)
Call:
lm(formula = Petal.Length ~ Sepal.Length, data = iris)
Residuals:
Min 1Q Median 3Q Max
-2.47747 -0.59072 -0.00668 0.60484 2.49512
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -7.10144 0.50666 -14.02 <2e-16 ***
Sepal.Length 1.85843 0.08586 21.65 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.8678 on 148 degrees of freedom
Multiple R-squared: 0.76, Adjusted R-squared: 0.7583
F-statistic: 468.6 on 1 and 148 DF, p-value: < 2.2e-16
出力の読み方:
Coefficients: 回帰係数の推定値、標準誤差、t値、p値(Intercept): 切片 \(\hat{\beta}_0\)Sepal.Length: 傾き \(\hat{\beta}_1\)(萼片長が1cm増えると花弁長が約1.86cm増える)Multiple R-squared: 決定係数 \(R^2\)(モデルがデータの変動をどれだけ説明しているか)F-statistic: モデル全体の有意性検定
# 回帰直線の可視化
iris %>%
ggplot(aes(x = Sepal.Length, y = Petal.Length)) +
geom_point(alpha = 0.5) +
geom_smooth(method = "lm", se = TRUE, color = "steelblue") +
labs(title = "単回帰: 萼片長から花弁長を予測",
x = "Sepal.Length (cm)", y = "Petal.Length (cm)") +
theme_minimal()
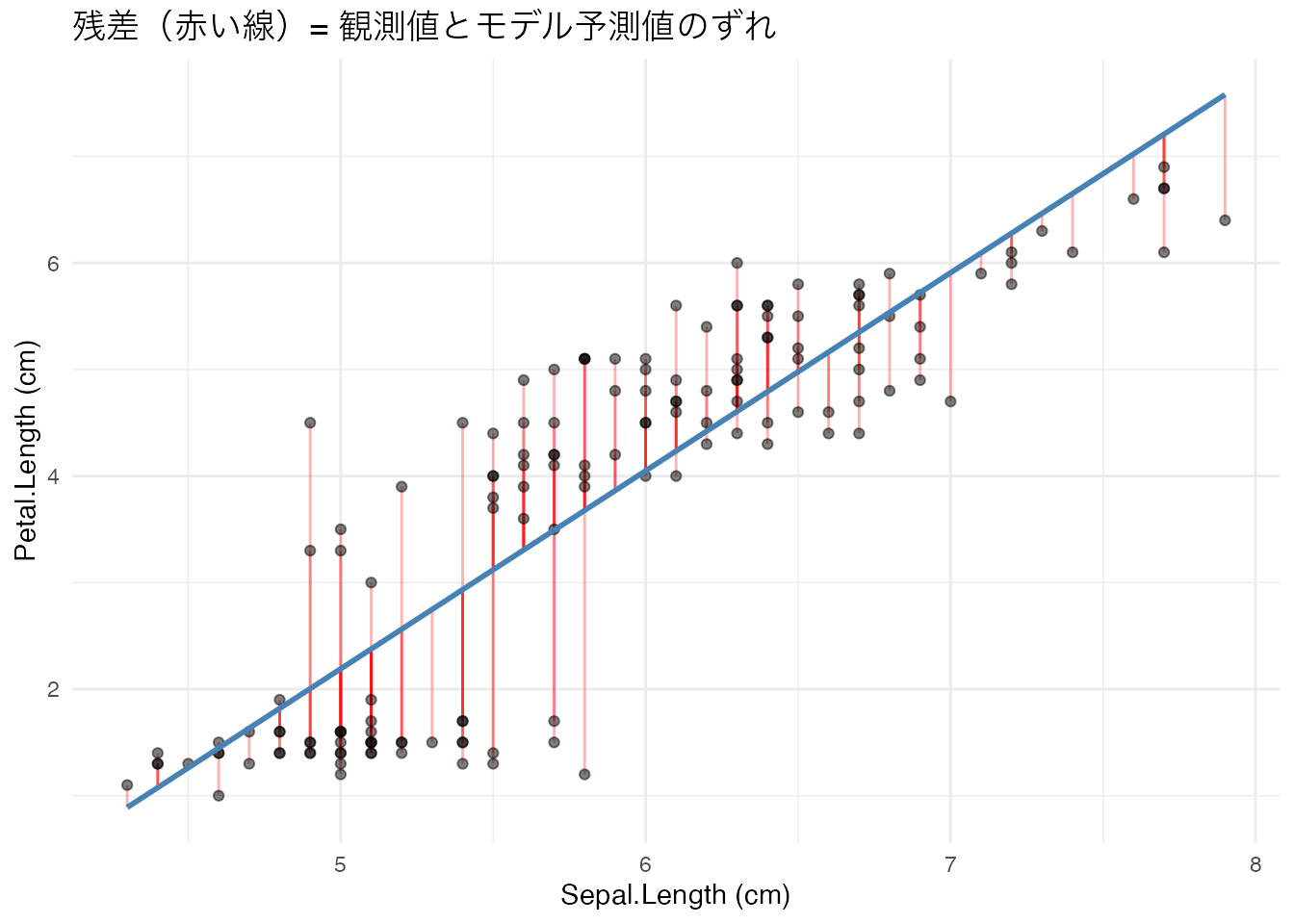
最小二乗法
回帰係数は 最小二乗法(OLS: Ordinary Least Squares) で推定されます。残差の二乗和を最小にする \(\beta_0, \beta_1\) を見つけます。
\[
\min_{\beta_0, \beta_1} \sum_{i=1}^{n} (y_i - \beta_0 - \beta_1 x_i)^2
\]
# 残差の可視化
iris_pred <- iris %>%
dplyr::mutate(
predicted = predict(model_simple),
residual = Petal.Length - predicted
)
iris_pred %>%
ggplot(aes(x = Sepal.Length, y = Petal.Length)) +
geom_segment(aes(xend = Sepal.Length, yend = predicted),
color = "red", alpha = 0.3) +
geom_point(alpha = 0.5) +
geom_line(aes(y = predicted), color = "steelblue", linewidth = 1) +
labs(title = "残差(赤い線)= 観測値とモデル予測値のずれ",
x = "Sepal.Length (cm)", y = "Petal.Length (cm)") +
theme_minimal()
重回帰モデル
説明変数が複数の場合を 重回帰(multiple regression) と呼びます。
\[
y_i = \beta_0 + \beta_1 x_{i1} + \beta_2 x_{i2} + \cdots + \beta_p x_{ip} + e_i
\]
重回帰の係数は 偏回帰係数(partial regression coefficient) と呼ばれ、「他の説明変数を一定にしたとき」の効果を表します。
# 重回帰の例
model_multi <- lm(Petal.Length ~ Sepal.Length + Sepal.Width, data = iris)
summary(model_multi)
Call:
lm(formula = Petal.Length ~ Sepal.Length + Sepal.Width, data = iris)
Residuals:
Min 1Q Median 3Q Max
-1.25582 -0.46922 -0.05741 0.45530 1.75599
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -2.52476 0.56344 -4.481 1.48e-05 ***
Sepal.Length 1.77559 0.06441 27.569 < 2e-16 ***
Sepal.Width -1.33862 0.12236 -10.940 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.6465 on 147 degrees of freedom
Multiple R-squared: 0.8677, Adjusted R-squared: 0.8659
F-statistic: 482 on 2 and 147 DF, p-value: < 2.2e-16
決定係数 \(R^2\) と自由度調整済み \(R^2\)
- \(R^2\)(決定係数): モデルが目的変数の変動をどれだけ説明しているか(0〜1)
- 調整済み \(R^2\): 説明変数を増やすだけで \(R^2\) が上がる問題を補正したもの
\[
R^2 = 1 - \frac{\sum(y_i - \hat{y}_i)^2}{\sum(y_i - \bar{y})^2}
\]
説明変数を増やせば \(R^2\) は必ず上がりますが、それがモデルの改善かどうかは別問題です。調整済み \(R^2\) やAIC/BICで判断します。
モデルの診断
回帰分析にはいくつかの 仮定 があります。結果を信頼するには、これらを確認する必要があります。
- 残差の正規性: 残差が正規分布に従う
- 等分散性: 残差の分散が一定(予測値に依存しない)
- 独立性: 残差同士が独立
- 多重共線性がない: 説明変数間の相関が強すぎない
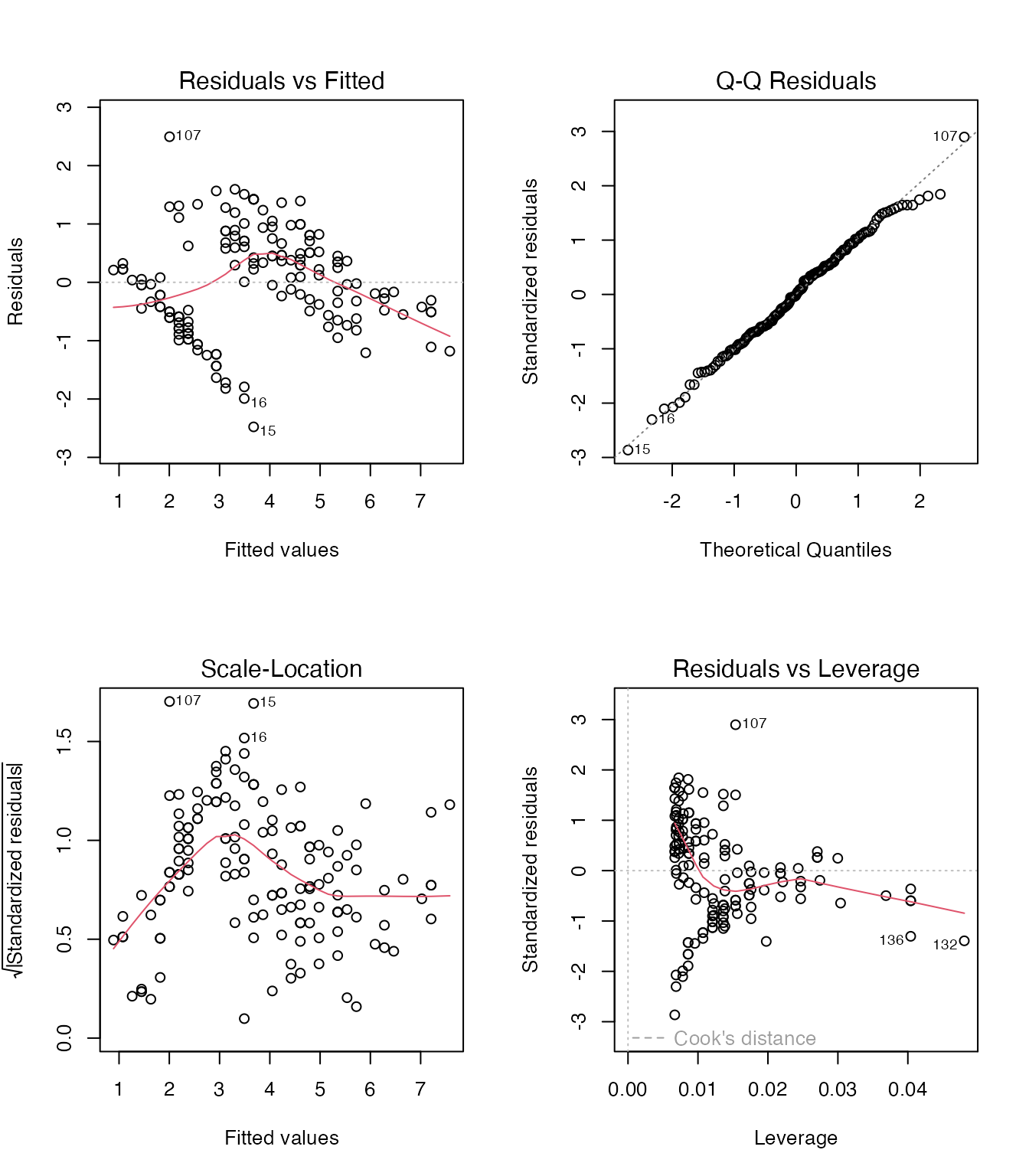
# 診断プロット(4枚)
par(mfrow = c(2, 2))
plot(model_simple)
- 左上(Residuals vs Fitted): 残差と予測値の関係。パターンがなければOK
- 右上(Q-Q plot): 残差の正規性。点が直線に乗っていればOK
- 左下(Scale-Location): 等分散性の確認。水平な帯状ならOK
- 右下(Residuals vs Leverage): 影響力の大きい外れ値の検出
モデル選択: AIC と BIC
複数のモデルを比較するとき、AIC(赤池情報量規準) や BIC(ベイズ情報量規準) を使います。
- AIC: \(-2 \ln L + 2k\)(\(L\): 尤度、\(k\): パラメータ数)
- BIC: \(-2 \ln L + k \ln n\)(BICはAICよりパラメータ数へのペナルティが大きい)
いずれも 値が小さいほど良いモデル です。
# 2つのモデルのAIC比較
model1 <- lm(Petal.Length ~ Sepal.Length, data = iris)
model2 <- lm(Petal.Length ~ Sepal.Length + Sepal.Width, data = iris)
model3 <- lm(Petal.Length ~ Sepal.Length + Sepal.Width + Species, data = iris)
AIC(model1, model2, model3)
df AIC
model1 3 387.13500
model2 4 299.78749
model3 6 54.21552
一般線型モデルとしての統一
実は、U12で学んだt検定や分散分析も 回帰分析の特殊なケース です。
- 1標本t検定: \(y_i = \beta_0 + e_i\)(切片のみモデル)で \(\beta_0 = \mu_0\) を検定
- 対応のないt検定: \(y_i = \beta_0 + \beta_1 x_i + e_i\) で \(x\) はグループを示すダミー変数
# t検定と回帰分析は同じ結果を返す
iris_sub <- iris %>% dplyr::filter(Species %in% c("setosa", "versicolor"))
# t検定
t_result <- t.test(Petal.Length ~ Species, data = iris_sub, var.equal = TRUE)
# 回帰分析
lm_result <- lm(Petal.Length ~ Species, data = iris_sub)
cat(sprintf("t検定のt値: %.4f\n", t_result$statistic))
cat(sprintf("回帰分析のt値: %.4f\n", summary(lm_result)$coefficients[2, 3]))
t値の絶対値が一致することを確認してください(符号は群の順序で反転する場合があります)。
ランクC: 基礎知識
13-C-1
回帰分析において、\(y = \beta_0 + \beta_1 x + e\) の \(e\) は何を表すか。
13-C-2
単回帰で傾き \(\beta_1 = 2.5\) のとき、\(x\) が1単位増えると \(y\) はどうなるか。
13-C-3
Rで回帰分析を行う関数は lm() である。
13-C-4
決定係数 \(R^2 = 0.75\) のとき、モデルは目的変数の変動の75%を説明している。
13-C-5
重回帰分析の偏回帰係数は、「他の説明変数を一定にしたとき」の効果を表す。
13-C-6
説明変数を増やすと \(R^2\) はどうなるか。
13-C-7
AICによるモデル選択では、AICの値がどちらのモデルを選ぶべきか。
13-C-8
summary(lm_result) の出力に含まれる Pr(>|t|) は何を表すか。
13-C-9
回帰分析の仮定として「残差の正規性」がある。これを確認するのに適したプロットはどれか。
13-C-10
t検定は回帰分析の特殊なケースとみなすことができる。
ランクB: 実践スキル
13-B-1
irisデータで、Sepal.Length を説明変数、Petal.Length を目的変数とする単回帰分析を行い、summary() で結果を確認しなさい。傾きの推定値とp値を読み取ること。
model <- lm(Petal.Length ~ Sepal.Length, data = iris)
summary(model)
Call:
lm(formula = Petal.Length ~ Sepal.Length, data = iris)
Residuals:
Min 1Q Median 3Q Max
-2.47747 -0.59072 -0.00668 0.60484 2.49512
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -7.10144 0.50666 -14.02 <2e-16 ***
Sepal.Length 1.85843 0.08586 21.65 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.8678 on 148 degrees of freedom
Multiple R-squared: 0.76, Adjusted R-squared: 0.7583
F-statistic: 468.6 on 1 and 148 DF, p-value: < 2.2e-16
- 傾き(Sepal.Length): 約1.86(p < .001)
- 萼片長が1cm長いと、花弁長は約1.86cm長い
- \(R^2\) = 0.76: モデルは変動の約76%を説明
13-B-2
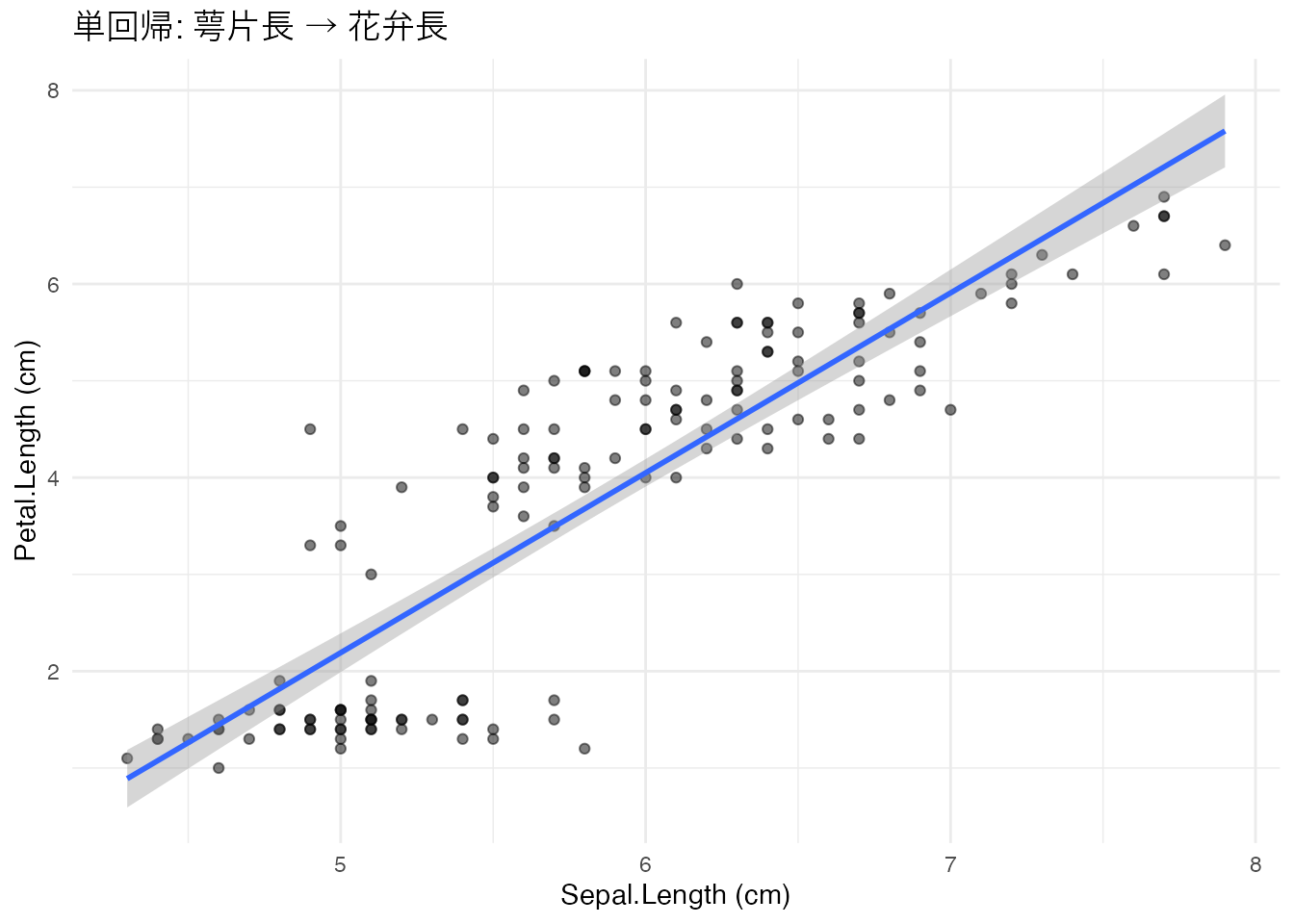
上の単回帰モデルの結果を散布図と回帰直線で可視化しなさい。geom_smooth(method = "lm") を使うこと。
iris %>%
ggplot(aes(x = Sepal.Length, y = Petal.Length)) +
geom_point(alpha = 0.5) +
geom_smooth(method = "lm", se = TRUE) +
labs(x = "Sepal.Length (cm)", y = "Petal.Length (cm)",
title = "単回帰: 萼片長 → 花弁長") +
theme_minimal()
13-B-3
irisデータで、Sepal.Length、Sepal.Width、Petal.Width の3変数を説明変数、Petal.Length を目的変数とする重回帰分析を行いなさい。どの変数が有意か確認すること。
model_multi <- lm(Petal.Length ~ Sepal.Length + Sepal.Width + Petal.Width,
data = iris)
summary(model_multi)
Call:
lm(formula = Petal.Length ~ Sepal.Length + Sepal.Width + Petal.Width,
data = iris)
Residuals:
Min 1Q Median 3Q Max
-0.99333 -0.17656 -0.01004 0.18558 1.06909
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.26271 0.29741 -0.883 0.379
Sepal.Length 0.72914 0.05832 12.502 <2e-16 ***
Sepal.Width -0.64601 0.06850 -9.431 <2e-16 ***
Petal.Width 1.44679 0.06761 21.399 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.319 on 146 degrees of freedom
Multiple R-squared: 0.968, Adjusted R-squared: 0.9674
F-statistic: 1473 on 3 and 146 DF, p-value: < 2.2e-16
3変数すべてが有意(p < .05)であり、調整済み \(R^2\) は約0.97と非常に高いことがわかります。
13-B-4
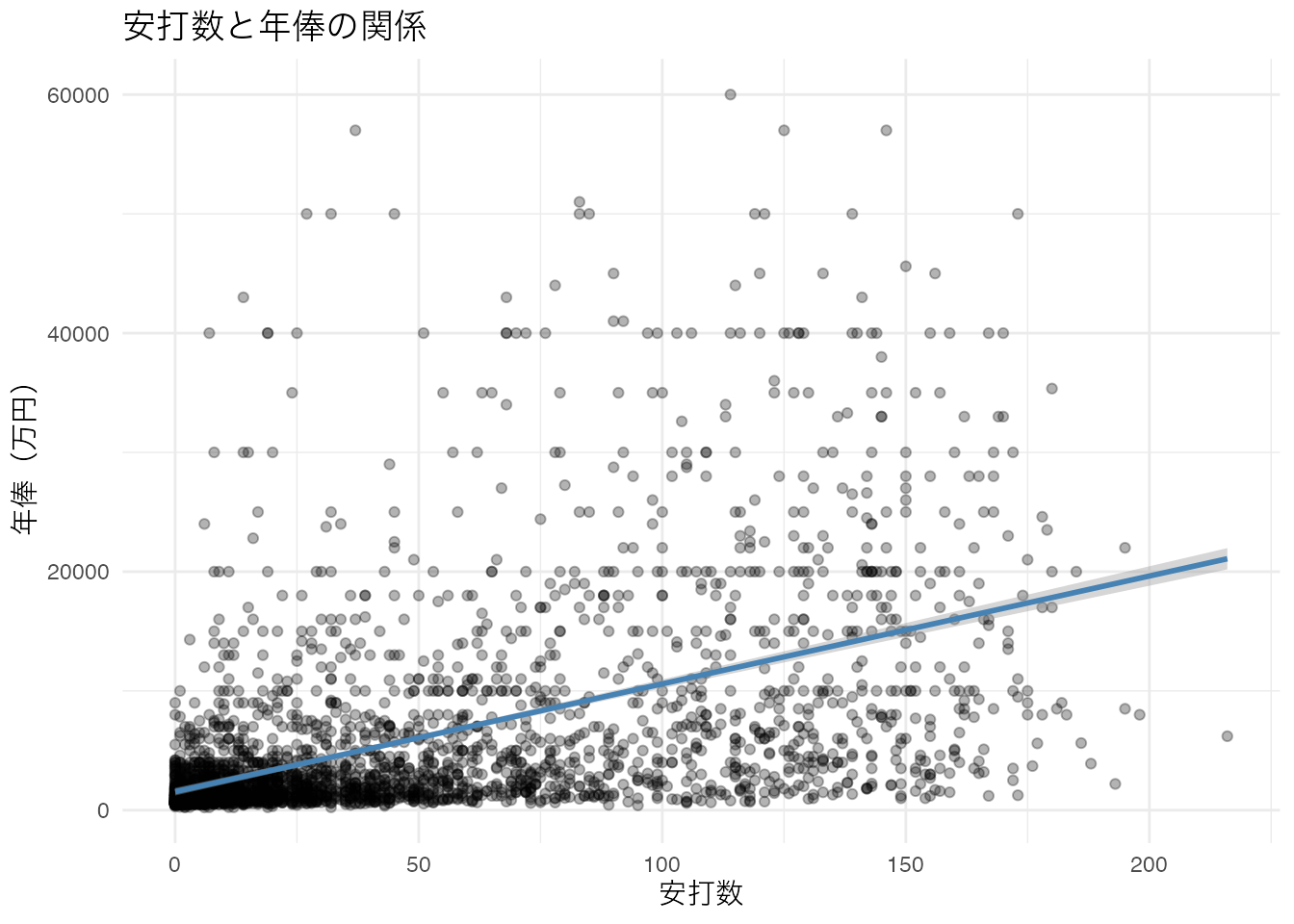
BaseballDecade.csvを読み込み、野手(AtBats > 0)のデータで salary(年俸)を目的変数、Hit(安打数)を説明変数とする単回帰分析を行いなさい。
bb <- readr::read_csv("../data/BaseballDecade.csv")
bb_bat <- bb %>% dplyr::filter(AtBats > 0)
model_bb <- lm(salary ~ Hit, data = bb_bat)
summary(model_bb)
Call:
lm(formula = salary ~ Hit, data = bb_bat)
Residuals:
Min 1Q Median 3Q Max
-16800 -2651 -993 456 52105
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 1549.487 165.136 9.383 <2e-16 ***
Hit 90.418 2.536 35.659 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 7031 on 3250 degrees of freedom
Multiple R-squared: 0.2812, Adjusted R-squared: 0.281
F-statistic: 1272 on 1 and 3250 DF, p-value: < 2.2e-16
bb_bat %>%
ggplot(aes(x = Hit, y = salary)) +
geom_point(alpha = 0.3) +
geom_smooth(method = "lm", se = TRUE, color = "steelblue") +
labs(title = "安打数と年俸の関係",
x = "安打数", y = "年俸(万円)") +
theme_minimal()
13-B-5
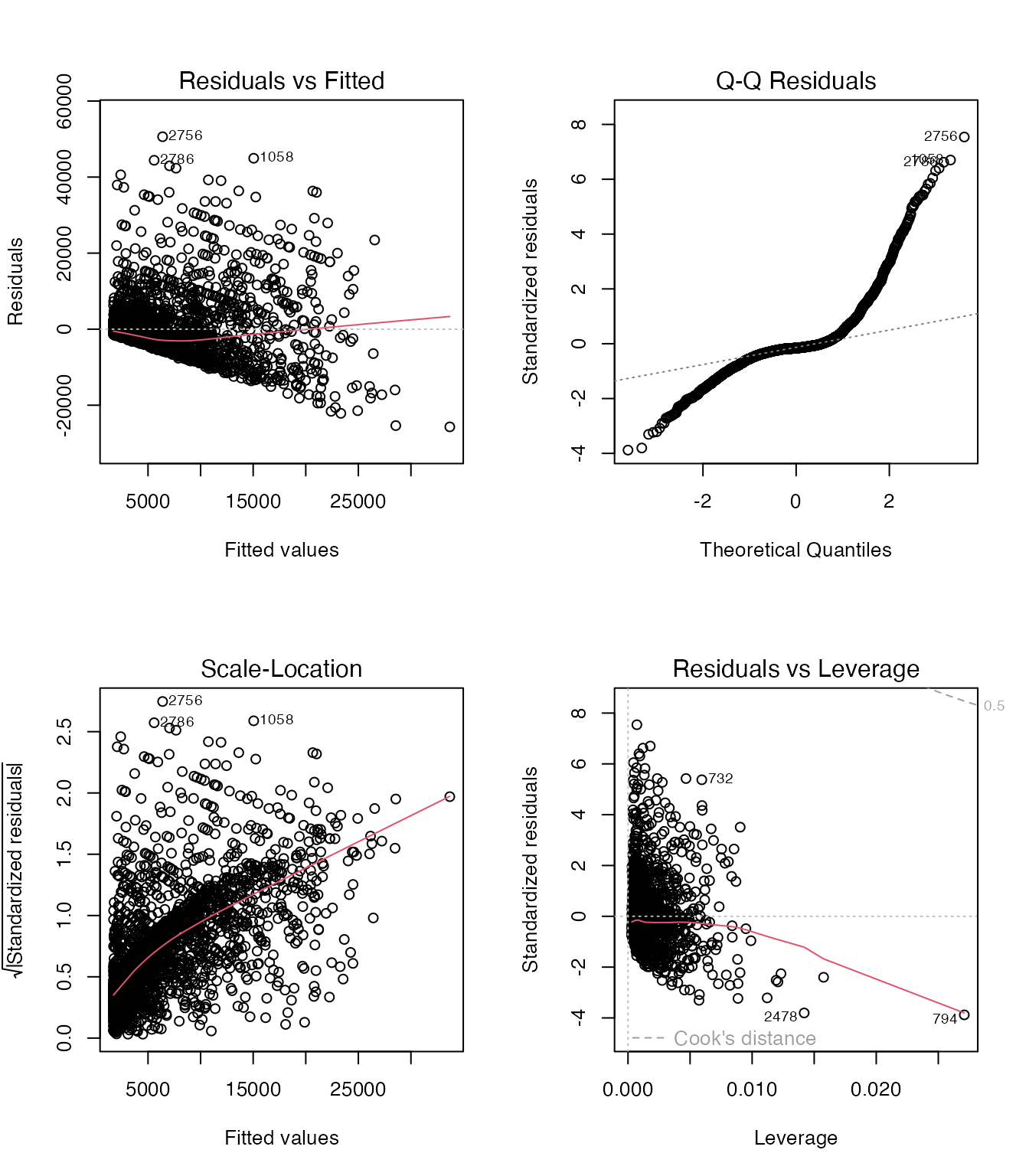
BaseballDecade.csvの野手データで、salary を目的変数に、Hit、HR、Games を説明変数とする重回帰モデルを作成し、plot() で4枚の診断プロットを描きなさい。残差の正規性や等分散性について気づいたことを述べること。
bb_bat <- bb %>%
dplyr::filter(AtBats > 0) %>%
tidyr::drop_na(Hit, HR, Games, salary)
model_bb2 <- lm(salary ~ Hit + HR + Games, data = bb_bat)
par(mfrow = c(2, 2))
plot(model_bb2)
- Residuals vs Fitted: 右に行くほど残差が広がる傾向(等分散性の仮定が怪しい)
- Q-Qプロット: 右端が直線から外れている(右裾が重い=高年俸の外れ値)
- 年俸データは正の歪みが強いため、対数変換
log(salary) の使用を検討すべきです
13-B-6
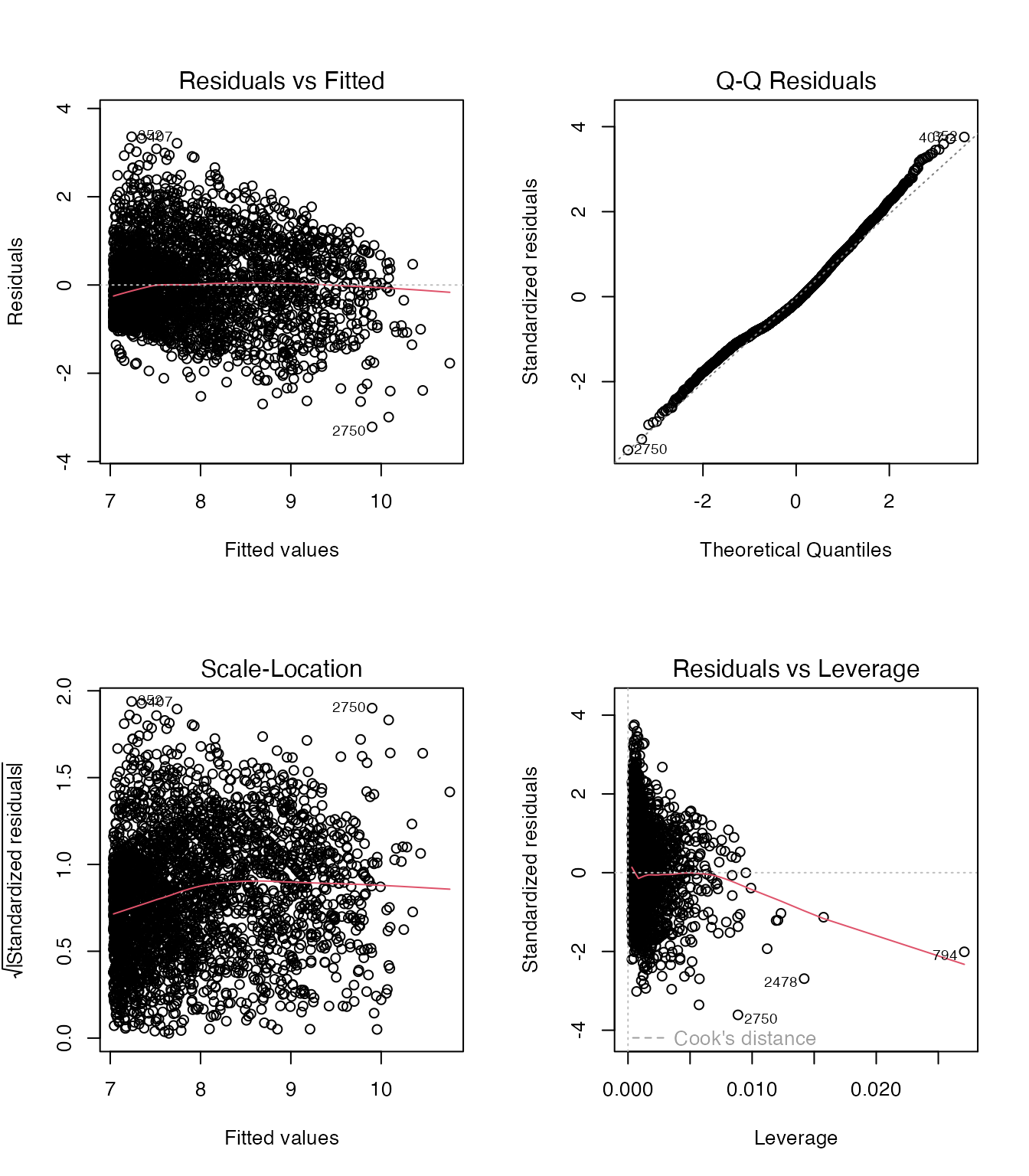
13-B-5の問題点を踏まえて、目的変数を log(salary) に変換した重回帰モデルを作成し、診断プロットが改善されるか確認しなさい。
model_log <- lm(log(salary) ~ Hit + HR + Games, data = bb_bat)
summary(model_log)
Call:
lm(formula = log(salary) ~ Hit + HR + Games, data = bb_bat)
Residuals:
Min 1Q Median 3Q Max
-3.2153 -0.6330 -0.1252 0.5653 3.3598
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) 7.0290265 0.0292642 240.192 < 2e-16 ***
Hit 0.0057678 0.0008598 6.708 2.32e-11 ***
HR 0.0331324 0.0031632 10.474 < 2e-16 ***
Games 0.0069757 0.0008233 8.473 < 2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.8946 on 3248 degrees of freedom
Multiple R-squared: 0.4217, Adjusted R-squared: 0.4211
F-statistic: 789.3 on 3 and 3248 DF, p-value: < 2.2e-16
par(mfrow = c(2, 2))
plot(model_log)
対数変換により残差の分布が改善されます。年俸のような右に裾が長い変数では、対数変換が有効な場合が多いです。
13-B-7
irisデータで以下の3つのモデルを作成し、AIC() で比較しなさい。どのモデルが最も良いか。
- モデル1:
Petal.Length ~ Sepal.Length
- モデル2:
Petal.Length ~ Sepal.Length + Sepal.Width
- モデル3:
Petal.Length ~ Sepal.Length + Sepal.Width + Petal.Width
m1 <- lm(Petal.Length ~ Sepal.Length, data = iris)
m2 <- lm(Petal.Length ~ Sepal.Length + Sepal.Width, data = iris)
m3 <- lm(Petal.Length ~ Sepal.Length + Sepal.Width + Petal.Width, data = iris)
AIC(m1, m2, m3)
df AIC
m1 3 387.13500
m2 4 299.78749
m3 5 88.81602
df BIC
m1 3 396.1669
m2 4 311.8300
m3 5 103.8692
AIC・BICともにモデル3が最小であり、3変数モデルが最も良いと判断できます。
13-B-8
step() 関数を使って、irisデータの Petal.Length を目的変数とするモデルの変数選択を自動で行いなさい。フルモデル(全変数)から出発して後退法(backward)で選択すること。
full_model <- lm(Petal.Length ~ Sepal.Length + Sepal.Width + Petal.Width,
data = iris)
best_model <- step(full_model, direction = "backward", trace = 1)
Start: AIC=-338.87
Petal.Length ~ Sepal.Length + Sepal.Width + Petal.Width
Df Sum of Sq RSS AIC
<none> 14.853 -338.87
- Sepal.Width 1 9.049 23.902 -269.50
- Sepal.Length 1 15.902 30.755 -231.69
- Petal.Width 1 46.584 61.437 -127.89
Call:
lm(formula = Petal.Length ~ Sepal.Length + Sepal.Width + Petal.Width,
data = iris)
Residuals:
Min 1Q Median 3Q Max
-0.99333 -0.17656 -0.01004 0.18558 1.06909
Coefficients:
Estimate Std. Error t value Pr(>|t|)
(Intercept) -0.26271 0.29741 -0.883 0.379
Sepal.Length 0.72914 0.05832 12.502 <2e-16 ***
Sepal.Width -0.64601 0.06850 -9.431 <2e-16 ***
Petal.Width 1.44679 0.06761 21.399 <2e-16 ***
---
Signif. codes: 0 '***' 0.001 '**' 0.01 '*' 0.05 '.' 0.1 ' ' 1
Residual standard error: 0.319 on 146 degrees of freedom
Multiple R-squared: 0.968, Adjusted R-squared: 0.9674
F-statistic: 1473 on 3 and 146 DF, p-value: < 2.2e-16
step() はAICを基準にして変数を1つずつ除外し、AICが最小になるモデルを選択します。trace = 1 で選択過程が表示されます。
13-B-9
回帰モデルで予測を行いなさい。irisの単回帰モデル(Petal.Length ~ Sepal.Length)を使い、Sepal.Length が 5.0, 6.0, 7.0 のときの Petal.Length の予測値と95%予測区間を求めること。
model <- lm(Petal.Length ~ Sepal.Length, data = iris)
new_data <- tibble(Sepal.Length = c(5.0, 6.0, 7.0))
predictions <- predict(model, newdata = new_data, interval = "prediction")
cbind(new_data, predictions)
Sepal.Length fit lwr upr
1 5 2.190722 0.4641676 3.917275
2 6 4.049154 2.3283341 5.769975
3 7 5.907587 4.1758176 7.639357
fit: 予測値(点推定)lwr, upr: 95%予測区間(個々の新しい観測値がこの範囲に入ると期待される)
13-B-10
irisの setosa と versicolor について、Petal.Length の群間比較を回帰分析で行い、t.test(var.equal = TRUE) の結果と比較しなさい。t値が一致する(符号が逆の場合もある)ことを確認すること。
iris_sub <- iris %>% dplyr::filter(Species %in% c("setosa", "versicolor"))
# t検定
t_result <- t.test(Petal.Length ~ Species, data = iris_sub, var.equal = TRUE)
# 回帰分析
lm_result <- lm(Petal.Length ~ Species, data = iris_sub)
cat("--- t検定 ---\n")
cat(sprintf("t値: %.4f, p値: %.6f\n", t_result$statistic, t_result$p.value))
t値: -39.4927, p値: 0.000000
cat(sprintf("t値: %.4f, p値: %.6f\n",
summary(lm_result)$coefficients[2, 3],
summary(lm_result)$coefficients[2, 4]))
t値: 39.4927, p値: 0.000000
t検定と回帰分析が本質的に同じ分析であることが確認できます。
ランクA: AI協働
13-A-1
BaseballDecade.csvの野手データを使い、生成AIと協力して「年俸を予測する最良のモデル」を構築してください。
以下の手順で進めること:
- どの変数を説明変数の候補にすべきかAIに相談する
- モデルを複数作成し、AIC/BICで比較する
- 診断プロットを見せてAIに「このモデルの問題点は何か」を聞く
- 問題があれば変数変換や交互作用項の追加などの改善策をAIに提案してもらう
- 最終的なモデルの結果を解釈し、「安打数が10本増えると年俸はどの程度変わるか」のような具体的な予測を行う
AIの提案を 必ず自分で実行して確認 すること。
13-A-2
生成AIに「回帰分析の仮定が満たされないとき、どのような代替手法があるか」を聞いてください。以下の状況それぞれについて、AIの提案する手法をRで実際に試してみましょう:
- 目的変数と説明変数の関係が直線ではない場合
- 目的変数が0/1の二値変数の場合(ロジスティック回帰)
- 外れ値の影響が大きい場合
AIとの対話で学んだことを、3つの場面ごとに要約してください。
まとめ
このユニットで学んだこと:
- 回帰分析の基本: \(y = \beta_0 + \beta_1 x + e\) で変数間の関係をモデル化する
- 最小二乗法: 残差の二乗和を最小化して係数を推定する
- 重回帰: 複数の説明変数を使い、偏回帰係数で各変数の「独自の効果」を評価する
- 決定係数 \(R^2\): モデルの説明力の指標。ただし変数を増やせば必ず上がるため、調整済み \(R^2\) やAICで判断する
- モデル診断: 残差の正規性、等分散性、多重共線性を確認する
- モデル選択: AIC/BICや
step() で最適なモデルを選ぶ
- 一般線型モデル: t検定や分散分析は回帰分析の特殊なケース
これで幹ユニット(U1〜U13)は完了です。ここまでの知識があれば、データの読み込みから分析・可視化・推測まで一通りの流れを自力で行えるはずです。枝ユニット(U3, U14〜U19, U21〜U23)に進んで、さらに専門的なスキルを身につけましょう。